 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Dental Model Segmentation with Geometrical Boundary Preserving
Mar 31, 20253D intraoral scan mesh is widely used in digital dentistry diagnosis, segmenting 3D intraoral scan mesh is a critical preliminary task. Numerous approaches have been devised for precise tooth segmentation. Currently, the deep learning-based methods are capable of the high accuracy segmentation of crown. However, the segmentation accuracy at the junction between the crown and the gum is still below average. Existing down-sampling methods are unable to effectively preserve the geometric details at the junction. To address these problems, we propose CrossTooth, a boundary-preserving segmentation method that combines 3D mesh selective downsampling to retain more vertices at the tooth-gingiva area, along with cross-modal discriminative boundary features extracted from multi-view rendered images, enhancing the geometric representation of the segmentation network. Using a point network as a backbone and incorporating image complementary features, CrossTooth significantly improves segmentation accuracy, as demonstrated by experiments on a public intraoral scan dataset.
FaceCom: Towards High-fidelity 3D Facial Shape Completion via Optimization and Inpainting Guidance
Jun 04, 2024We propose FaceCom, a method for 3D facial shape completion, which delivers high-fidelity results for incomplete facial inputs of arbitrary forms. Unlike end-to-end shape completion methods based on point clouds or voxels, our approach relies on a mesh-based generative network that is easy to optimize, enabling it to handle shape completion for irregular facial scans. We first train a shape generator on a mixed 3D facial dataset containing 2405 identities. Based on the incomplete facial input, we fit complete faces using an optimization approach under image inpainting guidance. The completion results are refined through a post-processing step. FaceCom demonstrates the ability to effectively and naturally complete facial scan data with varying missing regions and degrees of missing areas. Our method can be used in medical prosthetic fabrication and the registration of deficient scanning data. Our experimental results demonstrate that FaceCom achieves exceptional performance in fitting and shape completion tasks. The code is available at https://github.com/dragonylee/FaceCom.git.
Colorectal Polyp Segmentation in the Deep Learning Era: A Comprehensive Survey
Jan 22, 2024Colorectal polyp segmentation (CPS), an essential problem in medical image analysis, has garnered growing research attention. Recently, the deep learning-based model completely overwhelmed traditional methods in the field of CPS, and more and more deep CPS methods have emerged, bringing the CPS into the deep learning era. To help the researchers quickly grasp the main techniques, datasets, evaluation metrics, challenges, and trending of deep CPS, this paper presents a systematic and comprehensive review of deep-learning-based CPS methods from 2014 to 2023, a total of 115 technical papers. In particular, we first provide a comprehensive review of the current deep CPS with a novel taxonomy, including network architectures, level of supervision, and learning paradigm. More specifically, network architectures include eight subcategories, the level of supervision comprises six subcategories, and the learning paradigm encompasses 12 subcategories, totaling 26 subcategories. Then, we provided a comprehensive analysis the characteristics of each dataset, including the number of datasets, annotation types, image resolution, polyp size, contrast values, and polyp location. Following that, we summarized CPS's commonly used evaluation metrics and conducted a detailed analysis of 40 deep SOTA models, including out-of-distribution generalization and attribute-based performance analysis. Finally, we discussed deep learning-based CPS methods' main challenges and opportunities.
