 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoe: Towards Efficient and Low-Cost MoE Inference in Serverless Computing
Dec 21, 2025Mixture-of-Experts (MoE) has become a dominant architecture in large language models (LLMs) due to its ability to scale model capacity via sparse expert activation. Meanwhile, serverless computing, with its elasticity and pay-per-use billing, is well-suited for deploying MoEs with bursty workloads. However, the large number of experts in MoE models incurs high inference costs due to memory-intensive parameter caching. These costs are difficult to mitigate via simple model partitioning due to input-dependent expert activation. To address these issues, we propose Remoe, a heterogeneous MoE inference system tailored for serverless computing. Remoe assigns non-expert modules to GPUs and expert modules to CPUs, and further offloads infrequently activated experts to separate serverless functions to reduce memory overhead and enable parallel execution. We incorporate three key techniques: (1) a Similar Prompts Searching (SPS) algorithm to predict expert activation patterns based on semantic similarity of inputs; (2) a Main Model Pre-allocation (MMP) algorithm to ensure service-level objectives (SLOs) via worst-case memory estimation; and (3) a joint memory and replica optimization framework leveraging Lagrangian duality and the Longest Processing Time (LPT) algorithm. We implement Remoe on Kubernetes and evaluate it across multiple LLM benchmarks. Experimental results show that Remoe reduces inference cost by up to 57% and cold start latency by 47% compared to state-of-the-art baselines.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
Cultivating Helpful, Personalized, and Creative AI Tutors: A Framework for Pedagogical Alignment using Reinforcement Learning
Jul 27, 2025
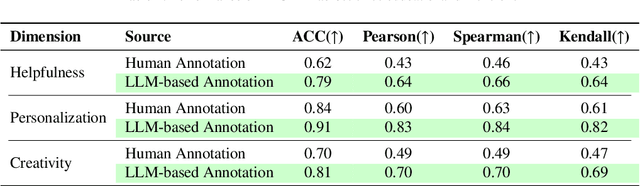

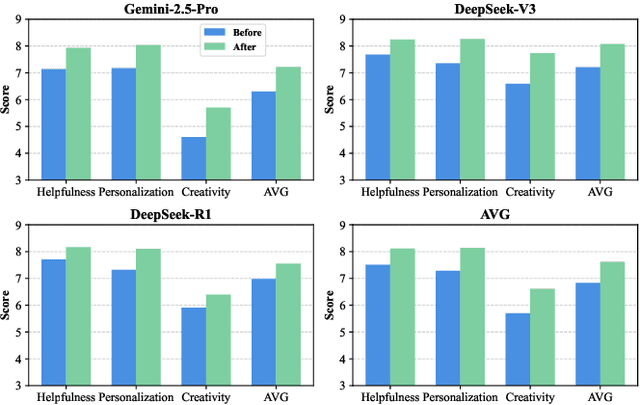
The integration of large language models (LLMs) into education presents unprecedented opportunities for scalable personalized learning. However, standard LLMs often function as generic information providers, lacking alignment with fundamental pedagogical principles such as helpfulness, student-centered personalization, and creativity cultivation. To bridge this gap, we propose EduAlign, a novel framework designed to guide LLMs toward becoming more effective and responsible educational assistants. EduAlign consists of two main stages. In the first stage, we curate a dataset of 8k educational interactions and annotate them-both manually and automatically-along three key educational dimensions: Helpfulness, Personalization, and Creativity (HPC). These annotations are used to train HPC-RM, a multi-dimensional reward model capable of accurately scoring LLM outputs according to these educational principles. We further evaluate the consistency and reliability of this reward model. In the second stage, we leverage HPC-RM as a reward signal to fine-tune a pre-trained LLM using Group Relative Policy Optimization (GRPO) on a set of 2k diverse prompts. We then assess the pre- and post-finetuning models on both educational and general-domain benchmarks across the three HPC dimensions. Experimental results demonstrate that the fine-tuned model exhibits significantly improved alignment with pedagogical helpfulness, personalization, and creativity stimulation. This study presents a scalable and effective approach to aligning LLMs with nuanced and desirable educational traits, paving the way for the development of more engaging, pedagogically aligned AI tutors.
