 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Combined Data-Driven Approach for Electricity Theft Detection
Nov 11, 2024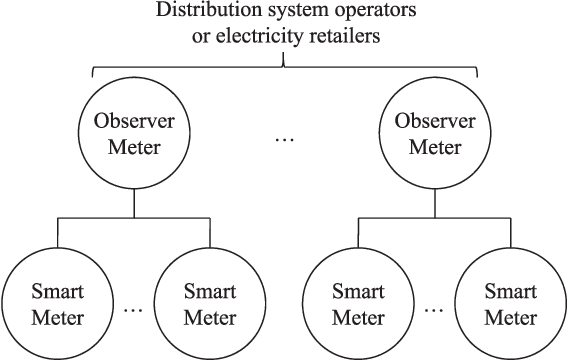
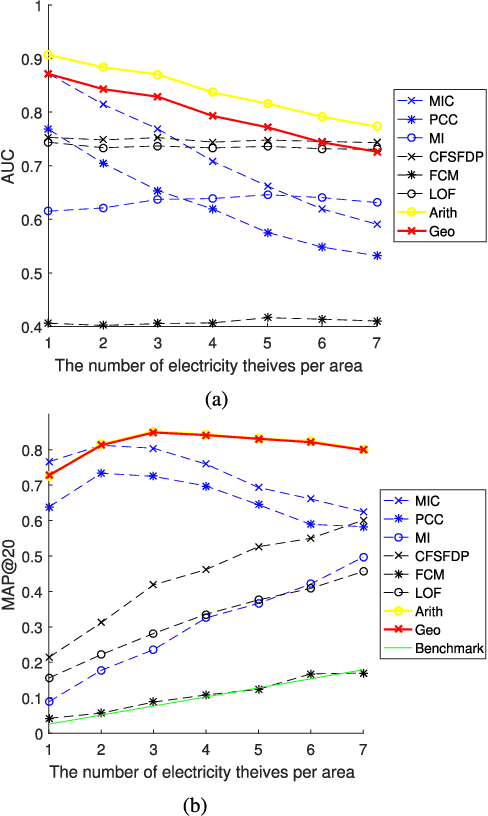
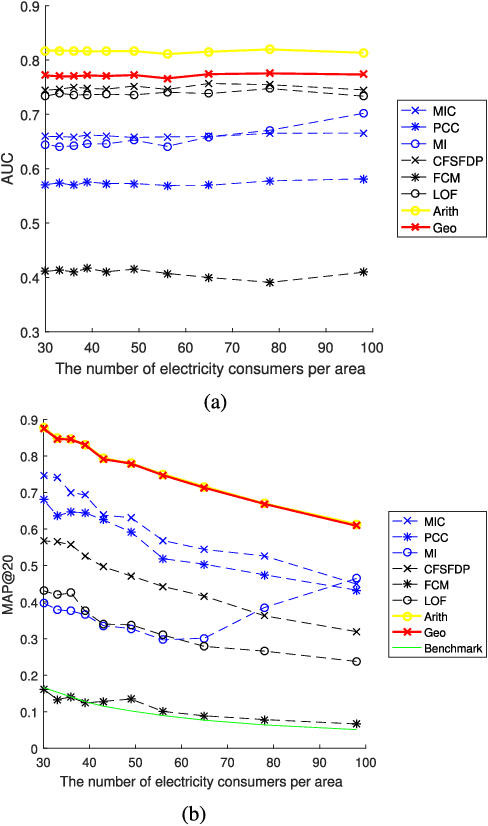
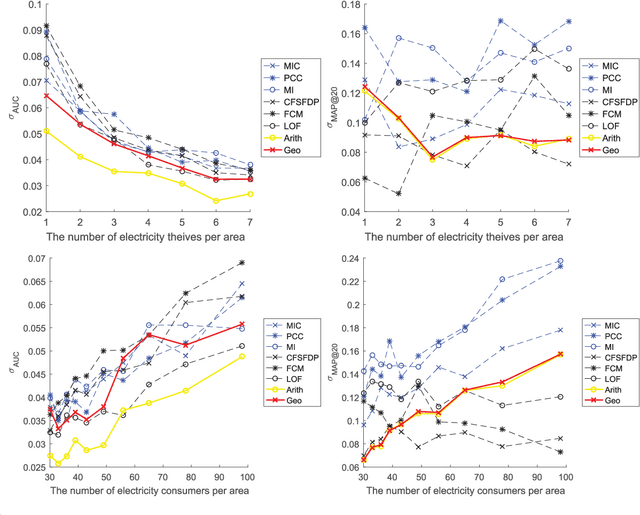
The two-way flow of information and energy is an important feature of the Energy Internet. Data analytics is a powerful tool in the information flow that aims to solve practical problems using data mining techniques. As the problem of electricity thefts via tampering with smart meters continues to increase, the abnormal behaviors of thefts become more diversified and more difficult to detect. Thus, a data analytics method for detecting various types of electricity thefts is required. However, the existing methods either require a labeled dataset or additional system information which is difficult to obtain in reality or have poor detection accuracy. In this paper, we combine two novel data mining techniques to solve the problem. One technique is the Maximum Information Coefficient (MIC), which can find the correlations between the non-technical loss (NTL) and a certain electricity behavior of the consumer. MIC can be used to precisely detect thefts that appear normal in shapes. The other technique is the clustering technique by fast search and find of density peaks (CFSFDP). CFSFDP finds the abnormal users among thousands of load profiles, making it quite suitable for detecting electricity thefts with arbitrary shapes. Next, a framework for combining the advantages of the two techniques is proposed. Numerical experiments on the Irish smart meter dataset are conducted to show the good performance of the combined method.
