 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNADER: Neural Architecture Design via Multi-Agent Collaboration
Dec 26, 2024



Designing effective neural architectures poses a significant challenge in deep learning. While Neural Architecture Search (NAS) automates the search for optimal architectures, existing methods are often constrained by predetermined search spaces and may miss critical neural architectures. In this paper, we introduce NADER (Neural Architecture Design via multi-agEnt collaboRation), a novel framework that formulates neural architecture design (NAD) as a LLM-based multi-agent collaboration problem. NADER employs a team of specialized agents to enhance a base architecture through iterative modification. Current LLM-based NAD methods typically operate independently, lacking the ability to learn from past experiences, which results in repeated mistakes and inefficient exploration. To address this issue, we propose the Reflector, which effectively learns from immediate feedback and long-term experiences. Additionally, unlike previous LLM-based methods that use code to represent neural architectures, we utilize a graph-based representation. This approach allows agents to focus on design aspects without being distracted by coding. We demonstrate the effectiveness of NADER in discovering high-performing architectures beyond predetermined search spaces through extensive experiments on benchmark tasks, showcasing its advantages over state-of-the-art methods. The codes will be released soon.
KptLLM: Unveiling the Power of Large Language Model for Keypoint Comprehension
Nov 04, 2024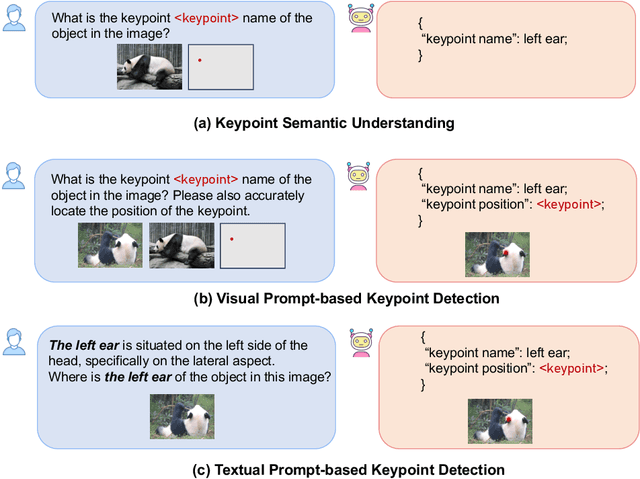



