 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatial-aware Vision Language Model for Autonomous Driving
Dec 30, 2025While Vision-Language Models (VLMs) show significant promise for end-to-end autonomous driving by leveraging the common sense embedded in language models, their reliance on 2D image cues for complex scene understanding and decision-making presents a critical bottleneck for safety and reliability. Current image-based methods struggle with accurate metric spatial reasoning and geometric inference, leading to unreliable driving policies. To bridge this gap, we propose LVLDrive (LiDAR-Vision-Language), a novel framework specifically designed to upgrade existing VLMs with robust 3D metric spatial understanding for autonomous driving by incoperating LiDAR point cloud as an extra input modality. A key challenge lies in mitigating the catastrophic disturbance introduced by disparate 3D data to the pre-trained VLMs. To this end, we introduce a Gradual Fusion Q-Former that incrementally injects LiDAR features, ensuring the stability and preservation of the VLM's existing knowledge base. Furthermore, we develop a spatial-aware question-answering (SA-QA) dataset to explicitly teach the model advanced 3D perception and reasoning capabilities. Extensive experiments on driving benchmarks demonstrate that LVLDrive achieves superior performance compared to vision-only counterparts across scene understanding, metric spatial perception, and reliable driving decision-making. Our work highlights the necessity of explicit 3D metric data for building trustworthy VLM-based autonomous systems.
Maps for Autonomous Driving: Full-process Survey and Frontiers
Sep 16, 2025Maps have always been an essential component of autonomous driving. With the advancement of autonomous driving technology, both the representation and production process of maps have evolved substantially. The article categorizes the evolution of maps into three stages: High-Definition (HD) maps, Lightweight (Lite) maps, and Implicit maps. For each stage, we provide a comprehensive review of the map production workflow, with highlighting technical challenges involved and summarizing relevant solutions proposed by the academic community. Furthermore, we discuss cutting-edge research advances in map representations and explore how these innovations can be integrated into end-to-end autonomous driving frameworks.
Continual Learning for Smart City: A Survey
Apr 01, 2024With the digitization of modern cities, large data volumes and powerful computational resources facilitate the rapid update of intelligent models deployed in smart cities. Continual learning (CL) is a novel machine learning paradigm that constantly updates models to adapt to changing environments, where the learning tasks, data, and distributions can vary over time. Our survey provides a comprehensive review of continual learning methods that are widely used in smart city development. The content consists of three parts: 1) Methodology-wise. We categorize a large number of basic CL methods and advanced CL frameworks in combination with other learning paradigms including graph learning, spatial-temporal learning, multi-modal learning, and federated learning. 2) Application-wise. We present numerous CL applications covering transportation, environment, public health, safety, networks, and associated datasets related to urban computing. 3) Challenges. We discuss current problems and challenges and envision several promising research directions. We believe this survey can help relevant researchers quickly familiarize themselves with the current state of continual learning research used in smart city development and direct them to future research trends.
A Survey of Route Recommendations: Methods, Applications, and Opportunities
Mar 01, 2024



Nowadays, with advanced information technologies deployed citywide, large data volumes and powerful computational resources are intelligentizing modern city development. As an important part of intelligent transportation, route recommendation and its applications are widely used, directly influencing citizens` travel habits. Developing smart and efficient travel routes based on big data (possibly multi-modal) has become a central challenge in route recommendation research. Our survey offers a comprehensive review of route recommendation work based on urban computing. It is organized by the following three parts: 1) Methodology-wise. We categorize a large volume of traditional machine learning and modern deep learning methods. Also, we discuss their historical relations and reveal the edge-cutting progress. 2) Application\-wise. We present numerous novel applications related to route commendation within urban computing scenarios. 3) We discuss current problems and challenges and envision several promising research directions. We believe that this survey can help relevant researchers quickly familiarize themselves with the current state of route recommendation research and then direct them to future research trends.
Online Map Vectorization for Autonomous Driving: A Rasterization Perspective
Jun 18, 2023



Vectorized high-definition (HD) map is essential for autonomous driving, providing detailed and precise environmental information for advanced perception and planning. However, current map vectorization methods often exhibit deviations, and the existing evaluation metric for map vectorization lacks sufficient sensitivity to detect these deviations. To address these limitations, we propose integrating the philosophy of rasterization into map vectorization. Specifically, we introduce a new rasterization-based evaluation metric, which has superior sensitivity and is better suited to real-world autonomous driving scenarios. Furthermore, we propose MapVR (Map Vectorization via Rasterization), a novel framework that applies differentiable rasterization to vectorized outputs and then performs precise and geometry-aware supervision on rasterized HD maps. Notably, MapVR designs tailored rasterization strategies for various geometric shapes, enabling effective adaptation to a wide range of map elements. Experiments show that incorporating rasterization into map vectorization greatly enhances performance with no extra computational cost during inference, leading to more accurate map perception and ultimately promoting safer autonomous driving.