* Paper accepted for IEEE Transactions on Industrial Informatics. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses
Voxel2Hemodynamics: An End-to-end Deep Learning Method for Predicting Coronary Artery Hemodynamics
May 30, 2023Local hemodynamic forces play an important role in determining the functional significance of coronary arterial stenosis and understanding the mechanism of coronary disease progression. Computational fluid dynamics (CFD) have been widely performed to simulate hemodynamics non-invasively from coronary computed tomography angiography (CCTA) images. However, accurate computational analysis is still limited by the complex construction of patient-specific modeling and time-consuming computation. In this work, we proposed an end-to-end deep learning framework, which could predict the coronary artery hemodynamics from CCTA images. The model was trained on the hemodynamic data obtained from 3D simulations of synthetic and real datasets. Extensive experiments demonstrated that the predicted hemdynamic distributions by our method agreed well with the CFD-derived results. Quantitatively, the proposed method has the capability of predicting the fractional flow reserve with an average error of 0.5\% and 2.5\% for the synthetic dataset and real dataset, respectively. Particularly, our method achieved much better accuracy for the real dataset compared to PointNet++ with the point cloud input. This study demonstrates the feasibility and great potential of our end-to-end deep learning method as a fast and accurate approach for hemodynamic analysis.
Segmentation and Vascular Vectorization for Coronary Artery by Geometry-based Cascaded Neural Network
May 07, 2023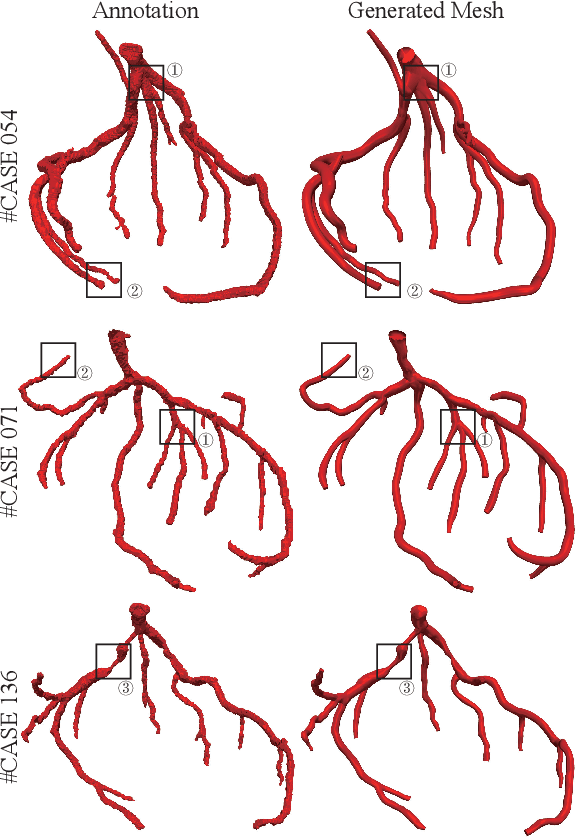
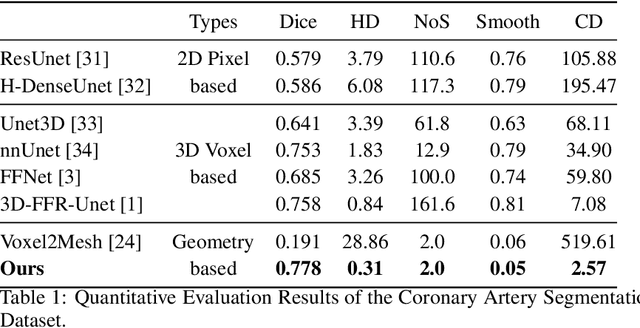
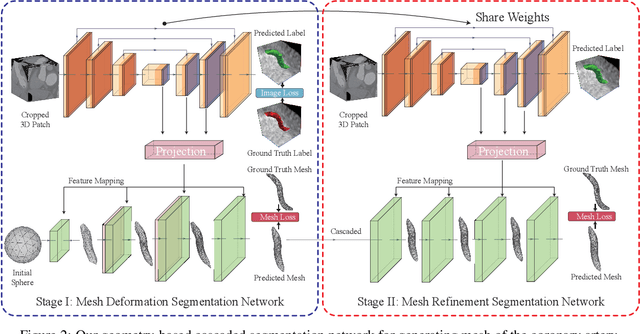

Segmentation of the coronary artery is an important task for the quantitative analysis of coronary computed tomography angiography (CCTA) images and is being stimulated by the field of deep learning. However, the complex structures with tiny and narrow branches of the coronary artery bring it a great challenge. Coupled with the medical image limitations of low resolution and poor contrast, fragmentations of segmented