 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAREAL-DTA: Dynamic Tree Attention for Efficient Reinforcement Learning of Large Language Models
Jan 31, 2026Reinforcement learning (RL) based post-training for large language models (LLMs) is computationally expensive, as it generates many rollout sequences that could frequently share long token prefixes. Existing RL frameworks usually process these sequences independently, repeatedly recomputing identical prefixes during forward and backward passes during policy model training, leading to substantial inefficiencies in computation and memory usage. Although prefix sharing naturally induces a tree structure over rollouts, prior tree-attention-based solutions rely on fully materialized attention masks and scale poorly in RL settings. In this paper, we introduce AREAL-DTA to efficiently exploit prefix sharing in RL training. AREAL-DTA employs a depth-first-search (DFS)-based execution strategy that dynamically traverses the rollout prefix tree during both forward and backward computation, materializing only a single root-to-leaf path at a time. To further improve scalability, AREAL-DTA incorporates a load-balanced distributed batching mechanism that dynamically constructs and processes prefix trees across multiple GPUs. Across the popular RL post-training workload, AREAL-DTA achieves up to $8.31\times$ in $τ^2$-bench higher training throughput.
Two-way Evidence self-Alignment based Dual-Gated Reasoning Enhancement
May 22, 2025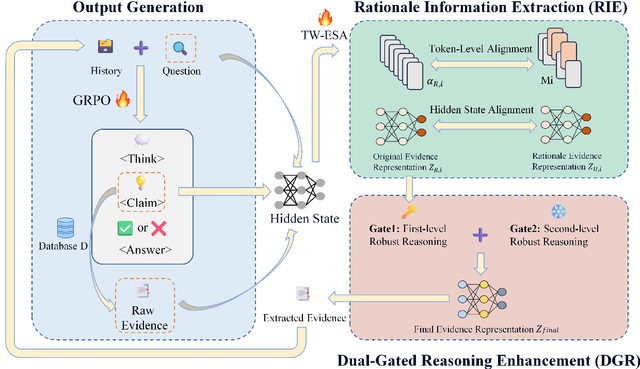
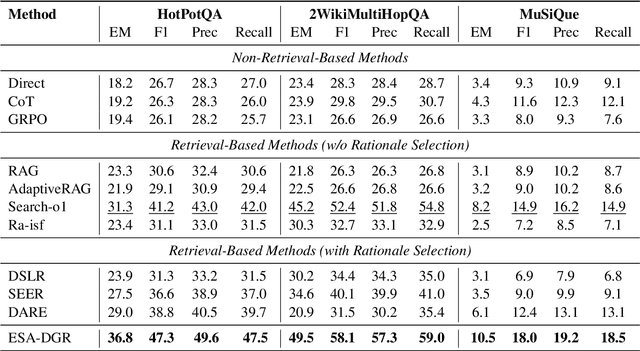
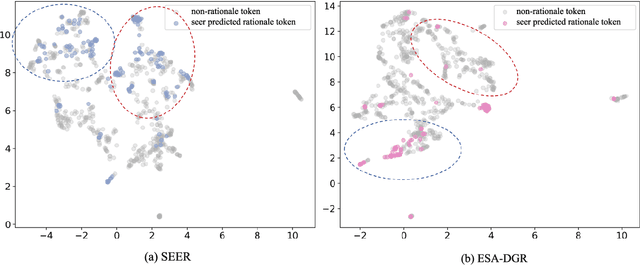
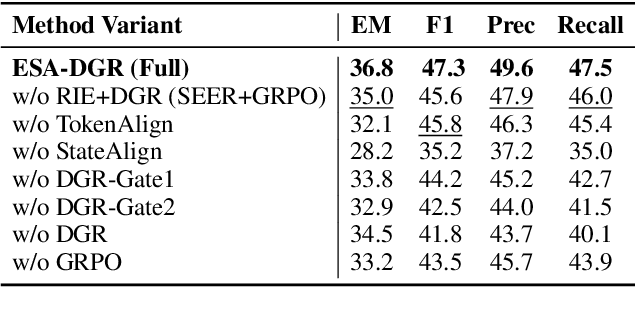
Large language models (LLMs) encounter difficulties in knowledge-intensive multi-step reasoning (KIMSR) tasks. One challenge is how to effectively extract and represent rationale evidence. The current methods often extract semantically relevant but logically irrelevant evidence, resulting in flawed reasoning and inaccurate responses. We propose a two-way evidence self-alignment (TW-ESA) module, which utilizes the mutual alignment between strict reasoning and LLM reasoning to enhance its understanding of the causal logic of evidence, thereby addressing the first challenge. Another challenge is how to utilize the rationale evidence and LLM's intrinsic knowledge for accurate reasoning when the evidence contains uncertainty. We propose a dual-gated reasoning enhancement (DGR) module to gradually fuse useful knowledge of LLM within strict reasoning, which can enable the model to perform accurate reasoning by focusing on causal elements in the evidence and exhibit greater robustness. The two modules are collaboratively trained in a unified framework ESA-DGR. Extensive experiments on three diverse and challenging KIMSR datasets reveal that ESA-DGR significantly surpasses state-of-the-art LLM-based fine-tuning methods, with remarkable average improvements of 4% in exact match (EM) and 5% in F1 score. The implementation code is available at https://anonymous.4open.science/r/ESA-DGR-2BF8.
Can Competition Enhance the Proficiency of Agents Powered by Large Language Models in the Realm of News-driven Time Series Forecasting?
