 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZoom-IQA: Image Quality Assessment with Reliable Region-Aware Reasoning
Jan 06, 2026Image Quality Assessment (IQA) is a long-standing problem in computer vision. Previous methods typically focus on predicting numerical scores without explanation or provide low-level descriptions lacking precise scores. Recent reasoning-based vision language models (VLMs) have shown strong potential for IQA, enabling joint generation of quality descriptions and scores. However, we notice that existing VLM-based IQA methods tend to exhibit unreliable reasoning due to their limited capability of integrating visual and textual cues. In this work, we introduce Zoom-IQA, a VLM-based IQA model to explicitly emulate key cognitive behaviors: uncertainty awareness, region reasoning, and iterative refinement. Specifically, we present a two-stage training pipeline: 1) supervised fine-tuning (SFT) on our Grounded-Rationale-IQA (GR-IQA) dataset to teach the model to ground its assessments in key regions; and 2) reinforcement learning (RL) for dynamic policy exploration, primarily stabilized by our KL-Coverage regularizer to prevent reasoning and scoring diversity collapse, and supported by a Progressive Re-sampling Strategy to mitigate annotation bias. Extensive experiments show that Zoom-IQA achieves improved robustness, explainability, and generalization. The application to downstream tasks, such as image restoration, further demonstrates the effectiveness of Zoom-IQA.
DHAGrasp: Synthesizing Affordance-Aware Dual-Hand Grasps with Text Instructions
Sep 26, 2025Learning to generate dual-hand grasps that respect object semantics is essential for robust hand-object interaction but remains largely underexplored due to dataset scarcity. Existing grasp datasets predominantly focus on single-hand interactions and contain only limited semantic part annotations. To address these challenges, we introduce a pipeline, SymOpt, that constructs a large-scale dual-hand grasp dataset by leveraging existing single-hand datasets and exploiting object and hand symmetries. Building on this, we propose a text-guided dual-hand grasp generator, DHAGrasp, that synthesizes Dual-Hand Affordance-aware Grasps for unseen objects. Our approach incorporates a novel dual-hand affordance representation and follows a two-stage design, which enables effective learning from a small set of segmented training objects while scaling to a much larger pool of unsegmented data. Extensive experiments demonstrate that our method produces diverse and semantically consistent grasps, outperforming strong baselines in both grasp quality and generalization to unseen objects. The project page is at https://quanzhou-li.github.io/DHAGrasp/.
Integrating SAM Supervision for 3D Weakly Supervised Point Cloud Segmentation
Aug 27, 2025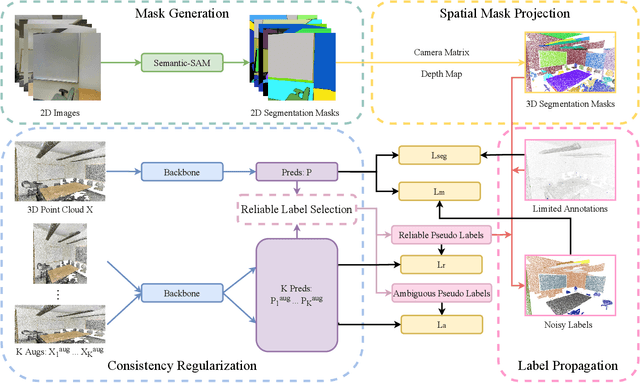
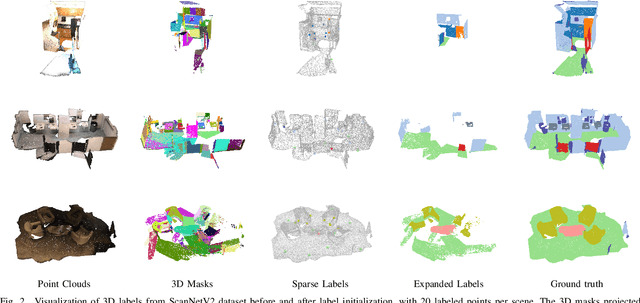


Current methods for 3D semantic segmentation propose training models with limited annotations to address the difficulty of annotating large, irregular, and unordered 3D point cloud data. They usually focus on the 3D domain only, without leveraging the complementary nature of 2D and 3D data. Besides, some methods extend original labels or generate pseudo labels to guide the training, but they often fail to fully use these labels or address the noise within them. Meanwhile, the emergence of comprehensive and adaptable foundation models has offered effective solutions for segmenting 2D data. Leveraging this advancement, we present a novel approach that maximizes the utility of sparsely available 3D annotations by incorporating segmentation masks generated by 2D foundation models. We further propagate the 2D segmentation masks into the 3D space by establishing geometric correspondences between 3D scenes and 2D views. We extend the highly sparse annotations to encompass the areas delineated by 3D masks, thereby substantially augmenting the pool of available labels. Furthermore, we apply confidence- and uncertainty-based consistency regularization on augmentations of the 3D point cloud and select the reliable pseudo labels, which are further spread on the 3D masks to generate more labels. This innovative strategy bridges the gap between limited 3D annotations and the powerful capabilities of 2D foundation models, ultimately improving the performance of 3D weakly supervised segmentation.