Harmonizing Visual Representations for Unified Multimodal Understanding and Generation
Mar 27, 2025
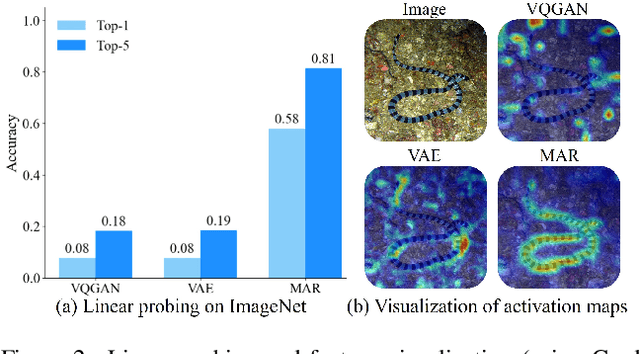
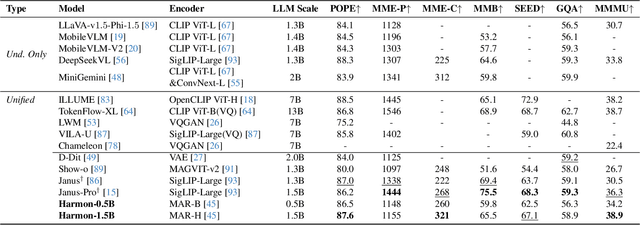
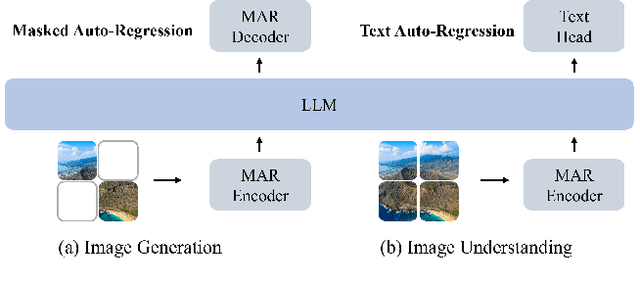
Unifying visual understanding and generation within a single multimodal framework remains a significant challenge, as the two inherently heterogeneous tasks require representations at different levels of granularity. Current approaches that utilize vector quantization (VQ) or variational autoencoders (VAE) for unified visual representation prioritize intrinsic imagery features over semantics, compromising understanding performance. In this work, we take inspiration from masked image modelling (MIM) that learns rich semantics via a mask-and-reconstruct pre-training and its successful extension to masked autoregressive (MAR) image generation. A preliminary study on the MAR encoder's representation reveals exceptional linear probing accuracy and precise feature response to visual concepts, which indicates MAR's potential for visual understanding tasks beyond its original generation role. Based on these insights, we present \emph{Harmon}, a unified autoregressive framework that harmonizes understanding and generation tasks with a shared MAR encoder. Through a three-stage training procedure that progressively optimizes understanding and generation capabilities, Harmon achieves state-of-the-art image generation results on the GenEval, MJHQ30K and WISE benchmarks while matching the performance of methods with dedicated semantic encoders (e.g., Janus) on image understanding benchmarks. Our code and models will be available at https://github.com/wusize/Harmon.