Apr 14, 2025Multi-agents-based news-driven time series forecasting is considered as a potential paradigm shift in the era of large language models (LLMs). The challenge of this task lies in measuring the influences of different news events towards the fluctuations of time series. This requires agents to possess stronger abilities of innovative thinking and the identifying misleading logic. However, the existing multi-agent discussion framework has limited enhancement on time series prediction in terms of optimizing these two capabilities. Inspired by the role of competition in fostering innovation, this study embeds a competition mechanism within the multi-agent discussion to enhance agents' capability of generating innovative thoughts. Furthermore, to bolster the model's proficiency in identifying misleading information, we incorporate a fine-tuned small-scale LLM model within the reflective stage, offering auxiliary decision-making support. Experimental results confirm that the competition can boost agents' capacity for innovative thinking, which can significantly improve the performances of time series prediction. Similar to the findings of social science, the intensity of competition within this framework can influence the performances of agents, providing a new perspective for studying LLMs-based multi-agent systems.
Structuring Scientific Innovation: A Framework for Modeling and Discovering Impactful Knowledge Combinations
Mar 25, 2025The emergence of large language models offers new possibilities for structured exploration of scientific knowledge. Rather than viewing scientific discovery as isolated ideas or content, we propose a structured approach that emphasizes the role of method combinations in shaping disruptive insights. Specifically, we investigate how knowledge unit--especially those tied to methodological design--can be modeled and recombined to yield research breakthroughs. Our proposed framework addresses two key challenges. First, we introduce a contrastive learning-based mechanism to identify distinguishing features of historically disruptive method combinations within problem-driven contexts. Second, we propose a reasoning-guided Monte Carlo search algorithm that leverages the chain-of-thought capability of LLMs to identify promising knowledge recombinations for new problem statements.Empirical studies across multiple domains show that the framework is capable of modeling the structural dynamics of innovation and successfully highlights combinations with high disruptive potential. This research provides a new path for computationally guided scientific ideation grounded in structured reasoning and historical data modeling.
A Large Language Model-based Framework for Semi-Structured Tender Document Retrieval-Augmented Generation
Oct 04, 2024



The drafting of documents in the procurement field has progressively become more complex and diverse, driven by the need to meet legal requirements, adapt to technological advancements, and address stakeholder demands. While large language models (LLMs) show potential in document generation, most LLMs lack specialized knowledge in procurement. To address this gap, we use retrieval-augmented techniques to achieve professional document generation, ensuring accuracy and relevance in procurement documentation.
