 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-based Trial and Error Falls Behind in the Era of Experience
Jan 29, 2026While Large Language Models (LLMs) excel in language-based agentic tasks, their applicability to unseen, nonlinguistic environments (e.g., symbolic or spatial tasks) remains limited. Previous work attributes this performance gap to the mismatch between the pretraining distribution and the testing distribution. In this work, we demonstrate the primary bottleneck is the prohibitive cost of exploration: mastering these tasks requires extensive trial-and-error, which is computationally unsustainable for parameter-heavy LLMs operating in a high dimensional semantic space. To address this, we propose SCOUT (Sub-Scale Collaboration On Unseen Tasks), a novel framework that decouples exploration from exploitation. We employ lightweight "scouts" (e.g., small MLPs) to probe environmental dynamics at a speed and scale far exceeding LLMs. The collected trajectories are utilized to bootstrap the LLM via Supervised Fine-Tuning (SFT), followed by multi-turn Reinforcement Learning (RL) to activate its latent world knowledge. Empirically, SCOUT enables a Qwen2.5-3B-Instruct model to achieve an average score of 0.86, significantly outperforming proprietary models, including Gemini-2.5-Pro (0.60), while saving about 60% GPU hours consumption.
MonoMobility: Zero-Shot 3D Mobility Analysis from Monocular Videos
May 17, 2025Accurately analyzing the motion parts and their motion attributes in dynamic environments is crucial for advancing key areas such as embodied intelligence. Addressing the limitations of existing methods that rely on dense multi-view images or detailed part-level annotations, we propose an innovative framework that can analyze 3D mobility from monocular videos in a zero-shot manner. This framework can precisely parse motion parts and motion attributes only using a monocular video, completely eliminating the need for annotated training data. Specifically, our method first constructs the scene geometry and roughly analyzes the motion parts and their initial motion attributes combining depth estimation, optical flow analysis and point cloud registration method, then employs 2D Gaussian splatting for scene representation. Building on this, we introduce an end-to-end dynamic scene optimization algorithm specifically designed for articulated objects, refining the initial analysis results to ensure the system can handle 'rotation', 'translation', and even complex movements ('rotation+translation'), demonstrating high flexibility and versatility. To validate the robustness and wide applicability of our method, we created a comprehensive dataset comprising both simulated and real-world scenarios. Experimental results show that our framework can effectively analyze articulated object motions in an annotation-free manner, showcasing its significant potential in future embodied intelligence applications.
Generalized Derangetropy Functionals for Modeling Cyclical Information Flow
Apr 20, 2025This paper introduces a framework for modeling cyclical and feedback-driven information flow through a generalized family of entropy-modulated transformations called derangetropy functionals. Unlike scalar and static entropy measures such as Shannon entropy, these functionals act directly on probability densities and provide a topographical representation of information structure across the support of the distribution. The framework captures periodic and self-referential aspects of information distribution and encodes them through functional operators governed by nonlinear differential equations. When applied recursively, these operators induce a spectral diffusion process governed by the heat equation, leading to convergence toward a Gaussian characteristic function. This convergence theorem provides a unified analytical foundation for describing the long-term dynamics of information under cyclic modulation. The proposed framework offers new tools for analyzing the temporal evolution of information in systems characterized by periodic structure, stochastic feedback, and delayed interaction, with applications in artificial neural networks, communication theory, and non-equilibrium statistical mechanics.
3D Dental Model Segmentation with Geometrical Boundary Preserving
Mar 31, 20253D intraoral scan mesh is widely used in digital dentistry diagnosis, segmenting 3D intraoral scan mesh is a critical preliminary task. Numerous approaches have been devised for precise tooth segmentation. Currently, the deep learning-based methods are capable of the high accuracy segmentation of crown. However, the segmentation accuracy at the junction between the crown and the gum is still below average. Existing down-sampling methods are unable to effectively preserve the geometric details at the junction. To address these problems, we propose CrossTooth, a boundary-preserving segmentation method that combines 3D mesh selective downsampling to retain more vertices at the tooth-gingiva area, along with cross-modal discriminative boundary features extracted from multi-view rendered images, enhancing the geometric representation of the segmentation network. Using a point network as a backbone and incorporating image complementary features, CrossTooth significantly improves segmentation accuracy, as demonstrated by experiments on a public intraoral scan dataset.