vessels frequently occur in the prediction. Therefore, a geometry-based cascaded segmentation method is proposed for the coronary artery, which has the following innovations: 1) Integrating geometric deformation networks, we design a cascaded network for segmenting the coronary artery and vectorizing results. The generated meshes of the coronary artery are continuous and accurate for twisted and sophisticated coronary artery structures, without fragmentations. 2) Different from mesh annotations generated by the traditional marching cube method from voxel-based labels, a finer vectorized mesh of the coronary artery is reconstructed with the regularized morphology. The novel mesh annotation benefits the geometry-based segmentation network, avoiding bifurcation adhesion and point cloud dispersion in intricate branches. 3) A dataset named CCA-200 is collected, consisting of 200 CCTA images with coronary artery disease. The ground truths of 200 cases are coronary internal diameter annotations by professional radiologists. Extensive experiments verify our method on our collected dataset CCA-200 and public ASOCA dataset, with a Dice of 0.778 on CCA-200 and 0.895 on ASOCA, showing superior results. Especially, our geometry-based model generates an accurate, intact and smooth coronary artery, devoid of any fragmentations of segmented vessels.
Pixel is All You Need: Adversarial Trajectory-Ensemble Active Learning for Salient Object Detection
Dec 13, 2022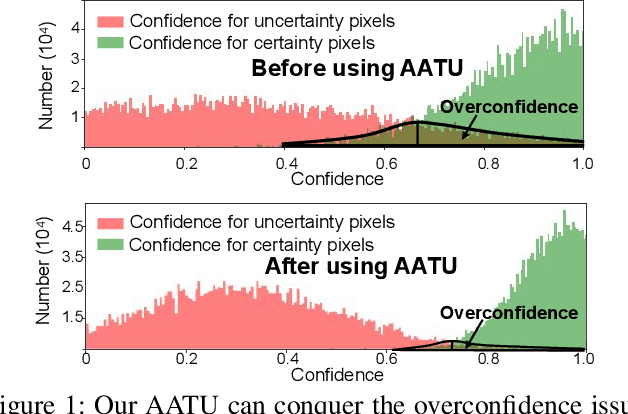
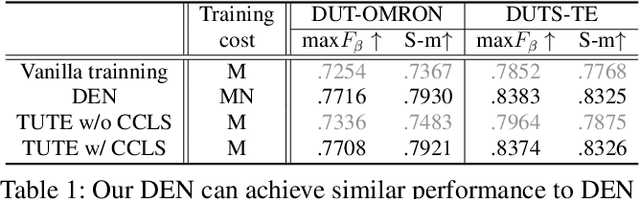
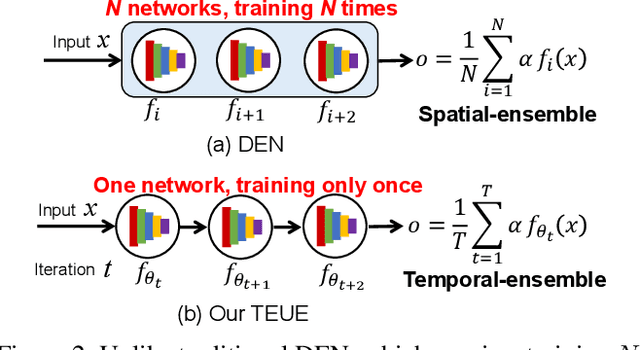
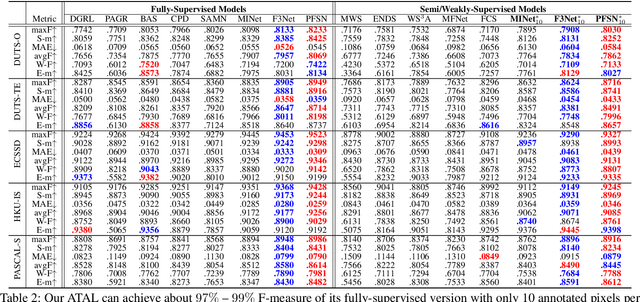
Although weakly-supervised techniques can reduce the labeling effort, it is unclear whether a saliency model trained with weakly-supervised data (e.g., point annotation) can achieve the equivalent performance of its fully-supervised version. This paper attempts to answer this unexplored question by proving a hypothesis: there is a point-labeled dataset where saliency models trained on it can achieve equivalent performance when trained on the densely annotated dataset. To prove this conjecture, we proposed a novel yet effective adversarial trajectory-ensemble active learning (ATAL). Our contributions are