NADER: Neural Architecture Design via Multi-Agent Collaboration
Dec 26, 2024



Designing effective neural architectures poses a significant challenge in deep learning. While Neural Architecture Search (NAS) automates the search for optimal architectures, existing methods are often constrained by predetermined search spaces and may miss critical neural architectures. In this paper, we introduce NADER (Neural Architecture Design via multi-agEnt collaboRation), a novel framework that formulates neural architecture design (NAD) as a LLM-based multi-agent collaboration problem. NADER employs a team of specialized agents to enhance a base architecture through iterative modification. Current LLM-based NAD methods typically operate independently, lacking the ability to learn from past experiences, which results in repeated mistakes and inefficient exploration. To address this issue, we propose the Reflector, which effectively learns from immediate feedback and long-term experiences. Additionally, unlike previous LLM-based methods that use code to represent neural architectures, we utilize a graph-based representation. This approach allows agents to focus on design aspects without being distracted by coding. We demonstrate the effectiveness of NADER in discovering high-performing architectures beyond predetermined search spaces through extensive experiments on benchmark tasks, showcasing its advantages over state-of-the-art methods. The codes will be released soon.
ShotVL: Human-Centric Highlight Frame Retrieval via Language Queries
Dec 17, 2024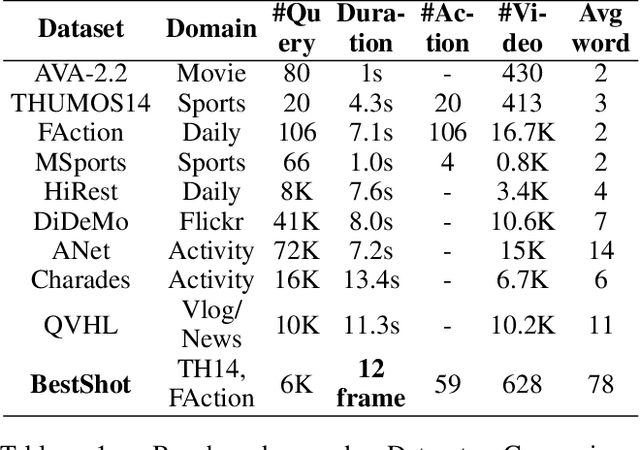

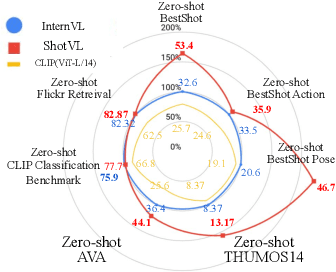
Existing works on human-centric video understanding typically focus on analyzing specific moment or entire videos. However, many applications require higher precision at the frame level. In this work, we propose a novel task, BestShot, which aims to locate highlight frames within human-centric videos via language queries. This task demands not only a deep semantic comprehension of human actions but also precise temporal localization. To support this task, we introduce the BestShot Benchmark. %The benchmark is meticulously constructed by combining human detection and tracking, potential frame selection based on human judgment, and detailed textual descriptions crafted by human input to ensure precision. The benchmark is meticulously constructed by combining human-annotated highlight frames, detailed textual descriptions and duration labeling. These descriptions encompass three critical elements: (1) Visual content; (2) Fine-grained action; and (3) Human Pose Description. Together, these elements provide the necessary precision to identify the exact highlight frames in videos. To tackle this problem, we have collected two distinct datasets: (i) ShotGPT4o Dataset, which is algorithmically generated by GPT-4o and (ii) Image-SMPLText Dataset, a dataset with large-scale and accurate per-frame pose description leveraging PoseScript and existing pose estimation datasets. Based on these datasets, we present a strong baseline model, ShotVL, fine-tuned from InternVL, specifically for BestShot. We highlight the impressive zero-shot capabilities of our model and offer comparative analyses with existing SOTA models. ShotVL demonstrates a significant 52% improvement over InternVL on the BestShot Benchmark and a notable 57% improvement on the THUMOS14 Benchmark, all while maintaining the SOTA performance in general image classification and retrieval.