Recent advancements in Multimodal Large Language Models (MLLMs) have greatly improved their abilities in image understanding. However, these models often struggle with grasping pixel-level semantic details, e.g., the keypoints of an object. To bridge this gap, we introduce the novel challenge of Semantic Keypoint Comprehension, which aims to comprehend keypoints across different task scenarios, including keypoint semantic understanding, visual prompt-based keypoint detection, and textual prompt-based keypoint detection. Moreover, we introduce KptLLM, a unified multimodal model that utilizes an identify-then-detect strategy to effectively address these challenges. KptLLM underscores the initial discernment of semantics in keypoints, followed by the precise determination of their positions through a chain-of-thought process. With several carefully designed modules, KptLLM adeptly handles various modality inputs, facilitating the interpretation of both semantic contents and keypoint locations. Our extensive experiments demonstrate KptLLM's superiority in various keypoint detection benchmarks and its unique semantic capabilities in interpreting keypoints.
TCFormer: Visual Recognition via Token Clustering Transformer
Jul 16, 2024
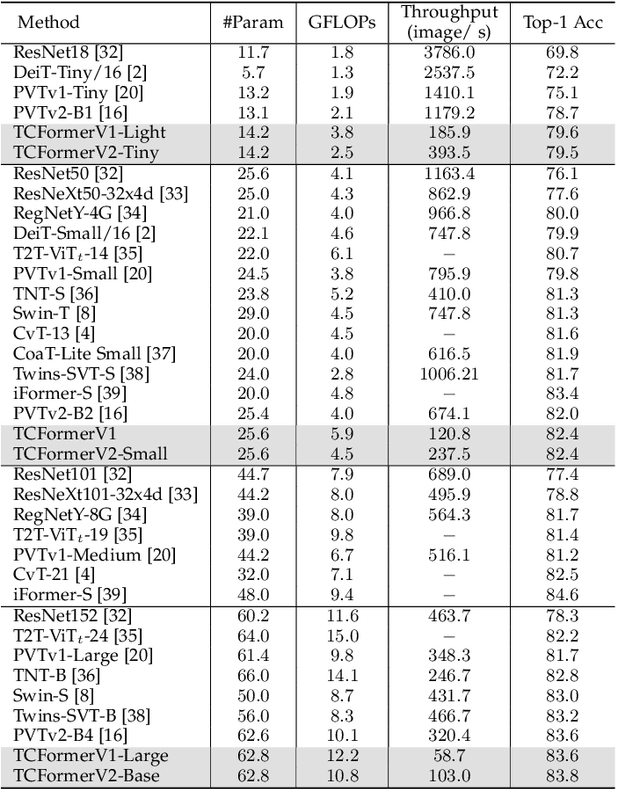
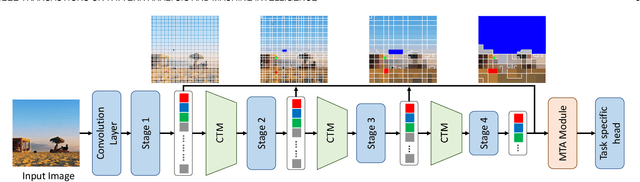
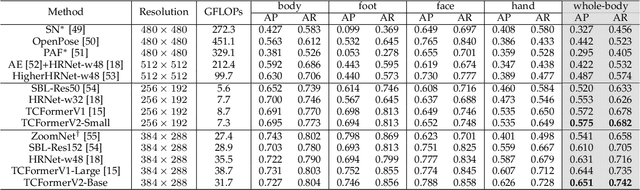
Transformers are widely used in computer vision areas and have achieved remarkable success. Most state-of-the-art approaches split images into regular grids and represent each grid region with a vision token. However, fixed token distribution disregards the semantic meaning of different image regions, resulting in sub-optimal performance. To address this issue, we propose the Token Clustering Transformer (TCFormer), which generates dynamic vision tokens based on semantic meaning. Our dynamic tokens possess two crucial characteristics: (1) Representing image regions with similar semantic meanings using the same vision token, even if those regions are not adjacent, and (2) concentrating on regions with valuable details and represent them using fine tokens. Through extensive experimentation across various applications, including image classification, human pose estimation, semantic segmentation, and object detection, we demonstrate the effectiveness of our TCFormer. The code and models for this work are available at https://github.com/zengwang430521/TCFormer.
When Pedestrian Detection Meets Multi-Modal Learning: Generalist Model and Benchmark Dataset
Jul 14, 2024Recent years have witnessed increasing research attention towards pedestrian detection by taking the advantages of different sensor modalities (e.g. RGB, IR, Depth, LiDAR and Event). However, designing a unified generalist model that can effectively process diverse sensor modalities remains a challenge. This paper introduces MMPedestron, a novel generalist model for multimodal perception. Unlike previous specialist models that only process one or a pair of specific modality inputs, MMPedestron is able to process multiple modal inputs and their dynamic combinations. The proposed approach comprises a unified encoder for modal representation and fusion and a general head for pedestrian detection. We introduce two extra learnable tokens, i.e. MAA and MAF, for adaptive multi-modal feature fusion. In addition, we construct the MMPD dataset, the first large-scale benchmark for multi-modal pedestrian detection. This benchmark incorporates existing public datasets and a newly collected dataset called EventPed, covering a wide range of sensor modalities including RGB, IR, Depth, LiDAR, and Event data. With multi-modal joint training, our model achieves state-of-the-art performance on a wide range of pedestrian detection benchmarks, surpassing leading models tailored for specific sensor modality. For example, it achieves 71.1 AP on COCO-Persons and 72.6 AP on LLVIP. Notably, our model achieves comparable performance to the InternImage-H model on CrowdHuman with 30x smaller parameters. Codes and data are available at https://github.com/BubblyYi/MMPedestron.
AutoMMLab: Automatically Generating Deployable Models from Language Instructions for Computer Vision Tasks
Feb 23, 2024