Mirror Gradient: Towards Robust Multimodal Recommender Systems via Exploring Flat Local Minima
Feb 17, 2024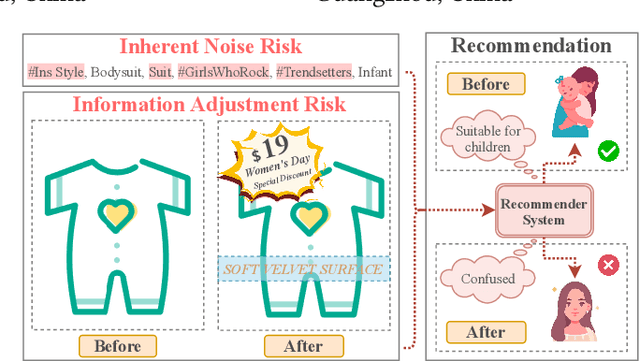
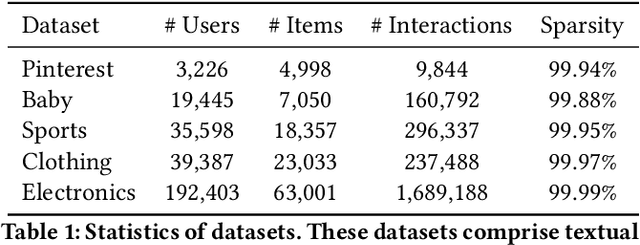
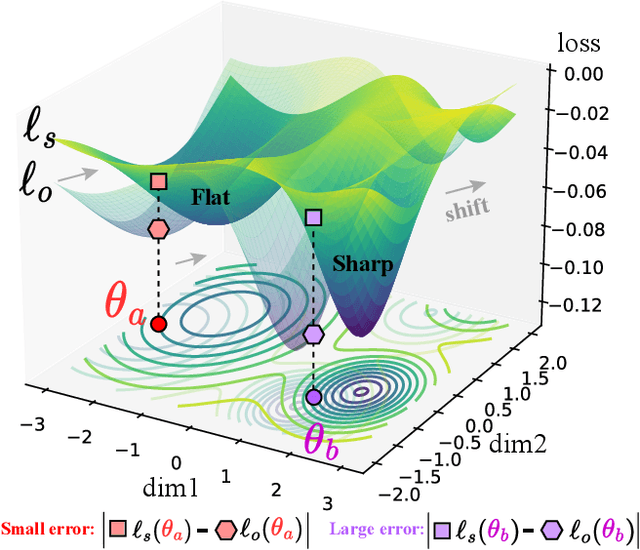
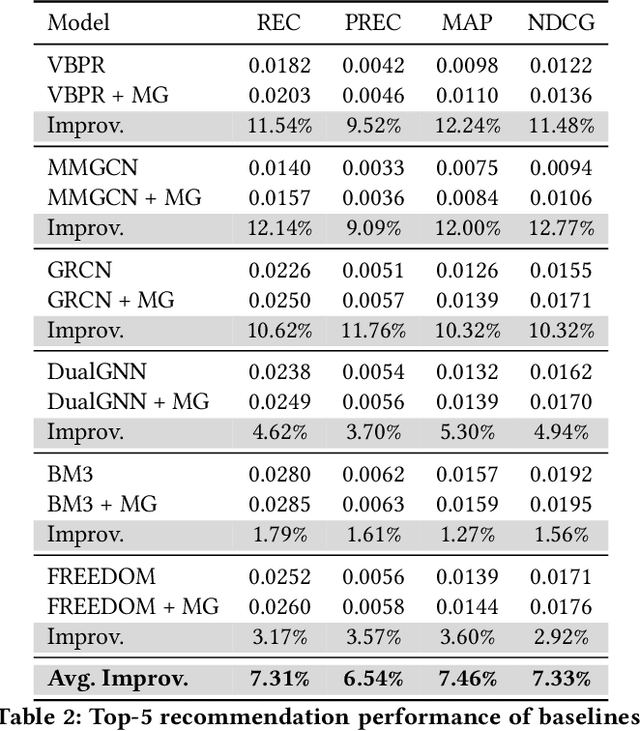
Multimodal recommender systems utilize various types of information to model user preferences and item features, helping users discover items aligned with their interests. The integration of multimodal information mitigates the inherent challenges in recommender systems, e.g., the data sparsity problem and cold-start issues. However, it simultaneously magnifies certain risks from multimodal information inputs, such as information adjustment risk and inherent noise risk. These risks pose crucial challenges to the robustness of recommendation models. In this paper, we analyze multimodal recommender systems from the novel perspective of flat local minima and propose a concise yet effective gradient strategy called Mirror Gradient (MG). This strategy can implicitly enhance the model's robustness during the optimization process, mitigating instability risks arising from multimodal information inputs. We also provide strong theoretical evidence and conduct extensive empirical experiments to show the superiority of MG across various multimodal recommendation models and benchmarks. Furthermore, we find that the proposed MG can complement existing robust training methods and be easily extended to diverse advanced recommendation models, making it a promising new and fundamental paradigm for training multimodal recommender systems. The code is released at https://github.com/Qrange-group/Mirror-Gradient.