SA-LUT: Spatial Adaptive 4D Look-Up Table for Photorealistic Style Transfer
Jun 16, 2025Photorealistic style transfer (PST) enables real-world color grading by adapting reference image colors while preserving content structure. Existing methods mainly follow either approaches: generation-based methods that prioritize stylistic fidelity at the cost of content integrity and efficiency, or global color transformation methods such as LUT, which preserve structure but lack local adaptability. To bridge this gap, we propose Spatial Adaptive 4D Look-Up Table (SA-LUT), combining LUT efficiency with neural network adaptability. SA-LUT features: (1) a Style-guided 4D LUT Generator that extracts multi-scale features from the style image to predict a 4D LUT, and (2) a Context Generator using content-style cross-attention to produce a context map. This context map enables spatially-adaptive adjustments, allowing our 4D LUT to apply precise color transformations while preserving structural integrity. To establish a rigorous evaluation framework for photorealistic style transfer, we introduce PST50, the first benchmark specifically designed for PST assessment. Experiments demonstrate that SA-LUT substantially outperforms state-of-the-art methods, achieving a 66.7% reduction in LPIPS score compared to 3D LUT approaches, while maintaining real-time performance at 16 FPS for video stylization. Our code and benchmark are available at https://github.com/Ry3nG/SA-LUT
OpenUni: A Simple Baseline for Unified Multimodal Understanding and Generation
May 29, 2025In this report, we present OpenUni, a simple, lightweight, and fully open-source baseline for unifying multimodal understanding and generation. Inspired by prevailing practices in unified model learning, we adopt an efficient training strategy that minimizes the training complexity and overhead by bridging the off-the-shelf multimodal large language models (LLMs) and diffusion models through a set of learnable queries and a light-weight transformer-based connector. With a minimalist choice of architecture, we demonstrate that OpenUni can: 1) generate high-quality and instruction-aligned images, and 2) achieve exceptional performance on standard benchmarks such as GenEval, DPG- Bench, and WISE, with only 1.1B and 3.1B activated parameters. To support open research and community advancement, we release all model weights, training code, and our curated training datasets (including 23M image-text pairs) at https://github.com/wusize/OpenUni.
Harmonizing Visual Representations for Unified Multimodal Understanding and Generation
Mar 27, 2025
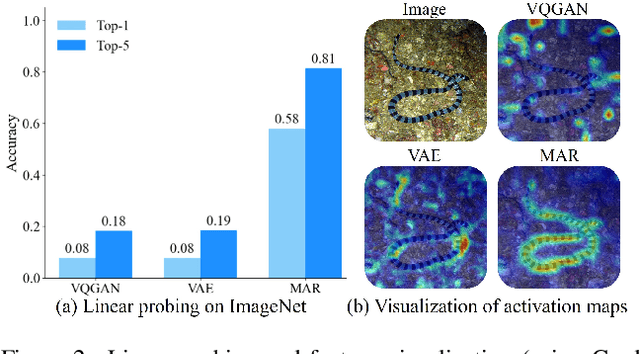
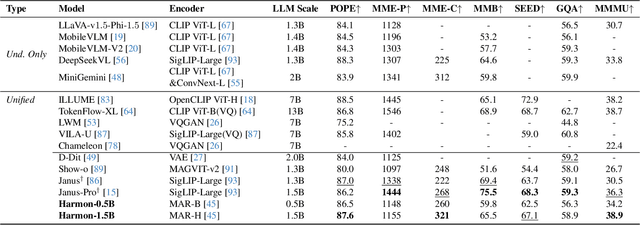
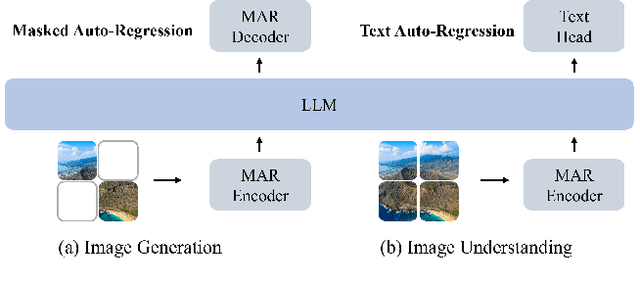
Unifying visual understanding and generation within a single multimodal framework remains a significant challenge, as the two inherently heterogeneous tasks require representations at different levels of granularity. Current approaches that utilize vector quantization (VQ) or variational autoencoders (VAE) for unified visual representation prioritize intrinsic imagery features over semantics, compromising understanding performance. In this work, we take inspiration from masked image modelling (MIM) that learns rich semantics via a mask-and-reconstruct pre-training and its successful extension to masked autoregressive (MAR) image generation. A preliminary study on the MAR encoder's representation reveals exceptional linear probing accuracy and precise feature response to visual concepts, which indicates MAR's potential for visual understanding tasks beyond its original generation role. Based on these insights, we present \emph{Harmon}, a unified autoregressive framework that harmonizes understanding and generation tasks with a shared MAR encoder. Through a three-stage training procedure that progressively optimizes understanding and generation capabilities, Harmon achieves state-of-the-art image generation results on the GenEval, MJHQ30K and WISE benchmarks while matching the performance of methods with dedicated semantic encoders (e.g., Janus) on image understanding benchmarks. Our code and models will be available at https://github.com/wusize/Harmon.