Efficient and Interpretable Neural Networks Using Complex Lehmer Transform
Jan 25, 2025
We propose an efficient and interpretable neural network with a novel activation function called the weighted Lehmer transform. This new activation function enables adaptive feature selection and extends to the complex domain, capturing phase-sensitive and hierarchical relationships within data. Notably, it provides greater interpretability and transparency compared to existing machine learning models, facilitating a deeper understanding of its functionality and decision-making processes. We analyze the mathematical properties of both real-valued and complex-valued Lehmer activation units and demonstrate their applications in modeling nonlinear interactions. Empirical evaluations demonstrate that our proposed neural network achieves competitive accuracy on benchmark datasets with significantly improved computational efficiency. A single layer of real-valued or complex-valued Lehmer activation units is shown to deliver state-of-the-art performance, balancing efficiency with interpretability.
SynerGen-VL: Towards Synergistic Image Understanding and Generation with Vision Experts and Token Folding
Dec 12, 2024



The remarkable success of Large Language Models (LLMs) has extended to the multimodal domain, achieving outstanding performance in image understanding and generation. Recent efforts to develop unified Multimodal Large Language Models (MLLMs) that integrate these capabilities have shown promising results. However, existing approaches often involve complex designs in model architecture or training pipeline, increasing the difficulty of model training and scaling. In this paper, we propose SynerGen-VL, a simple yet powerful encoder-free MLLM capable of both image understanding and generation. To address challenges identified in existing encoder-free unified MLLMs, we introduce the token folding mechanism and the vision-expert-based progressive alignment pretraining strategy, which effectively support high-resolution image understanding while reducing training complexity. After being trained on large-scale mixed image-text data with a unified next-token prediction objective, SynerGen-VL achieves or surpasses the performance of existing encoder-free unified MLLMs with comparable or smaller parameter sizes, and narrows the gap with task-specific state-of-the-art models, highlighting a promising path toward future unified MLLMs. Our code and models shall be released.
TCFormer: Visual Recognition via Token Clustering Transformer
Jul 16, 2024
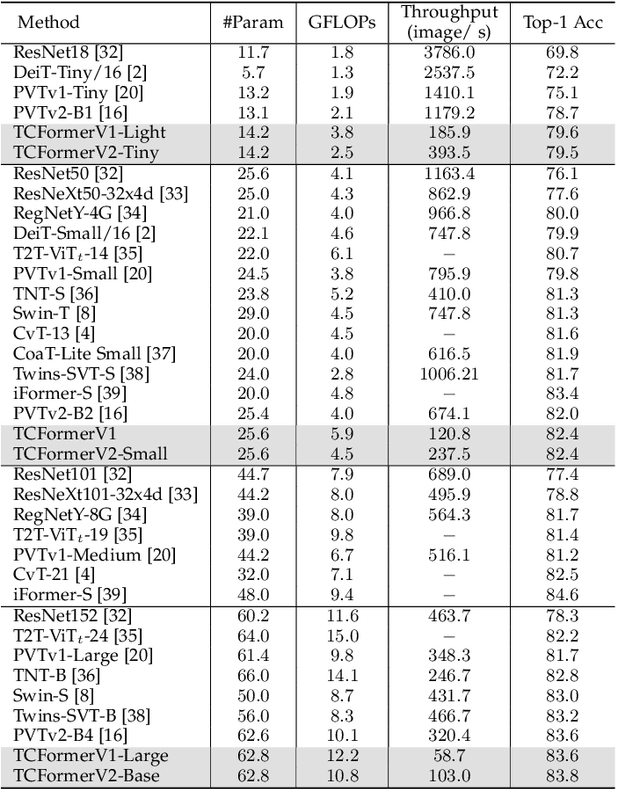
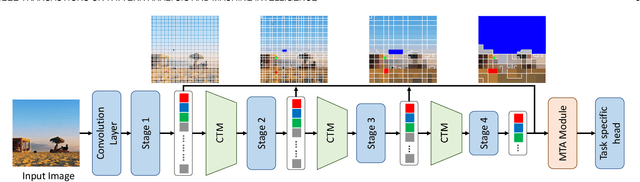
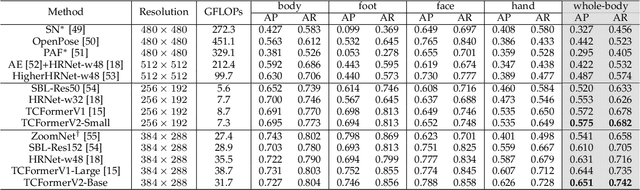
Transformers are widely used in computer vision areas and have achieved remarkable success. Most state-of-the-art approaches split images into regular grids and represent each grid region with a vision token. However, fixed token distribution disregards the semantic meaning of different image regions, resulting in sub-optimal performance. To address this issue, we propose the Token Clustering Transformer (TCFormer), which generates dynamic vision tokens based on semantic meaning. Our dynamic tokens possess two crucial characteristics: (1) Representing image regions with similar semantic meanings using the same vision token, even if those regions are not adjacent, and (2) concentrating on regions with valuable details and represent them using fine tokens. Through extensive experimentation across various applications, including image classification, human pose estimation, semantic segmentation, and object detection, we demonstrate the effectiveness of our TCFormer. The code and models for this work are available at https://github.com/zengwang430521/TCFormer.