Causal Inference for Chatting Handoff
Oct 06, 2022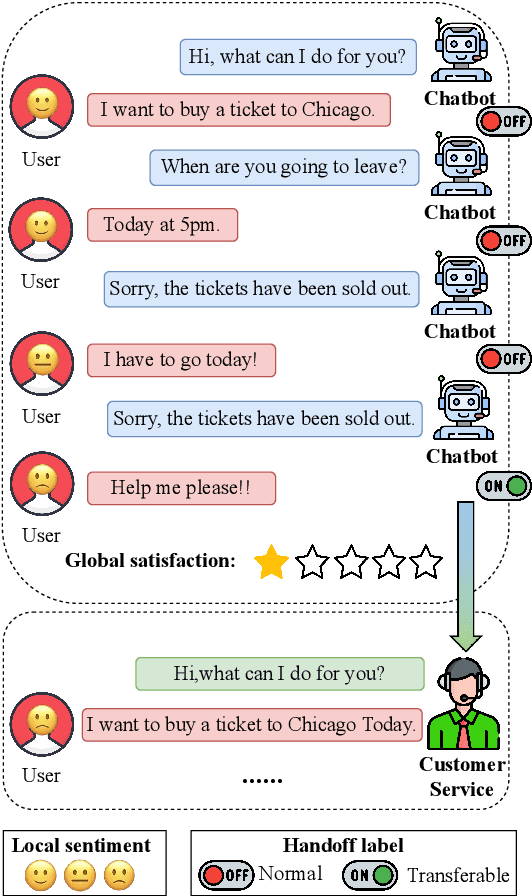
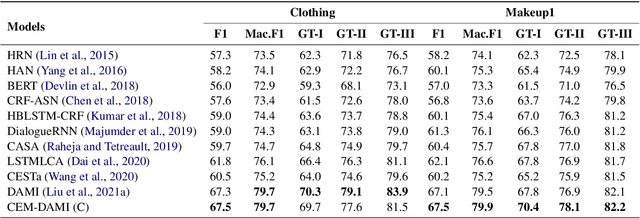
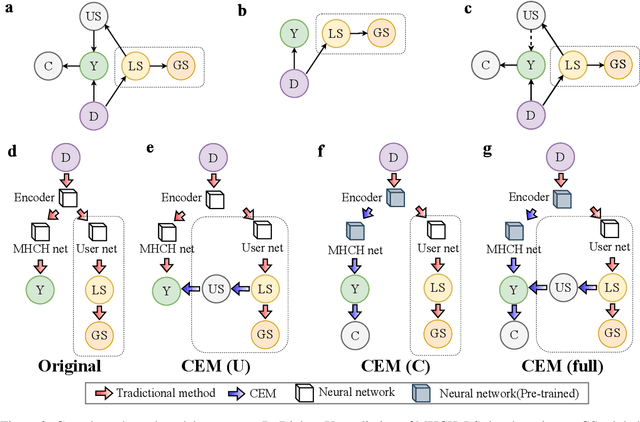
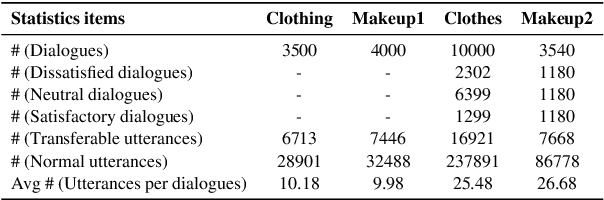
Aiming to ensure chatbot quality by predicting chatbot failure and enabling human-agent collaboration, Machine-Human Chatting Handoff (MHCH) has attracted lots of attention from both industry and academia in recent years. However, most existing methods mainly focus on the dialogue context or assist with global satisfaction prediction based on multi-task learning, which ignore the grounded relationships among the causal variables, like the user state and labor cost. These variables are significantly associated with handoff decisions, resulting in prediction bias and cost increasement. Therefore, we propose Causal-Enhance Module (CEM) by establishing the causal graph of MHCH based on these two variables, which is a simple yet effective module and can be easy to plug into the existing MHCH methods. For the impact of users, we use the user state to correct the prediction bias according to the causal relationship of multi-task. For the labor cost, we train an auxiliary cost simulator to calculate unbiased labor