KptLLM: Unveiling the Power of Large Language Model for Keypoint Comprehension
Nov 04, 2024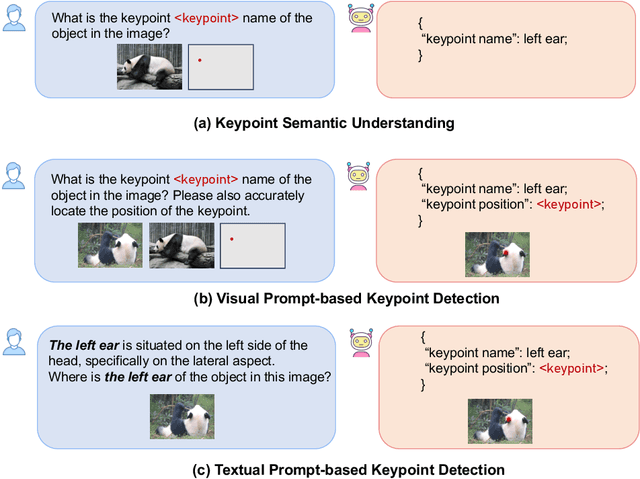



Recent advancements in Multimodal Large Language Models (MLLMs) have greatly improved their abilities in image understanding. However, these models often struggle with grasping pixel-level semantic details, e.g., the keypoints of an object. To bridge this gap, we introduce the novel challenge of Semantic Keypoint Comprehension, which aims to comprehend keypoints across different task scenarios, including keypoint semantic understanding, visual prompt-based keypoint detection, and textual prompt-based keypoint detection. Moreover, we introduce KptLLM, a unified multimodal model that utilizes an identify-then-detect strategy to effectively address these challenges. KptLLM underscores the initial discernment of semantics in keypoints, followed by the precise determination of their positions through a chain-of-thought process. With several carefully designed modules, KptLLM adeptly handles various modality inputs, facilitating the interpretation of both semantic contents and keypoint locations. Our extensive experiments demonstrate KptLLM's superiority in various keypoint detection benchmarks and its unique semantic capabilities in interpreting keypoints.
PhoCoLens: Photorealistic and Consistent Reconstruction in Lensless Imaging
Sep 26, 2024
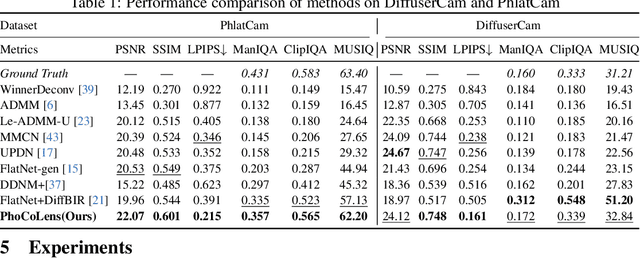

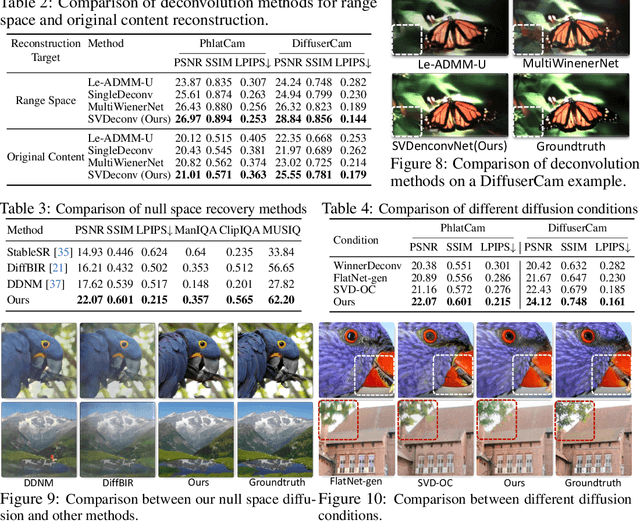
Lensless cameras offer significant advantages in size, weight, and cost compared to traditional lens-based systems. Without a focusing lens, lensless cameras rely on computational algorithms to recover the scenes from multiplexed measurements. However, current algorithms struggle with inaccurate forward imaging models and insufficient priors to reconstruct high-quality images. To overcome these limitations, we introduce a novel two-stage approach for consistent and photorealistic lensless image reconstruction. The first stage of our approach ensures data consistency by focusing on accurately reconstructing the low-frequency content with a spatially varying deconvolution method that adjusts to changes in the Point Spread Function (PSF) across the camera's field of view. The second stage enhances photorealism by incorporating a generative prior from pre-trained diffusion models. By conditioning on the low-frequency content retrieved in the first stage, the diffusion model effectively reconstructs the high-frequency details that are typically lost in the lensless imaging process, while also maintaining image fidelity. Our method achieves a superior balance between data fidelity and visual quality compared to existing methods, as demonstrated with two popular lensless systems, PhlatCam and DiffuserCam. Project website: https://phocolens.github.io/.