Parametric Primitive Analysis of CAD Sketches with Vision Transformer
Jun 29, 2024



The design and analysis of Computer-Aided Design (CAD) sketches play a crucial role in industrial product design, primarily involving CAD primitives and their inter-primitive constraints. To address challenges related to error accumulation in autoregressive models and the complexities associated with self-supervised model design for this task, we propose a two-stage network framework. This framework consists of a primitive network and a constraint network, transforming the sketch analysis task into a set prediction problem to enhance the effective handling of primitives and constraints. By decoupling target types from parameters, the model gains increased flexibility and optimization while reducing complexity. Additionally, the constraint network incorporates a pointer module to explicitly indicate the relationship between constraint parameters and primitive indices, enhancing interpretability and performance. Qualitative and quantitative analyses on two publicly available datasets demonstrate the superiority of this method.
FaceCom: Towards High-fidelity 3D Facial Shape Completion via Optimization and Inpainting Guidance
Jun 04, 2024We propose FaceCom, a method for 3D facial shape completion, which delivers high-fidelity results for incomplete facial inputs of arbitrary forms. Unlike end-to-end shape completion methods based on point clouds or voxels, our approach relies on a mesh-based generative network that is easy to optimize, enabling it to handle shape completion for irregular facial scans. We first train a shape generator on a mixed 3D facial dataset containing 2405 identities. Based on the incomplete facial input, we fit complete faces using an optimization approach under image inpainting guidance. The completion results are refined through a post-processing step. FaceCom demonstrates the ability to effectively and naturally complete facial scan data with varying missing regions and degrees of missing areas. Our method can be used in medical prosthetic fabrication and the registration of deficient scanning data. Our experimental results demonstrate that FaceCom achieves exceptional performance in fitting and shape completion tasks. The code is available at https://github.com/dragonylee/FaceCom.git.
Phased Consistency Model
May 28, 2024The consistency model (CM) has recently made significant progress in accelerating the generation of diffusion models. However, its application to high-resolution, text-conditioned image generation in the latent space (a.k.a., LCM) remains unsatisfactory. In this paper, we identify three key flaws in the current design of LCM. We investigate the reasons behind these limitations and propose the Phased Consistency Model (PCM), which generalizes the design space and addresses all identified limitations. Our evaluations demonstrate that PCM significantly outperforms LCM across 1--16 step generation settings. While PCM is specifically designed for multi-step refinement, it achieves even superior or comparable 1-step generation results to previously state-of-the-art specifically designed 1-step methods. Furthermore, we show that PCM's methodology is versatile and applicable to video generation, enabling us to train the state-of-the-art few-step text-to-video generator. More details are available at https://g-u-n.github.io/projects/pcm/.