WinDB: HMD-free and Distortion-free Panoptic Video Fixation Learning
May 23, 2023To date, the widely-adopted way to perform fixation collection in panoptic video is based on a head-mounted display (HMD), where participants' fixations are collected while wearing an HMD to explore the given panoptic scene freely. However, this widely-used data collection method is insufficient for training deep models to accurately predict which regions in a given panoptic are most important when it contains intermittent salient events. The main reason is that there always exist "blind zooms" when using HMD to collect fixations since the participants cannot keep spinning their heads to explore the entire panoptic scene all the time. Consequently, the collected fixations tend to be trapped in some local views, leaving the remaining areas to be the "blind zooms". Therefore, fixation data collected using HMD-based methods that accumulate local views cannot accurately represent the overall global importance of complex panoramic scenes. This paper introduces the auxiliary Window with a Dynamic Blurring (WinDB) fixation collection approach for panoptic video, which doesn't need HMD and is blind-zoom-free. Thus, the collected fixations can well reflect the regional-wise importance degree. Using our WinDB approach, we have released a new PanopticVideo-300 dataset, containing 300 panoptic clips covering over 225 categories. Besides, we have presented a simple baseline design to take full advantage of PanopticVideo-300 to handle the blind-zoom-free attribute-induced fixation shifting problem. Our WinDB approach, PanopticVideo-300, and tailored fixation prediction model are all publicly available at https://github.com/360submit/WinDB.
Pixel is All You Need: Adversarial Trajectory-Ensemble Active Learning for Salient Object Detection
Dec 13, 2022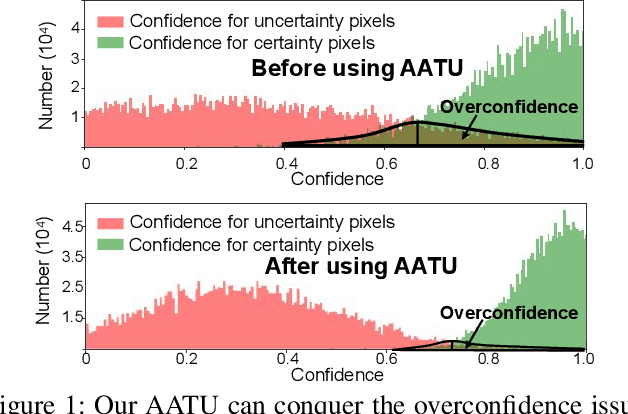
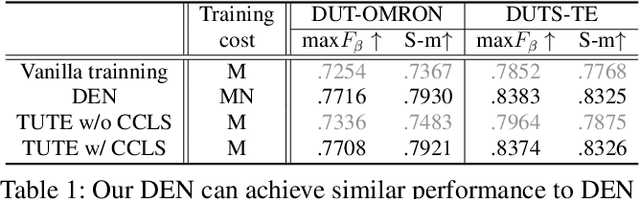
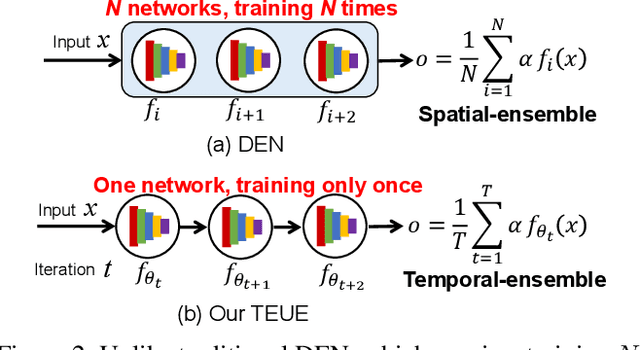
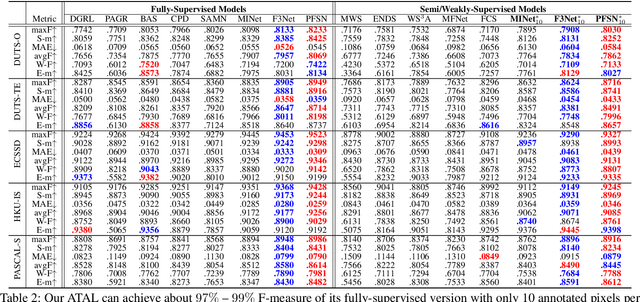
Although weakly-supervised techniques can reduce the labeling effort, it is unclear whether a saliency model trained with weakly-supervised data (e.g., point annotation) can achieve the equivalent performance of its fully-supervised version. This paper attempts to answer this unexplored question by proving a hypothesis: there is a point-labeled dataset where saliency models trained on it can achieve equivalent performance when trained on the densely annotated dataset. To prove this conjecture, we proposed a novel yet effective adversarial trajectory-ensemble active learning (ATAL). Our contributions are three-fold: 1) Our proposed adversarial attack triggering uncertainty can conquer the overconfidence of existing active learning methods and accurately locate these uncertain pixels. {2)} Our proposed trajectory-ensemble uncertainty estimation method maintains the advantages of the ensemble networks while significantly reducing the computational cost. {3)} Our proposed relationship-aware diversity sampling algorithm can conquer oversampling while boosting performance. Experimental results show that our ATAL can find such a point-labeled dataset, where a saliency model trained on it obtained $97\%$ -- $99\%$ performance of its fully-supervised version with only ten annotated points per image.