three-fold: 1) Our proposed adversarial attack triggering uncertainty can conquer the overconfidence of existing active learning methods and accurately locate these uncertain pixels. {2)} Our proposed trajectory-ensemble uncertainty estimation method maintains the advantages of the ensemble networks while significantly reducing the computational cost. {3)} Our proposed relationship-aware diversity sampling algorithm can conquer oversampling while boosting performance. Experimental results show that our ATAL can find such a point-labeled dataset, where a saliency model trained on it obtained $97\%$ -- $99\%$ performance of its fully-supervised version with only ten annotated points per image.
* 9 pages, 8 figures
Improving Sample Efficiency of Deep Learning Models in Electricity Market
Oct 11, 2022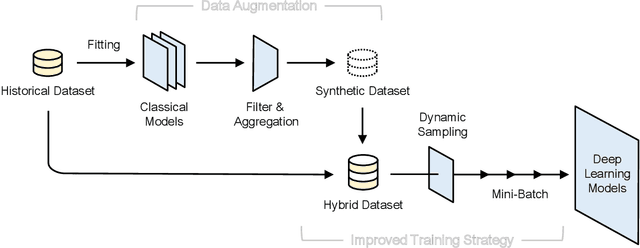
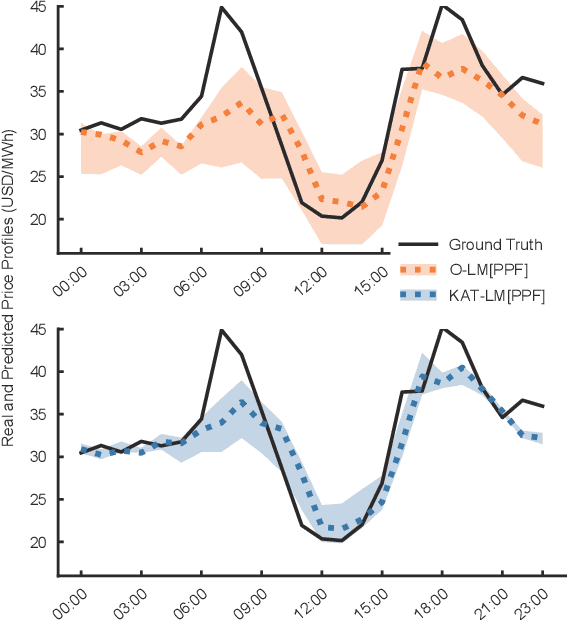
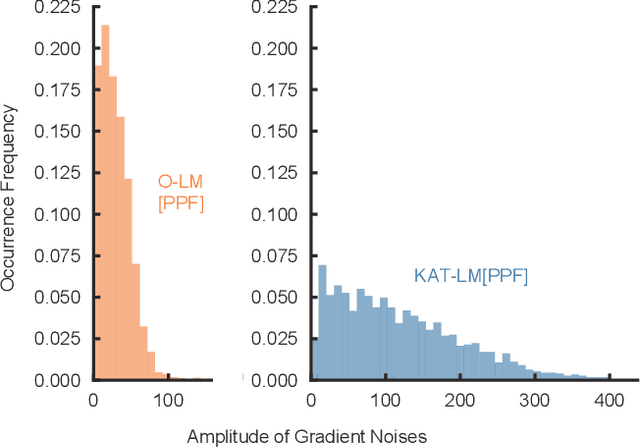
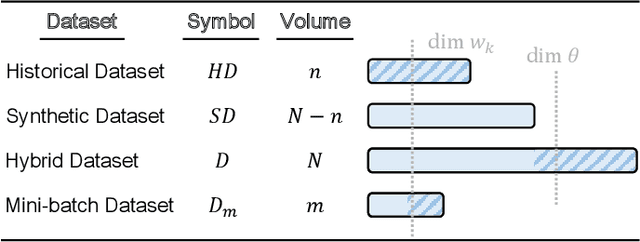
The superior performance of deep learning relies heavily on a large collection of sample data, but the data insufficiency problem turns out to be relatively common in global electricity markets. How to prevent overfitting in this case becomes a fundamental challenge when training deep learning models in different market applications. With this in mind, we propose a general framework, namely Knowledge-Augmented Training (KAT), to improve the sample efficiency, and the main idea is to incorporate domain knowledge into the training procedures of deep learning models. Specifically, we propose a novel data augmentation technique to generate some synthetic data, which are later processed by an improved training strategy. This KAT methodology follows and realizes the idea of combining analytical and deep learning models together. Modern learning theories demonstrate the effectiveness of our method in terms of effective prediction error feedbacks, a reliable loss function, and rich gradient noises. At last, we study two popular applications in detail: user modeling and probabilistic price forecasting. The proposed method outperforms other competitors in all numerical tests, and the underlying reasons are explained by further statistical and visualization results.