cost through counterfactual learning so that a model becomes cost-aware. Extensive experiments conducted on four real-world benchmarks demonstrate the effectiveness of CEM in generally improving the performance of existing MHCH methods without any elaborated model crafting.
Attribute2vec: Deep Network Embedding Through Multi-Filtering GCN
Apr 03, 2020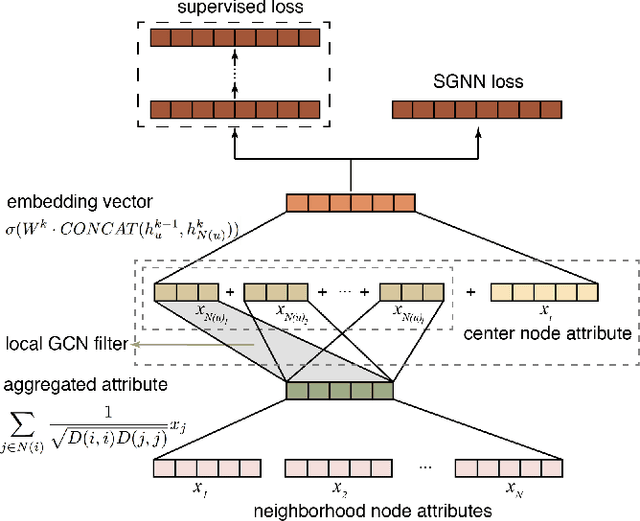
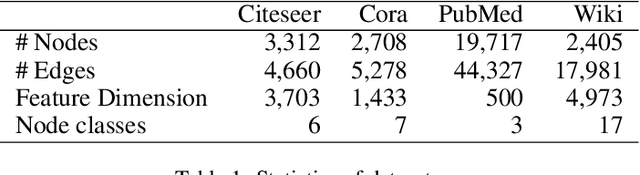
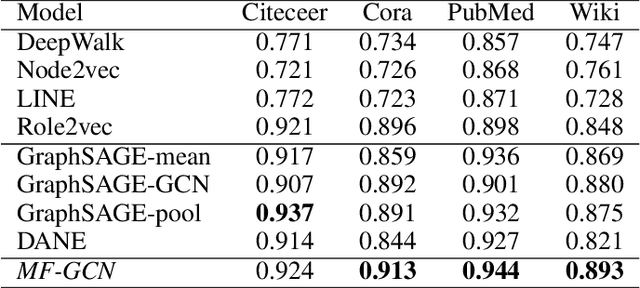
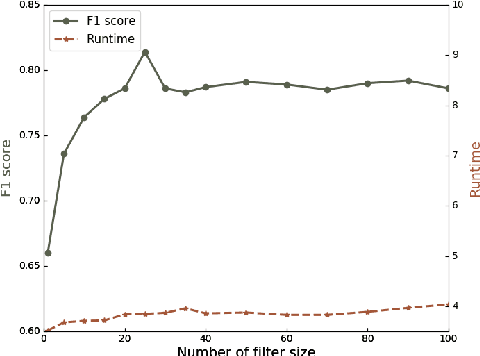
We present a multi-filtering Graph Convolution Neural Network (GCN) framework for network embedding task. It uses multiple local GCN filters to do feature extraction in every propagation layer. We show this approach could capture different important aspects of node features against the existing attribute embedding based method. We also show that with multi-filtering GCN approach, we can achieve significant improvement against baseline methods when training data is limited. We also perform many empirical experiments and demonstrate the benefit of using multiple filters against single filter as well as most current existing network embedding methods for both the link prediction and node classification tasks.