* 9 pages, 8 figures
Synthetic Data Supervised Salient Object Detection
Oct 25, 2022
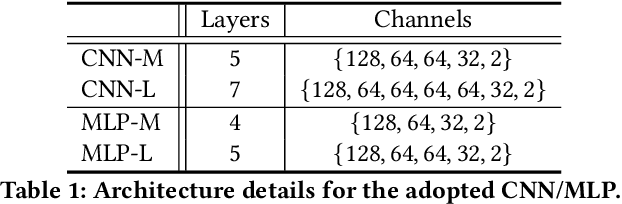
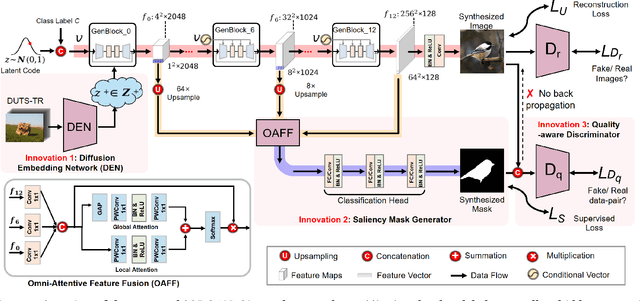
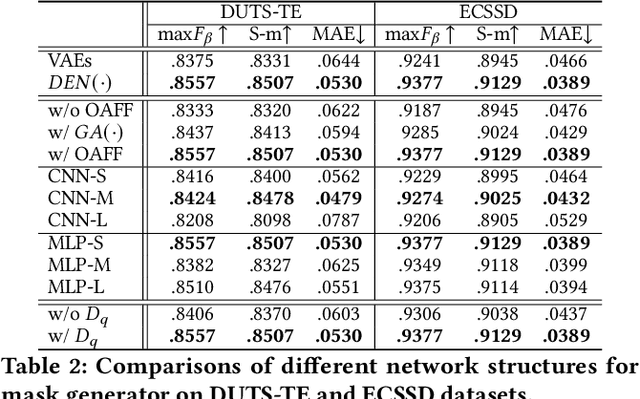
Although deep salient object detection (SOD) has achieved remarkable progress, deep SOD models are extremely data-hungry, requiring large-scale pixel-wise annotations to deliver such promising results. In this paper, we propose a novel yet effective method for SOD, coined SODGAN, which can generate infinite high-quality image-mask pairs requiring only a few labeled data, and these synthesized pairs can replace the human-labeled DUTS-TR to train any off-the-shelf SOD model. Its contribution is three-fold. 1) Our proposed diffusion embedding network can address the manifold mismatch and is tractable for the latent code generation, better matching with the ImageNet latent space. 2) For the first time, our proposed few-shot saliency mask generator can synthesize infinite accurate image synchronized saliency masks with a few labeled data. 3) Our proposed quality-aware discriminator can select highquality synthesized image-mask pairs from noisy synthetic data pool, improving the quality of synthetic data. For the first time, our SODGAN tackles SOD with synthetic data directly generated from the generative model, which opens up a new research paradigm for SOD. Extensive experimental results show that the saliency model trained on synthetic data can achieve $98.4\%$ F-measure of the saliency model trained on the DUTS-TR. Moreover, our approach achieves a new SOTA performance in semi/weakly-supervised methods, and even outperforms several fully-supervised SOTA methods. Code is available at https://github.com/wuzhenyubuaa/SODGAN
* 9 pages, 8 figures
Salient Object Detection via Dynamic Scale Routing
Oct 25, 2022



Recent research advances in salient object detection (SOD) could largely be attributed to ever-stronger multi-scale feature representation empowered by the deep learning technologies. The existing SOD deep models extract multi-scale features via the off-the-shelf encoders and combine them smartly via various delicate decoders. However, the kernel sizes in this commonly-used thread are usually "fixed". In our new experiments, we have observed that kernels of small size are preferable in scenarios containing