Towards Self-supervised and Weight-preserving Neural Architecture Search
Jun 08, 2022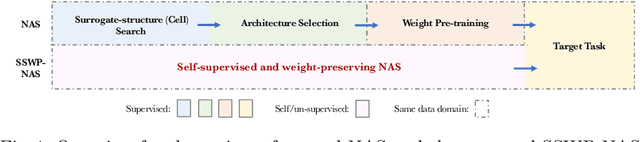
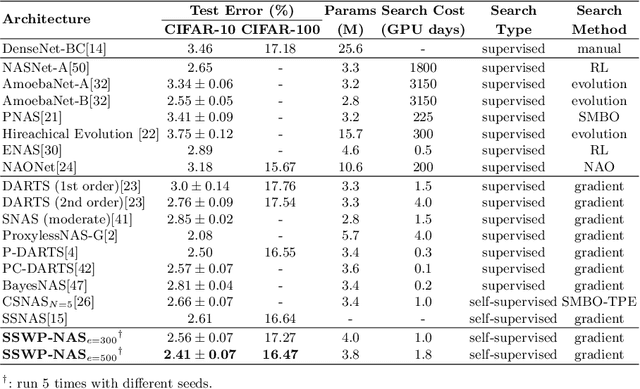
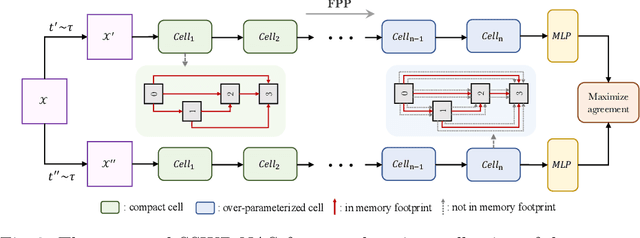
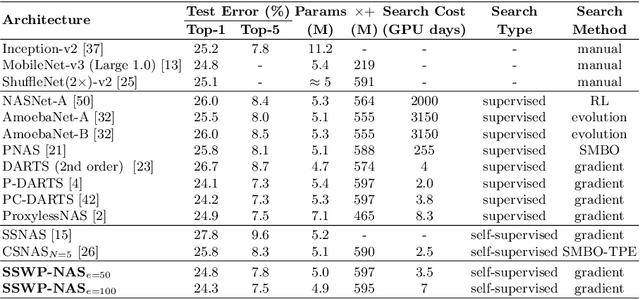
Neural architecture search (NAS) algorithms save tremendous labor from human experts. Recent advancements further reduce the computational overhead to an affordable level. However, it is still cumbersome to deploy the NAS techniques in real-world applications due to the fussy procedures and the supervised learning paradigm. In this work, we propose the self-supervised and weight-preserving neural architecture search (SSWP-NAS) as an extension of the current NAS framework by allowing the self-supervision and retaining the concomitant weights discovered during the search stage. As such, we simplify the workflow of NAS to a one-stage and proxy-free procedure. Experiments show that the architectures searched by the proposed framework achieve state-of-the-art accuracy on CIFAR-10, CIFAR-100, and ImageNet datasets without using manual labels. Moreover, we show that employing the concomitant weights as initialization consistently outperforms the random initialization and the two-stage weight pre-training method by a clear margin under semi-supervised learning scenarios. Codes are publicly available at https://github.com/LzVv123456/SSWP-NAS.