User-level Weibo Recommendation incorporating Social Influence based on Semi-Supervised Algorithm
Oct 26, 2012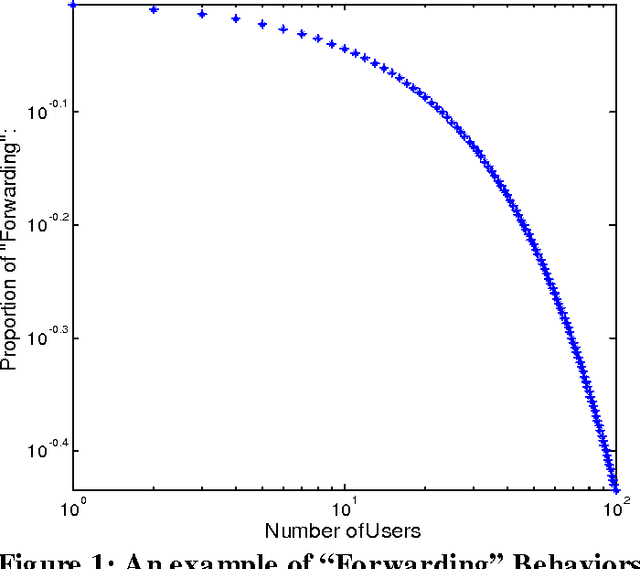

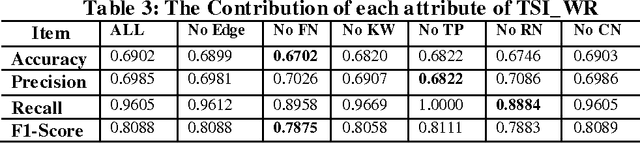
Tencent Weibo, as one of the most popular micro-blogging services in China, has attracted millions of users, producing 30-60 millions of weibo (similar as tweet in Twitter) daily. With the overload problem of user generate content, Tencent users find it is more and more hard to browse and find valuable information at the first time. In this paper, we propose a Factor Graph based weibo recommendation algorithm TSI-WR (Topic-Level Social Influence based Weibo Recommendation), which could help Tencent users to find most suitable information. The main innovation is that we consider both direct and indirect social influence from topic level based on social balance theory. The main advantages of adopting this strategy are that it could first build a more accurate description of latent relationship between two users with weak connections, which could help to solve the data sparsity problem; second provide a more accurate recommendation for a certain user from a wider range. Other meaningful contextual information is also combined into our model, which include: Users profile, Users influence, Content of weibos, Topic information of weibos and etc. We also design a semi-supervised algorithm to further reduce the influence of data sparisty. The experiments show that all the selected variables are important and the proposed model outperforms several baseline methods.