tiny salient objects. In contrast, large kernel sizes could perform better for images with large salient objects. Inspired by this observation, we advocate the "dynamic" scale routing (as a brand-new idea) in this paper. It will result in a generic plug-in that could directly fit the existing feature backbone. This paper's key technical innovations are two-fold. First, instead of using the vanilla convolution with fixed kernel sizes for the encoder design, we propose the dynamic pyramid convolution (DPConv), which dynamically selects the best-suited kernel sizes w.r.t. the given input. Second, we provide a self-adaptive bidirectional decoder design to accommodate the DPConv-based encoder best. The most significant highlight is its capability of routing between feature scales and their dynamic collection, making the inference process scale-aware. As a result, this paper continues to enhance the current SOTA performance. Both the code and dataset are publicly available at https://github.com/wuzhenyubuaa/DPNet.
* 15 pages, 15 figures
Weakly Supervised Visual-Auditory Saliency Detection with Multigranularity Perception
Jan 01, 2022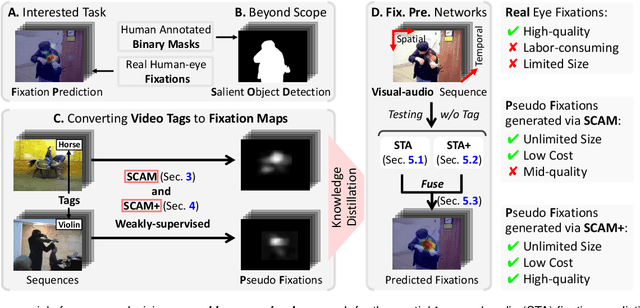
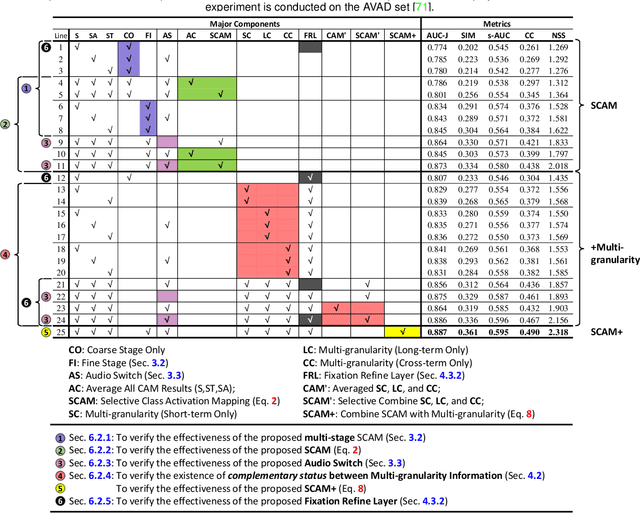
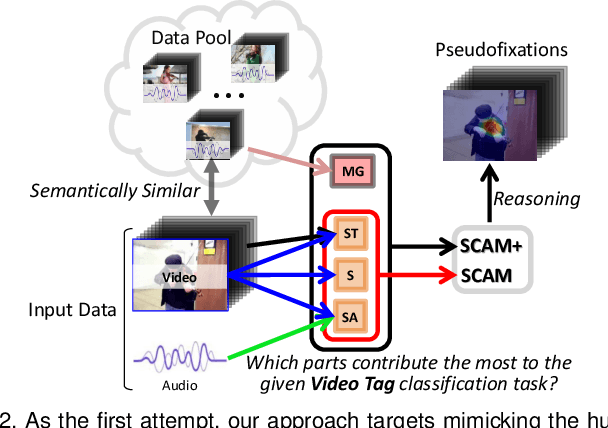
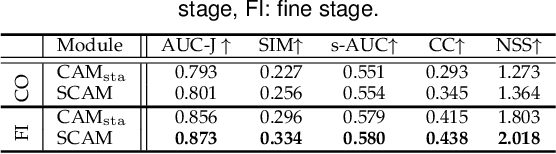
Thanks to the rapid advances in deep learning techniques and the wide availability of large-scale training sets, the performance of video saliency detection models has been improving steadily and significantly. However, deep learning-based visualaudio fixation prediction is still in its infancy. At present, only a few visual-audio sequences have been furnished, with real fixations being recorded in real visual-audio environments. Hence, it would be neither efficient nor necessary to recollect real fixations under the same visual-audio circumstances. To address this problem, this paper promotes a novel approach in a weakly supervised manner to alleviate the demand of large-scale training sets for visual-audio model training. By using only the video category tags, we propose the selective class activation mapping (SCAM) and its upgrade (SCAM+). In the spatial-temporal-audio circumstance, the former follows a coarse-to-fine strategy to select the most discriminative regions, and these regions are usually capable of exhibiting high