CodeBrain: Impute Any Brain MRI via Instance-specific Scalar-quantized Codes
Jan 30, 2025MRI imputation aims to synthesize the missing modality from one or more available ones, which is highly desirable since it reduces scanning costs and delivers comprehensive MRI information to enhance clinical diagnosis. In this paper, we propose a unified model, CodeBrain, designed to adapt to various brain MRI imputation scenarios. The core design lies in casting various inter-modality transformations as a full-modality code prediction task. To this end, CodeBrain is trained in two stages: Reconstruction and Code Prediction. First, in the Reconstruction stage, we reconstruct each MRI modality, which is mapped into a shared latent space followed by a scalar quantization. Since such quantization is lossy and the code is low dimensional, another MRI modality belonging to the same subject is randomly selected to generate common features to supplement the code and boost the target reconstruction. In the second stage, we train another encoder by a customized grading loss to predict the full-modality codes from randomly masked MRI samples, supervised by the corresponding quantized codes generated from the first stage. In this way, the inter-modality transformation is achieved by mapping the instance-specific codes in a finite scalar space. We evaluated the proposed CodeBrain model on two public brain MRI datasets (i.e., IXI and BraTS 2023). Extensive experiments demonstrate that our CodeBrain model achieves superior imputation performance compared to four existing methods, establishing a new state of the art for unified brain MRI imputation. Codes will be released.
IPVTON: Image-based 3D Virtual Try-on with Image Prompt Adapter
Jan 26, 2025
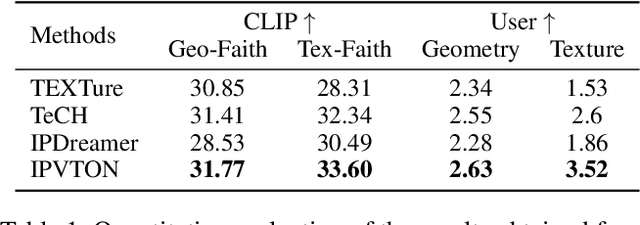
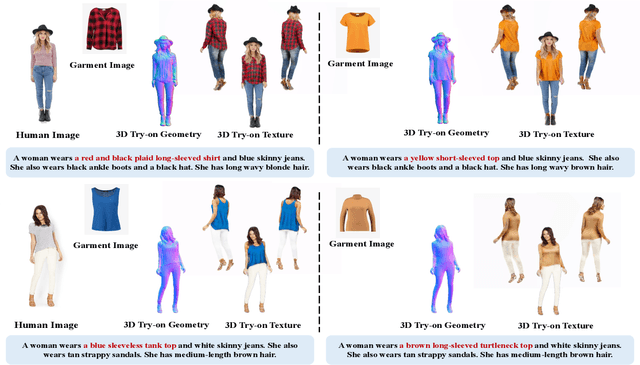
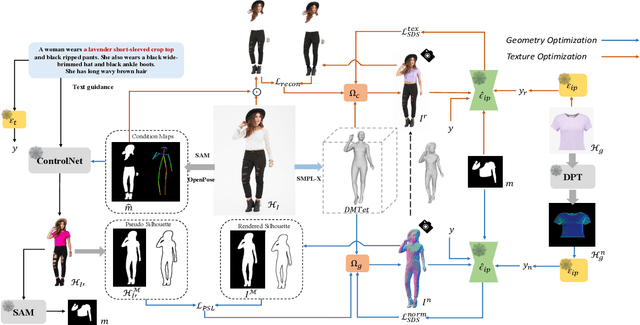
Given a pair of images depicting a person and a garment separately, image-based 3D virtual try-on methods aim to reconstruct a 3D human model that realistically portrays the person wearing the desired garment. In this paper, we present IPVTON, a novel image-based 3D virtual try-on framework. IPVTON employs score distillation sampling with image prompts to optimize a hybrid 3D human representation, integrating target garment features into diffusion priors through an image prompt adapter. To avoid interference with non-target areas, we leverage mask-guided image prompt embeddings to focus the image features on the try-on regions. Moreover, we impose geometric constraints on the 3D model with a pseudo silhouette generated by ControlNet, ensuring that the clothed 3D human model retains the shape of the source identity while accurately wearing the target garments. Extensive qualitative and quantitative experiments demonstrate that IPVTON outperforms previous methods in image-based 3D virtual try-on tasks, excelling in both geometry and texture.