Topic-Level Opinion Influence Model(TOIM): An Investigation Using Tencent Micro-Blogging
Oct 24, 2012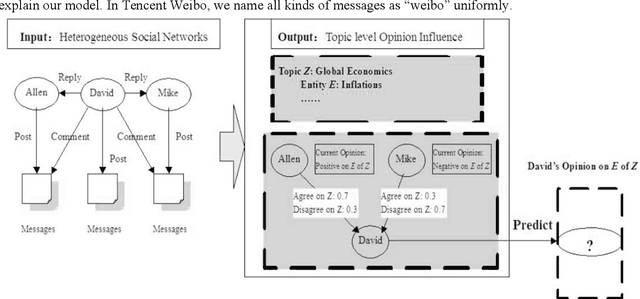
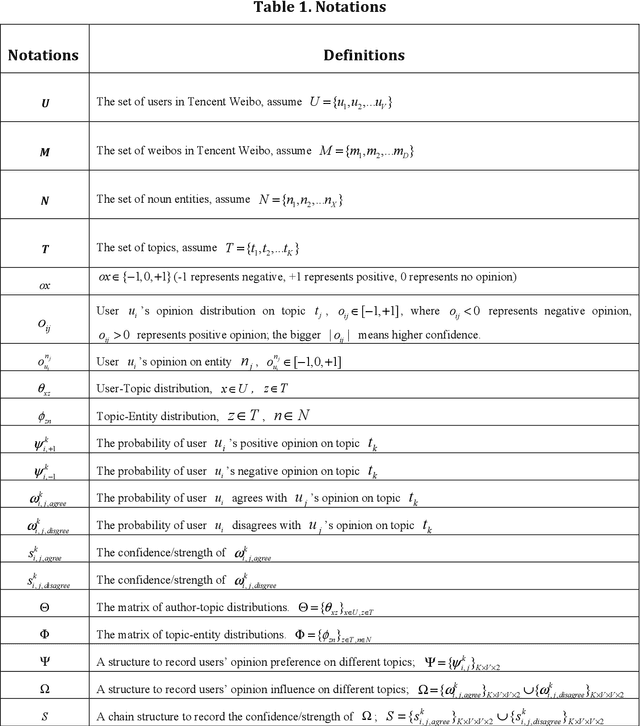
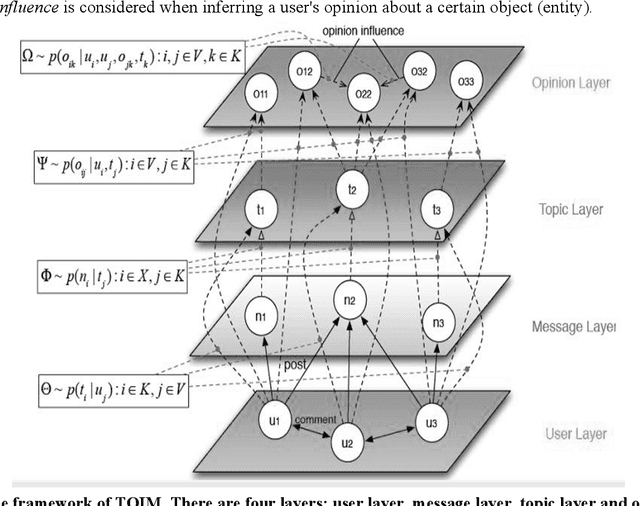
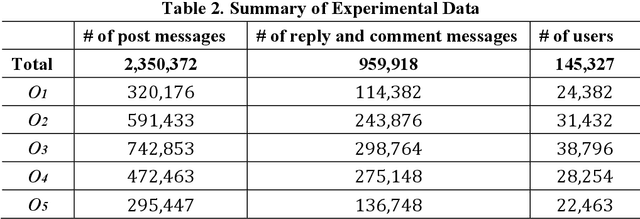
Mining user opinion from Micro-Blogging has been extensively studied on the most popular social networking sites such as Twitter and Facebook in the U.S., but few studies have been done on Micro-Blogging websites in other countries (e.g. China). In this paper, we analyze the social opinion influence on Tencent, one of the largest Micro-Blogging websites in China, endeavoring to unveil the behavior patterns of Chinese Micro-Blogging users. This paper proposes a Topic-Level Opinion Influence Model (TOIM) that simultaneously incorporates topic factor and social direct influence in a unified probabilistic framework. Based on TOIM, two topic level opinion influence propagation and aggregation algorithms are developed to consider the indirect influence: CP (Conservative Propagation) and NCP (None Conservative Propagation). Users' historical social interaction records are leveraged by TOIM to construct their progressive opinions and neighbors' opinion influence through a statistical learning process, which can be further utilized to predict users' future opinions on some specific topics. To evaluate and test this proposed model, an experiment was designed and a sub-dataset from Tencent Micro-Blogging was used. The experimental results show that TOIM outperforms baseline methods on predicting users' opinion. The applications of CP and NCP have no significant differences and could significantly improve recall and F1-measure of TOIM.