consistency with the real human-eye fixations. The latter equips the SCAM with an additional multi-granularity perception mechanism, making the whole process more consistent with that of the real human visual system. Moreover, we distill knowledge from these regions to obtain complete new spatial-temporal-audio (STA) fixation prediction (FP) networks, enabling broad applications in cases where video tags are not available. Without resorting to any real human-eye fixation, the performances of these STA FP networks are comparable to those of fully supervised networks. The code and results are publicly available at https://github.com/guotaowang/STANet.
Rethinking of the Image Salient Object Detection: Object-level Semantic Saliency Re-ranking First, Pixel-wise Saliency Refinement Latter
Aug 10, 2020
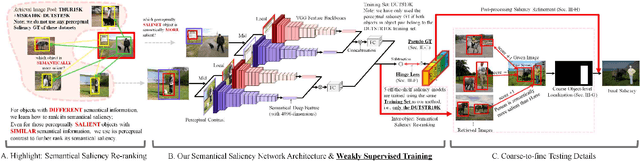


The real human attention is an interactive activity between our visual system and our brain, using both low-level visual stimulus and high-level semantic information. Previous image salient object detection (SOD) works conduct their saliency predictions in a multi-task manner, i.e., performing pixel-wise saliency regression and segmentation-like saliency refinement at the same time, which degenerates their feature backbones in revealing semantic information. However, given an image, we tend to pay more attention to those regions which are semantically salient even in the case that these regions are perceptually not the most salient ones at first glance. In this paper, we divide the SOD problem into two sequential tasks: 1) we propose a lightweight, weakly supervised deep network to coarsely locate those semantically salient regions first; 2) then, as a post-processing procedure, we selectively fuse multiple off-the-shelf deep models on these semantically salient regions as the pixel-wise saliency refinement. In sharp contrast to the state-of-the-art (SOTA) methods that focus on learning pixel-wise saliency in "single image" using perceptual clues mainly, our method has investigated the "object-level semantic ranks between multiple images", of which the methodology is more consistent with the real human attention mechanism. Our method is simple yet effective, which is the first attempt to consider the salient object detection mainly as an object-level semantic re-ranking problem.