Modeling Continuous Motion for 3D Point Cloud Object Tracking
Mar 14, 2023The task of 3D single object tracking (SOT) with LiDAR point clouds is crucial for various applications, such as autonomous driving and robotics. However, existing approaches have primarily relied on appearance matching or motion modeling within only two successive frames, thereby overlooking the long-range continuous motion property of objects in 3D space. To address this issue, this paper presents a novel approach that views each tracklet as a continuous stream: at each timestamp, only the current frame is fed into the network to interact with multi-frame historical features stored in a memory bank, enabling efficient exploitation of sequential information. To achieve effective cross-frame message passing, a hybrid attention mechanism is designed to account for both long-range relation modeling and local geometric feature extraction. Furthermore, to enhance the utilization of multi-frame features for robust tracking, a contrastive sequence enhancement strategy is designed, which uses ground truth tracklets to augment training sequences and promote discrimination against false positives in a contrastive manner. Extensive experiments demonstrate that the proposed method outperforms the state-of-the-art method by significant margins (approximately 8%, 6%, and 12% improvements in the success performance on KITTI, nuScenes, and Waymo, respectively).
DETR4D: Direct Multi-View 3D Object Detection with Sparse Attention
Dec 15, 20223D object detection with surround-view images is an essential task for autonomous driving. In this work, we propose DETR4D, a Transformer-based framework that explores sparse attention and direct feature query for 3D object detection in multi-view images. We design a novel projective cross-attention mechanism for query-image interaction to address the limitations of existing methods in terms of geometric cue exploitation and information loss for cross-view objects. In addition, we introduce a heatmap generation technique that bridges 3D and 2D spaces efficiently via query initialization. Furthermore, unlike the common practice of fusing intermediate spatial features for temporal aggregation, we provide a new perspective by introducing a novel hybrid approach that performs cross-frame fusion over past object queries and image features, enabling efficient and robust modeling of temporal information. Extensive experiments on the nuScenes dataset demonstrate the effectiveness and efficiency of the proposed DETR4D.
Towards Efficient Use of Multi-Scale Features in Transformer-Based Object Detectors
Aug 24, 2022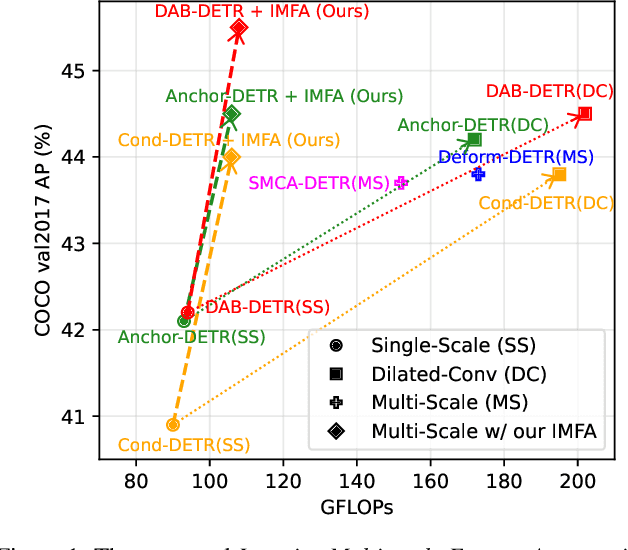
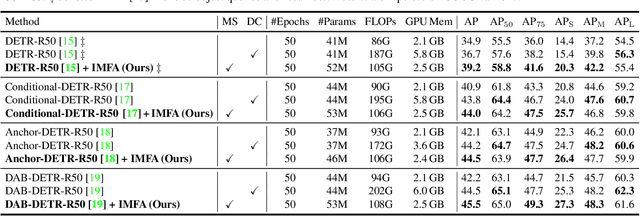
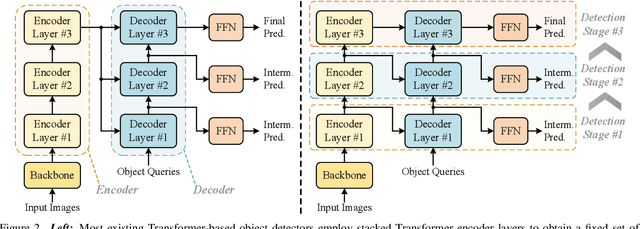
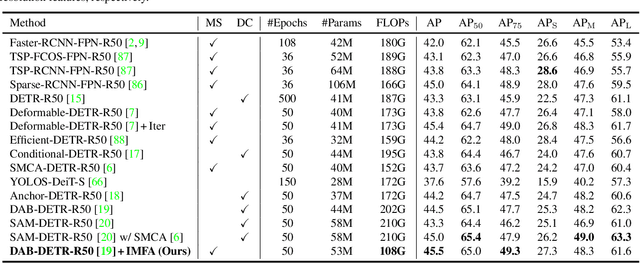
Multi-scale features have been proven highly effective for object detection, and most ConvNet-based object detectors adopt Feature Pyramid Network (FPN) as a basic component for exploiting multi-scale features. However, for the recently proposed Transformer-based object detectors, directly incorporating multi-scale features leads to prohibitive computational overhead due to the high complexity of the attention mechanism for processing high-resolution features. This paper presents Iterative Multi-scale Feature Aggregation (IMFA) -- a generic paradigm that enables the efficient use of multi-scale features in Transformer-based object detectors. The core idea is to exploit sparse multi-scale features from just a few crucial locations, and it is achieved with two novel designs. First, IMFA rearranges the Transformer encoder-decoder pipeline so that the encoded features can be iteratively updated based on the detection predictions. Second, IMFA sparsely samples scale-adaptive features for refined detection from just a few keypoint locations under the guidance of prior detection predictions. As a result, the sampled multi-scale features are sparse yet still highly beneficial for object detection. Extensive experiments show that the proposed IMFA boosts the performance of multiple Transformer-based object detectors significantly yet with slight computational overhead. Project page: https://github.com/ZhangGongjie/IMFA.