Contrastive and Selective Hidden Embeddings for Medical Image Segmentation
Jan 21, 2022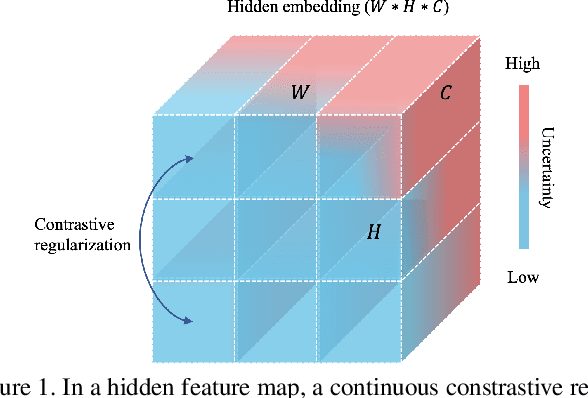
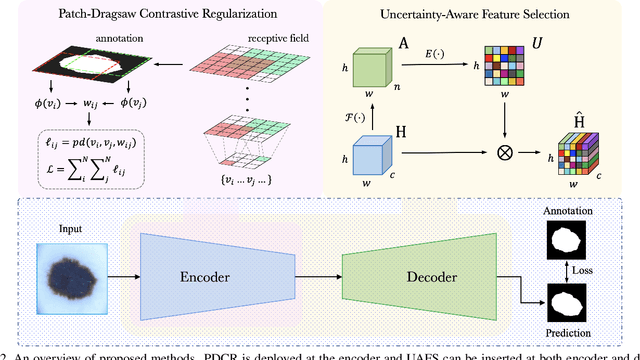
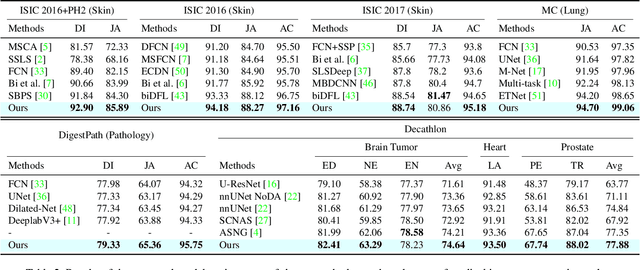
Medical image segmentation has been widely recognized as a pivot procedure for clinical diagnosis, analysis, and treatment planning. However, the laborious and expensive annotation process lags down the speed of further advances. Contrastive learning-based weight pre-training provides an alternative by leveraging unlabeled data to learn a good representation. In this paper, we investigate how contrastive learning benefits the general supervised medical segmentation tasks. To this end, patch-dragsaw contrastive regularization (PDCR) is proposed to perform patch-level tugging and repulsing with the extent controlled by a continuous affinity score. And a new structure dubbed uncertainty-aware feature selection block (UAFS) is designed to perform the feature selection process, which can handle the learning target shift caused by minority features with high uncertainty. By plugging the proposed 2 modules into the existing segmentation architecture, we achieve state-of-the-art results across 8 public datasets from 6 domains. Newly designed modules further decrease the amount of training data to a quarter while achieving comparable, if not better, performances. From this perspective, we take the opposite direction of the original self/un-supervised contrastive learning by further excavating information contained within the label.
Estimating Demand Flexibility Using Siamese LSTM Neural Networks
Sep 03, 2021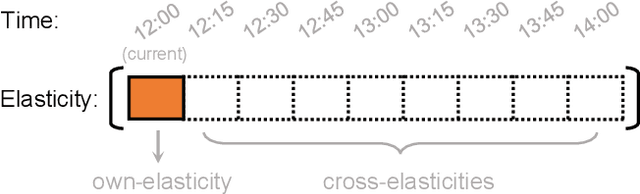
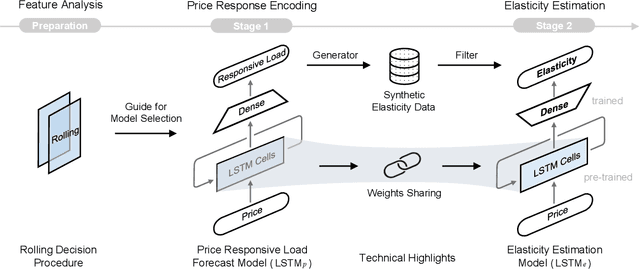
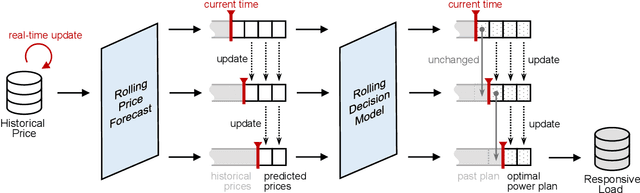
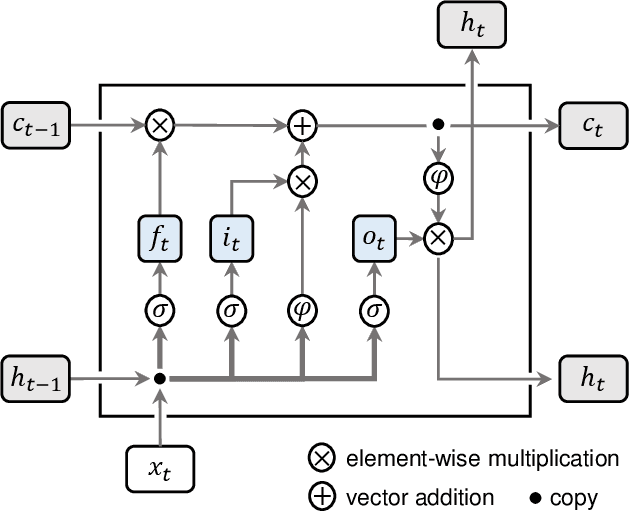
There is an opportunity in modern power systems to explore the demand flexibility by incentivizing consumers with dynamic prices. In this paper, we quantify demand flexibility using an efficient tool called time-varying elasticity, whose value may change depending on the prices and decision dynamics. This tool is particularly useful for evaluating the demand response potential and system reliability. Recent empirical evidences have highlighted some abnormal features when studying demand flexibility, such as delayed responses and vanishing elasticities after price spikes. Existing methods fail to capture these complicated features because they heavily rely on some