Automated machine learning (AutoML) is a collection of techniques designed to automate the machine learning development process. While traditional AutoML approaches have been successfully applied in several critical steps of model development (e.g. hyperparameter optimization), there lacks a AutoML system that automates the entire end-to-end model production workflow. To fill this blank, we present AutoMMLab, a general-purpose LLM-empowered AutoML system that follows user's language instructions to automate the whole model production workflow for computer vision tasks. The proposed AutoMMLab system effectively employs LLMs as the bridge to connect AutoML and OpenMMLab community, empowering non-expert individuals to easily build task-specific models via a user-friendly language interface. Specifically, we propose RU-LLaMA to understand users' request and schedule the whole pipeline, and propose a novel LLM-based hyperparameter optimizer called HPO-LLaMA to effectively search for the optimal hyperparameters. Experiments show that our AutoMMLab system is versatile and covers a wide range of mainstream tasks, including classification, detection, segmentation and keypoint estimation. We further develop a new benchmark, called LAMP, for studying key components in the end-to-end prompt-based model training pipeline. Code, model, and data will be released.
GKGNet: Group K-Nearest Neighbor based Graph Convolutional Network for Multi-Label Image Recognition
Aug 28, 2023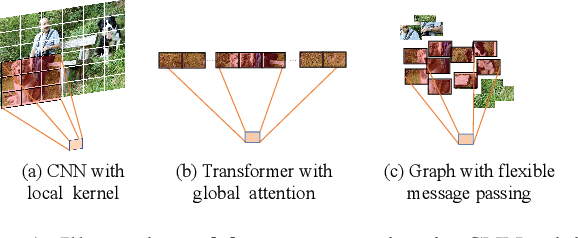

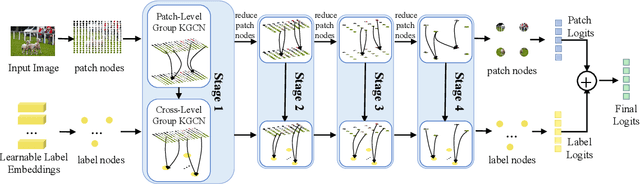

Multi-Label Image Recognition (MLIR) is a challenging task that aims to predict multiple object labels in a single image while modeling the complex relationships between labels and image regions. Although convolutional neural networks and vision transformers have succeeded in processing images as regular grids of pixels or patches, these representations are sub-optimal for capturing irregular and discontinuous regions of interest. In this work, we present the first fully graph convolutional model, Group K-nearest neighbor based Graph convolutional Network (GKGNet), which models the connections between semantic label embeddings and image patches in a flexible and unified graph structure. To address the scale variance of different objects and to capture information from multiple perspectives, we propose the Group KGCN module for dynamic graph construction and message passing. Our experiments demonstrate that GKGNet achieves state-of-the-art performance with significantly lower computational costs on the challenging multi-label datasets, \ie MS-COCO and VOC2007 datasets. We will release the code and models to facilitate future research in this area.
Pose for Everything: Towards Category-Agnostic Pose Estimation
Jul 21, 2022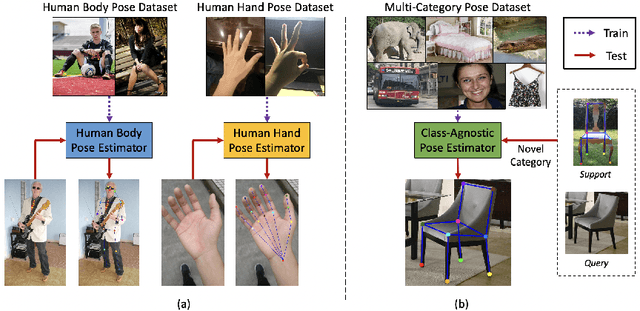
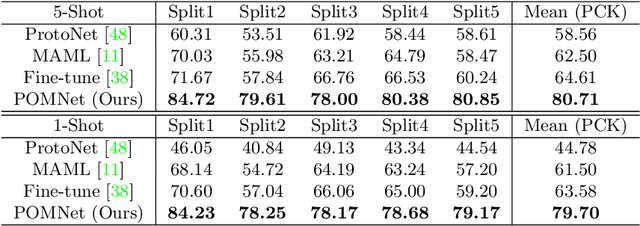

Existing works on 2D pose estimation mainly focus on a certain category, e.g. human, animal, and vehicle. However, there are lots of application scenarios that require detecting the poses/keypoints of the unseen class of objects. In this paper, we introduce the task of Category-Agnostic Pose Estimation (CAPE), which aims to create a pose estimation model capable of detecting the pose of any class of object given only a few samples with keypoint definition. To achieve this goal, we formulate the pose estimation problem as a keypoint matching problem and design a novel CAPE framework, termed POse Matching Network (POMNet). A transformer-based Keypoint Interaction Module (KIM) is proposed to capture both the interactions among different keypoints and the relationship between the support and query images. We also introduce Multi-category Pose (MP-100) dataset, which is a 2D pose dataset of 100 object categories containing over 20K instances and is well-designed for developing CAPE algorithms. Experiments show that our method outperforms other baseline approaches by a large margin. Codes and data are available at https://github.com/luminxu/Pose-for-Everything.
Not All Tokens Are Equal: Human-centric Visual Analysis via Token Clustering Transformer
Apr 21, 2022


