 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCFormer: Visual Recognition via Token Clustering Transformer
Paper and Code

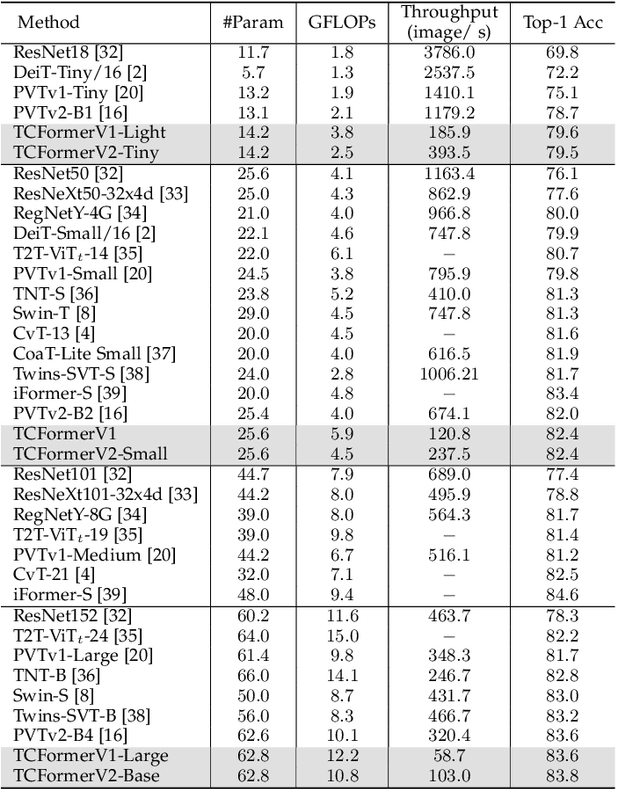
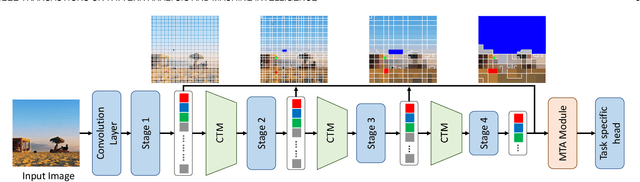
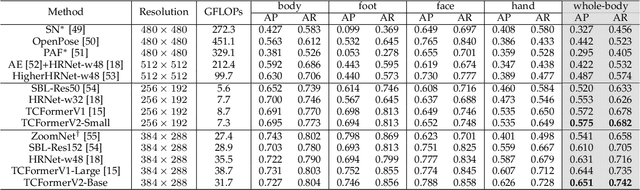
Transformers are widely used in computer vision areas and have achieved remarkable success. Most state-of-the-art approaches split images into regular grids and represent each grid region with a vision token. However, fixed token distribution disregards the semantic meaning of different image regions, resulting in sub-optimal performance. To address this issue, we propose the Token Clustering Transformer (TCFormer), which generates dynamic vision tokens based on semantic meaning. Our dynamic tokens possess two crucial characteristics: (1) Representing image regions with similar semantic meanings using the same vision token, even if those regions are not adjacent, and (2) concentrating on regions with valuable details and represent them using fine tokens. Through extensive experimentation across various applications, including image classification, human pose estimation, semantic segmentation, and object detection, we demonstrate the effectiveness of our TCFormer. The code and models for this work are available at https://github.com/zengwang430521/TCFormer.