predefined (often over-simplified) regression expressions. Instead, this paper proposes a model-free methodology to automatically and accurately derive the optimal estimation pattern. We further develop a two-stage estimation process with Siamese long short-term memory (LSTM) networks. Here, a LSTM network encodes the price response, while the other network estimates the time-varying elasticities. In the case study, the proposed framework and models are validated to achieve higher overall estimation accuracy and better description for various abnormal features when compared with the state-of-the-art methods.
Self-Ensembling Contrastive Learning for Semi-Supervised Medical Image Segmentation
Jun 10, 2021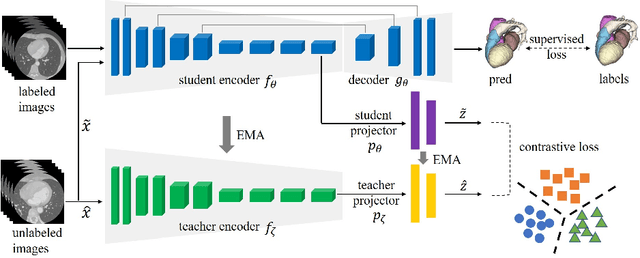
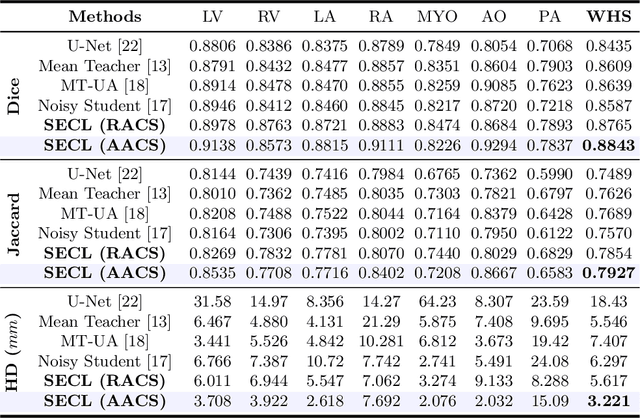
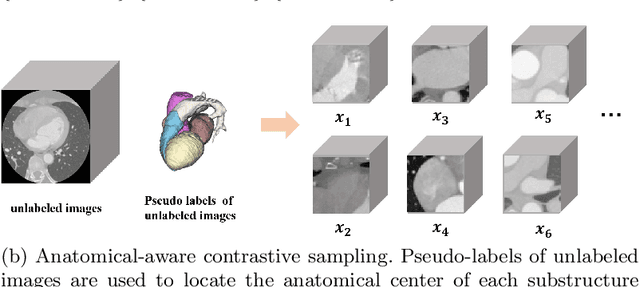
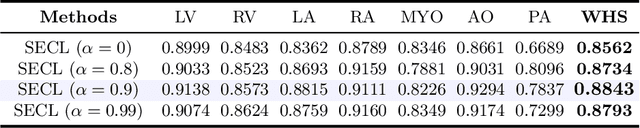
Deep learning has demonstrated significant improvements in medical image segmentation using a sufficiently large amount of training data with manual labels. Acquiring well-representative labels requires expert knowledge and exhaustive labors. In this paper, we aim to boost the performance of semi-supervised learning for medical image segmentation with limited labels using a self-ensembling contrastive learning technique. To this end, we propose to train an encoder-decoder network at image-level with small amounts of labeled images, and more importantly, we learn latent representations directly at feature-level by imposing contrastive loss on unlabeled images. This method strengthens intra-class compactness and inter-class separability, so as to get a better pixel classifier. Moreover, we devise a student encoder for online learning and an exponential moving average version of it, called teacher encoder, to improve the performance iteratively in a self-ensembling manner. To construct contrastive samples with unlabeled images, two sampling strategies that exploit structure similarity across medical images and utilize pseudo-labels for construction, termed region-aware and anatomical-aware contrastive sampling, are investigated. We conduct extensive experiments on an MRI and a CT segmentation dataset and demonstrate that in a limited label setting, the proposed method achieves state-of-the-art performance. Moreover, the anatomical-aware strategy that prepares contrastive samples on-the-fly using pseudo-labels realizes better contrastive regularization on feature representations.