CMM-Math: A Chinese Multimodal Math Dataset To Evaluate and Enhance the Mathematics Reasoning of Large Multimodal Models
Sep 04, 2024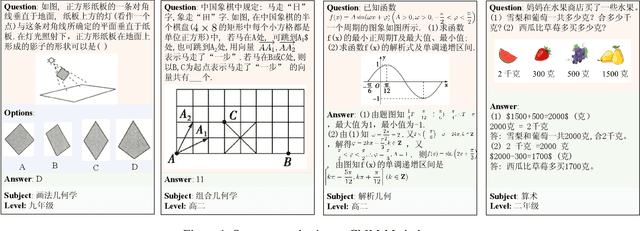
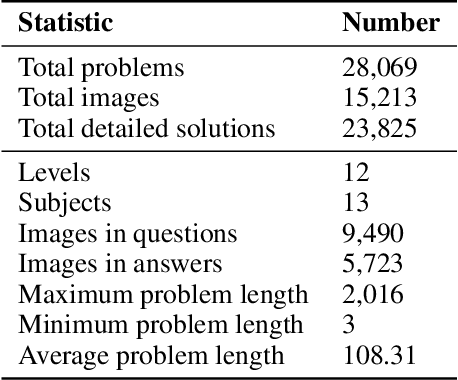
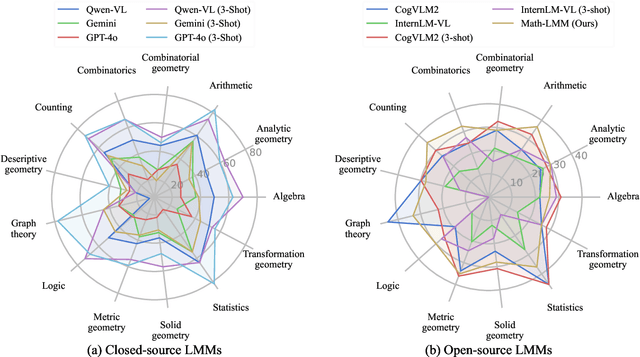
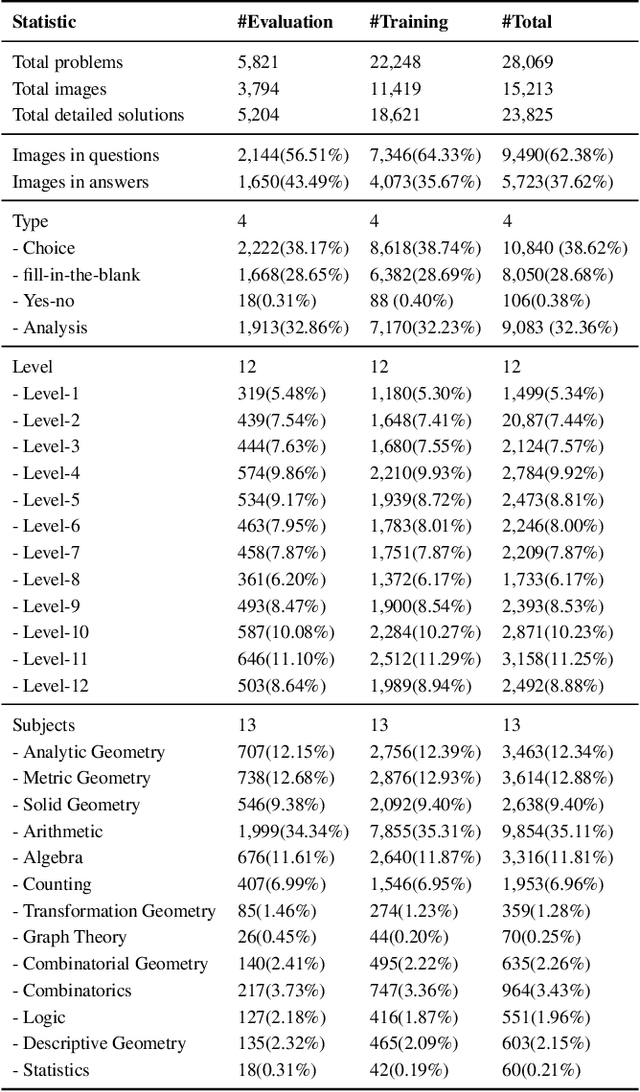
Large language models (LLMs) have obtained promising results in mathematical reasoning, which is a foundational skill for human intelligence. Most previous studies focus on improving and measuring the performance of LLMs based on textual math reasoning datasets (e.g., MATH, GSM8K). Recently, a few researchers have released English multimodal math datasets (e.g., MATHVISTA and MATH-V) to evaluate the effectiveness of large multimodal models (LMMs). In this paper, we release a Chinese multimodal math (CMM-Math) dataset, including benchmark and training parts, to evaluate and enhance the mathematical reasoning of LMMs. CMM-Math contains over 28,000 high-quality samples, featuring a variety of problem types (e.g., multiple-choice, fill-in-the-blank, and so on) with detailed solutions across 12 grade levels from elementary to high school in China. Specifically, the visual context may be present in the questions or opinions, which makes this dataset more challenging. Through comprehensive analysis, we discover that state-of-the-art LMMs on the CMM-Math dataset face challenges, emphasizing the necessity for further improvements in LMM development. We also propose a Multimodal Mathematical LMM (Math-LMM) to handle the problems with mixed input of multiple images and text segments. We train our model using three stages, including foundational pre-training, foundational fine-tuning, and mathematical fine-tuning. The extensive experiments indicate that our model effectively improves math reasoning performance by comparing it with the SOTA LMMs over three multimodal mathematical datasets.