Knowing Depth Quality In Advance: A Depth Quality Assessment Method For RGB-D Salient Object Detection
Aug 07, 2020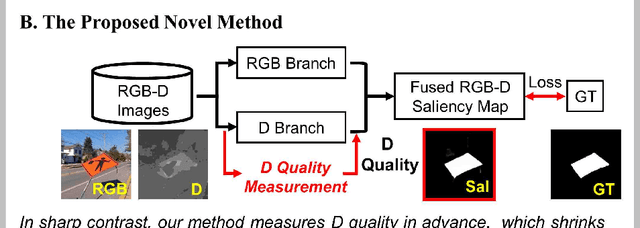
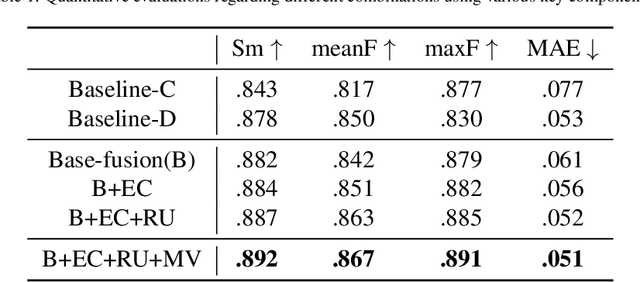
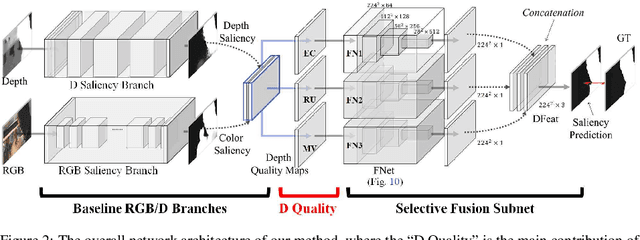
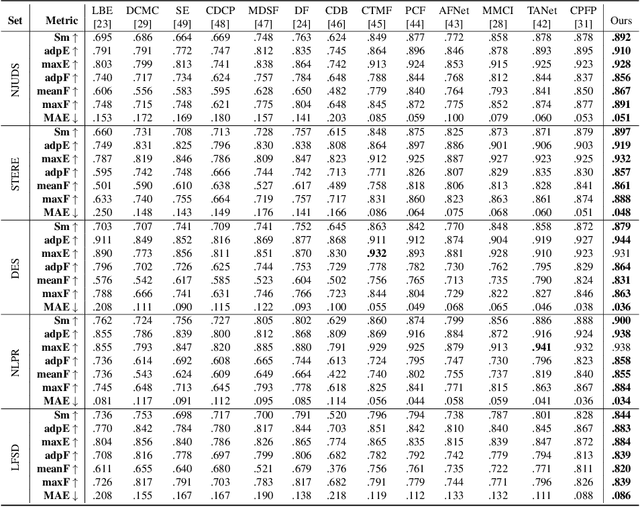
Previous RGB-D salient object detection (SOD) methods have widely adopted deep learning tools to automatically strike a trade-off between RGB and D (depth), whose key rationale is to take full advantage of their complementary nature, aiming for a much-improved SOD performance than that of using either of them solely. However, such fully automatic fusions may not always be helpful for the SOD task because the D quality itself usually varies from scene to scene. It may easily lead to a suboptimal fusion result if the D quality is not considered beforehand. Moreover, as an objective factor, the D quality has long been overlooked by previous work. As a result, it is becoming a clear performance bottleneck. Thus, we propose a simple yet effective scheme to measure D quality in advance, the key idea of which is to devise a series of features in accordance with the common attributes of high-quality D regions. To be more concrete, we conduct D quality assessments for each image region, following a multi-scale methodology that includes low-level edge consistency, mid-level regional uncertainty and high-level model variance. All these components will be computed independently and then be assembled with RGB and D features, applied as implicit indicators, to guide the selective fusion. Compared with the state-of-the-art fusion schemes, our method can achieve a more reasonable fusion status between RGB and D. Specifically, the proposed D quality measurement method achieves steady performance improvements for almost 2.0\% in general.