CRT-Net: A Generalized and Scalable Framework for the Computer-Aided Diagnosis of Electrocardiogram Signals
May 28, 2021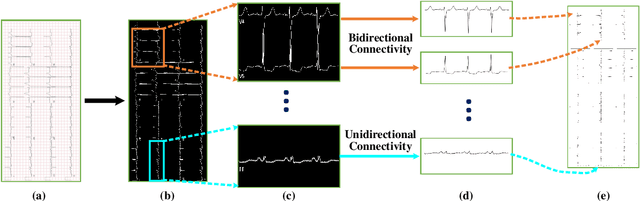
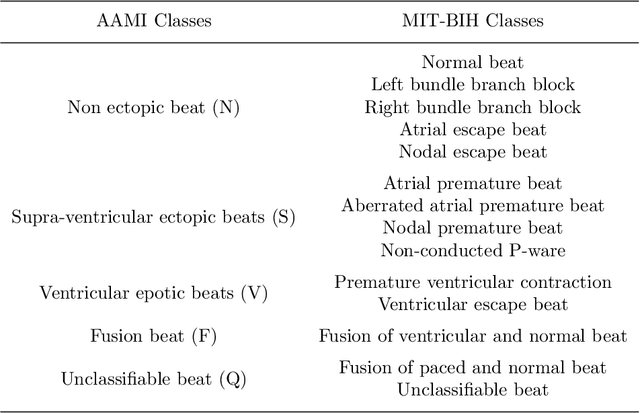
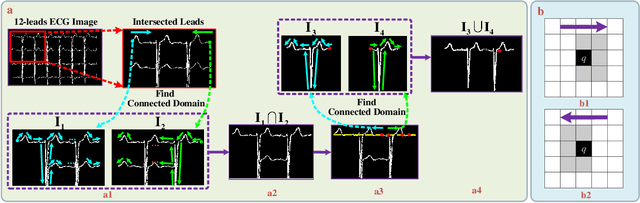
Electrocardiogram (ECG) signals play critical roles in the clinical screening and diagnosis of many types of cardiovascular diseases. Despite deep neural networks that have been greatly facilitated computer-aided diagnosis (CAD) in many clinical tasks, the variability and complexity of ECG in the clinic still pose significant challenges in both diagnostic performance and clinical applications. In this paper, we develop a robust and scalable framework for the clinical recognition of ECG. Considering the fact that hospitals generally record ECG signals in the form of graphic waves of 2-D images, we first extract the graphic waves of 12-lead images into numerical 1-D ECG signals by a proposed bi-directional connectivity method. Subsequently, a novel deep neural network, namely CRT-Net, is designed for the fine-grained and comprehensive representation and recognition of 1-D ECG signals. The CRT-Net can well explore waveform features, morphological characteristics and time domain features of ECG by embedding convolution neural network(CNN), recurrent neural network(RNN), and transformer module in a scalable deep model, which is especially suitable in clinical scenarios with different lengths of ECG signals captured from different devices. The proposed framework is first evaluated on two widely investigated public repositories, demonstrating the superior performance of ECG recognition in comparison with state-of-the-art. Moreover, we validate the effectiveness of our proposed bi-directional connectivity and CRT-Net on clinical ECG images collected from the local hospital, including 258 patients with chronic kidney disease (CKD), 351 patients with Type-2 Diabetes (T2DM), and around 300 patients in the control group. In the experiments, our methods can achieve excellent performance in the recognition of these two types of disease.