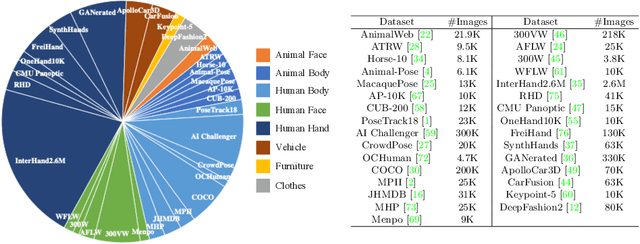
Vision transformers have achieved great successes in many computer vision tasks. Most methods generate vision tokens by splitting an image into a regular and fixed grid and treating each cell as a token. However, not all regions are equally important in human-centric vision tasks, e.g., the human body needs a fine representation with many tokens, while the image background can be modeled by a few tokens. To address this problem, we propose a novel Vision Transformer, called Token Clustering Transformer (TCFormer), which merges tokens by progressive clustering, where the tokens can be merged from different locations with flexible shapes and sizes. The tokens in TCFormer can not only focus on important areas but also adjust the token shapes to fit the semantic concept and adopt a fine resolution for regions containing critical details, which is beneficial to capturing detailed information. Extensive experiments show that TCFormer consistently outperforms its counterparts on different challenging human-centric tasks and datasets, including whole-body pose estimation on COCO-WholeBody and 3D human mesh reconstruction on 3DPW. Code is available at https://github.com/zengwang430521/TCFormer.git
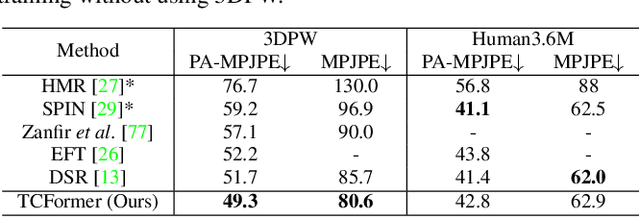
3D Human Mesh Regression with Dense Correspondence
Jun 10, 2020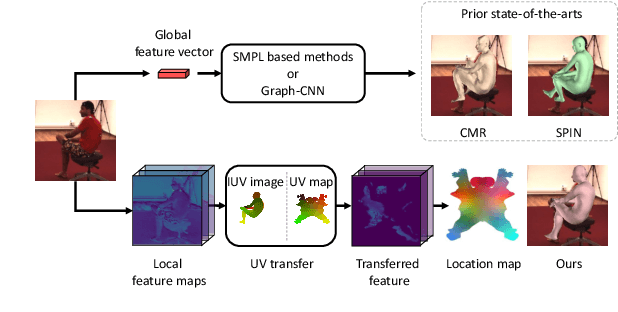

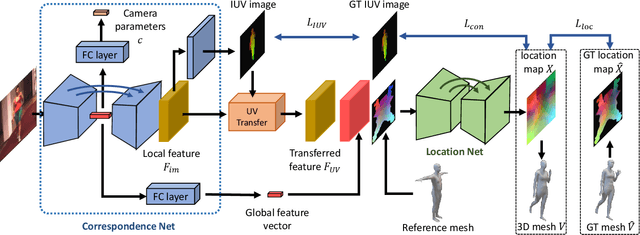
Estimating 3D mesh of the human body from a single 2D image is an important task with many applications such as augmented reality and Human-Robot interaction. However, prior works reconstructed 3D mesh from global image feature extracted by using convolutional neural network (CNN), where the dense correspondences between the mesh surface and the image pixels are missing, leading to suboptimal solution. This paper proposes a model-free 3D human mesh estimation framework, named DecoMR, which explicitly establishes the dense correspondence between the mesh and the local image features in the UV space (i.e. a 2D space used for texture mapping of 3D mesh). DecoMR first predicts pixel-to-surface dense correspondence map (i.e., IUV image), with which we transfer local features from the image space to the UV space. Then the transferred local image features are processed in the UV space to regress a location map, which is well aligned with transferred features. Finally we reconstruct 3D human mesh from the regressed location map with a predefined mapping function. We also observe that the existing discontinuous UV map are unfriendly to the learning of network. Therefore, we propose a novel UV map that maintains most of the neighboring relations on the original mesh surface. Experiments demonstrate that our proposed local feature alignment and continuous UV map outperforms existing 3D mesh based methods on multiple public benchmarks. Code will be made available at https://github.com/zengwang430521/DecoMR