Exploring Point-BEV Fusion for 3D Point Cloud Object Tracking with Transformer
Aug 10, 2022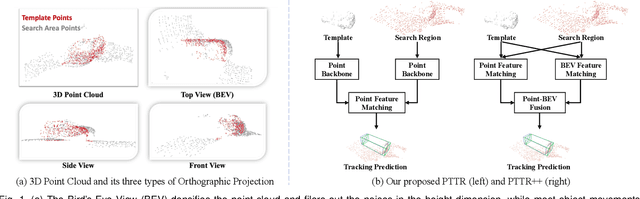
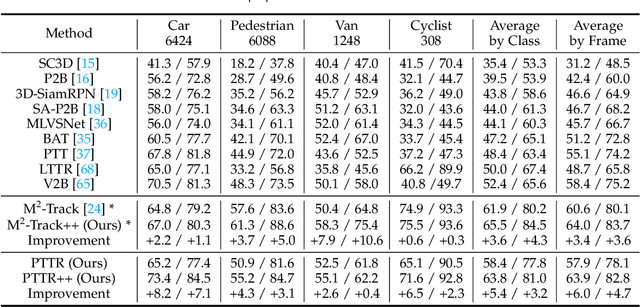
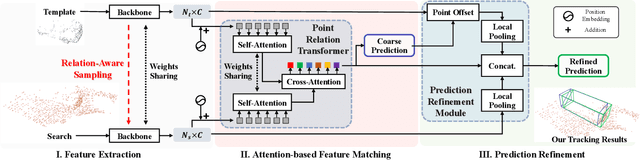
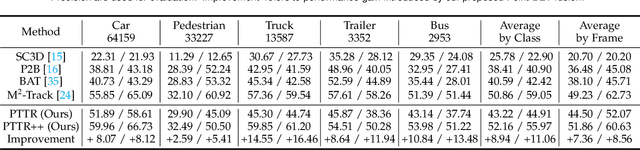
With the prevalence of LiDAR sensors in autonomous driving, 3D object tracking has received increasing attention. In a point cloud sequence, 3D object tracking aims to predict the location and orientation of an object in consecutive frames given an object template. Motivated by the success of transformers, we propose Point Tracking TRansformer (PTTR), which efficiently predicts high-quality 3D tracking results in a coarse-to-fine manner with the help of transformer operations. PTTR consists of three novel designs. 1) Instead of random sampling, we design Relation-Aware Sampling to preserve relevant points to the given template during subsampling. 2) We propose a Point Relation Transformer for effective feature aggregation and feature matching between the template and search region. 3) Based on the coarse tracking results, we employ a novel Prediction Refinement Module to obtain the final refined prediction through local feature pooling. In addition, motivated by the favorable properties of the Bird's-Eye View (BEV) of point clouds in capturing object motion, we further design a more advanced framework named PTTR++, which incorporates both the point-wise view and BEV representation to exploit their complementary effect in generating high-quality tracking results. PTTR++ substantially boosts the tracking performance on top of PTTR with low computational overhead. Extensive experiments over multiple datasets show that our proposed approaches achieve superior 3D tracking accuracy and efficiency.
TransPillars: Coarse-to-Fine Aggregation for Multi-Frame 3D Object Detection
Aug 04, 2022



3D object detection using point clouds has attracted increasing attention due to its wide applications in autonomous driving and robotics. However, most existing studies focus on single point cloud frames without harnessing the temporal information in point cloud sequences. In this paper, we design TransPillars, a novel transformer-based feature aggregation technique that exploits temporal features of consecutive point cloud frames for multi-frame 3D object detection. TransPillars aggregates spatial-temporal point cloud features from two perspectives. First, it fuses voxel-level features directly from multi-frame feature maps instead of pooled instance features to preserve instance details with contextual information that are essential to accurate object localization. Second, it introduces a hierarchical coarse-to-fine strategy to fuse multi-scale features progressively to effectively capture the motion of moving objects and guide the aggregation of fine features. Besides, a variant of deformable transformer is introduced to improve the effectiveness of cross-frame feature matching. Extensive experiments show that our proposed TransPillars achieves state-of-art performance as compared to existing multi-frame detection approaches. Code will be released.