MOWA: Multiple-in-One Image Warping Model
Apr 16, 2024

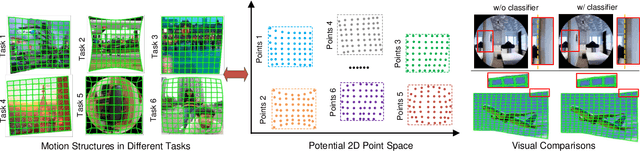

While recent image warping approaches achieved remarkable success on existing benchmarks, they still require training separate models for each specific task and cannot generalize well to different camera models or customized manipulations. To address diverse types of warping in practice, we propose a Multiple-in-One image WArping model (named MOWA) in this work. Specifically, we mitigate the difficulty of multi-task learning by disentangling the motion estimation at both the region level and pixel level. To further enable dynamic task-aware image warping, we introduce a lightweight point-based classifier that predicts the task type, serving as prompts to modulate the feature maps for better estimation. To our knowledge, this is the first work that solves multiple practical warping tasks in one single model. Extensive experiments demonstrate that our MOWA, which is trained on six tasks for multiple-in-one image warping, outperforms state-of-the-art task-specific models across most tasks. Moreover, MOWA also exhibits promising potential to generalize into unseen scenes, as evidenced by cross-domain and zero-shot evaluations. The code will be made publicly available.
Towards Robust and Expressive Whole-body Human Pose and Shape Estimation
Dec 14, 2023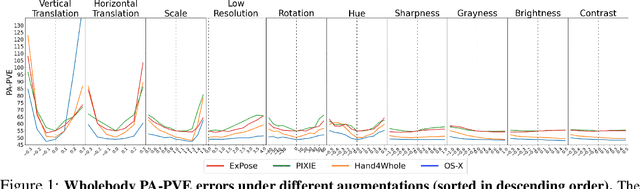


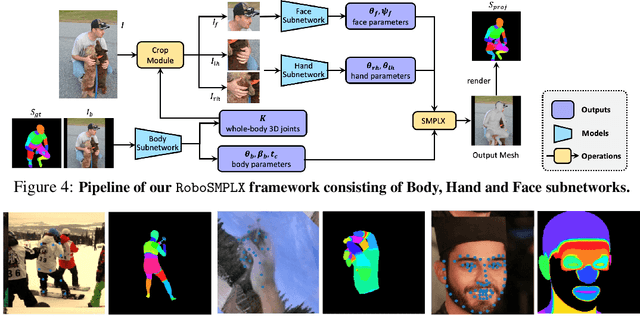
Whole-body pose and shape estimation aims to jointly predict different behaviors (e.g., pose, hand gesture, facial expression) of the entire human body from a monocular image. Existing methods often exhibit degraded performance under the complexity of in-the-wild scenarios. We argue that the accuracy and reliability of these models are significantly affected by the quality of the predicted \textit{bounding box}, e.g., the scale and alignment of body parts. The natural discrepancy between the ideal bounding box annotations and model detection results is particularly detrimental to the performance of whole-body pose and shape estimation. In this paper, we propose a novel framework to enhance the robustness of whole-body pose and shape estimation. Our framework incorporates three new modules to address the above challenges from three perspectives: \textbf{1) Localization Module} enhances the model's awareness of the subject's location and semantics within the image space. \textbf{2) Contrastive Feature Extraction Module} encourages the model to be invariant to robust augmentations by incorporating contrastive loss with dedicated positive samples. \textbf{3) Pixel Alignment Module} ensures the reprojected mesh from the predicted camera and body model parameters are accurate and pixel-aligned. We perform comprehensive experiments to demonstrate the effectiveness of our proposed framework on body, hands, face and whole-body benchmarks. Codebase is available at \url{https://github.com/robosmplx/robosmplx}.