CAS-ViT: Convolutional Additive Self-attention Vision Transformers for Efficient Mobile Applications
Aug 07, 2024



Vision Transformers (ViTs) mark a revolutionary advance in neural networks with their token mixer's powerful global context capability. However, the pairwise token affinity and complex matrix operations limit its deployment on resource-constrained scenarios and real-time applications, such as mobile devices, although considerable efforts have been made in previous works. In this paper, we introduce CAS-ViT: Convolutional Additive Self-attention Vision Transformers, to achieve a balance between efficiency and performance in mobile applications. Firstly, we argue that the capability of token mixers to obtain global contextual information hinges on multiple information interactions, such as spatial and channel domains. Subsequently, we construct a novel additive similarity function following this paradigm and present an efficient implementation named Convolutional Additive Token Mixer (CATM). This simplification leads to a significant reduction in computational overhead. We evaluate CAS-ViT across a variety of vision tasks, including image classification, object detection, instance segmentation, and semantic segmentation. Our experiments, conducted on GPUs, ONNX, and iPhones, demonstrate that CAS-ViT achieves a competitive performance when compared to other state-of-the-art backbones, establishing it as a viable option for efficient mobile vision applications. Our code and model are available at: \url{https://github.com/Tianfang-Zhang/CAS-ViT}