 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlowTime: Towards Continuous Generative Watch Time Prediction via Flow-based Personalized Priors
May 31, 2026Watch time has emerged as a pivotal metric for optimizing deep user engagement in short-video recommender systems. However, current methods of watch time prediction (WTP) suffer from inherent paradigm-specific limitations. Direct Regression faces mean-collapse due to unimodal Gaussian assumptions, while Ordinal Regression is hampered by quantization errors from rigid discretization. Similarly, Discrete Generative Regression struggles with high inference latency and heuristic vocabulary design. Beyond these specific flaws, a shared deficiency is the inability to capture the intrinsic multimodality and heterogeneity of User-Item Interaction Patterns. To address these challenges, we first revisit the WTP problem from a causal perspective and identify these user-specific patterns as structural confounders that modulate watch time outcomes, where identical interests manifest as distinct watch time outcomes conditioned on diverse user habits. Then, we formally propose a new (or the fourth) paradigm -- Continuous Generative Regression, and introduce FlowTime, a novel method utilizing a One-step Generative Variational Autoencoder. FlowTime effectively circumvents the latency of iterative denoising while maintaining the expressivity of continuous latent spaces. Furthermore, we design a Flow-based Personalized Prior that leverages NFs to warp a standard Gaussian prior into a complex, history-conditioned manifold, thereby enabling the adaptive modeling of multimodal interaction patterns. Finally, we build TimeRec, the first open-source WTP Library, alongside a novel personalization metric to establish a rigorous benchmarking standard. Extensive offline experiments and online A/B tests demonstrate FlowTime's significant superiority over SOTA methods.
STEP: Scientific Time-Series Encoder Pretraining via Cross-Domain Distillation
Mar 19, 2026Scientific time series are central to scientific AI but are typically sparse, highly heterogeneous, and limited in scale, making unified representation learning particularly challenging. Meanwhile, foundation models pretrained on relevant time series domains such as audio, general time series, and brain signals contain rich knowledge, but their applicability to scientific signals remains underexplored. In this paper, we investigate the transferability and complementarity of foundation models from relevant time series domains, and study how to effectively leverage them to build a unified encoder for scientific time series. We first systematically evaluate relevant foundation models, showing the effectiveness of knowledge transfer to scientific tasks and their complementary strengths. Based on this observation, we propose STEP, a Scientific Time Series Encoder Pretraining framework via cross domain distillation. STEP introduces adaptive patching to handle extreme-length sequences and a statistics compensation scheme to accommodate diverse numerical scales. It further leverages cross-domain distillation to integrate knowledge from multiple foundation models into a unified encoder. By combining complementary representations across different domains, STEP learns general-purpose and transferable features tailored for scientific signals. Experiments on seven scientific time series tasks demonstrate that STEP provides both an effective structure and an effective pretraining paradigm, taking a STEP toward scientific time series representation learning.
PresentCoach: Dual-Agent Presentation Coaching through Exemplars and Interactive Feedback
Nov 19, 2025Effective presentation skills are essential in education, professional communication, and public speaking, yet learners often lack access to high-quality exemplars or personalized coaching. Existing AI tools typically provide isolated functionalities such as speech scoring or script generation without integrating reference modeling and interactive feedback into a cohesive learning experience. We introduce a dual-agent system that supports presentation practice through two complementary roles: the Ideal Presentation Agent and the Coach Agent. The Ideal Presentation Agent converts user-provided slides into model presentation videos by combining slide processing, visual-language analysis, narration script generation, personalized voice synthesis, and synchronized video assembly. The Coach Agent then evaluates user-recorded presentations against these exemplars, conducting multimodal speech analysis and delivering structured feedback in an Observation-Impact-Suggestion (OIS) format. To enhance the authenticity of the learning experience, the Coach Agent incorporates an Audience Agent, which simulates the perspective of a human listener and provides humanized feedback reflecting audience reactions and engagement. Together, these agents form a closed loop of observation, practice, and feedback. Implemented on a robust backend with multi-model integration, voice cloning, and error handling mechanisms, the system demonstrates how AI-driven agents can provide engaging, human-centered, and scalable support for presentation skill development in both educational and professional contexts.
SPEAR: A Unified SSL Framework for Learning Speech and Audio Representations
Oct 29, 2025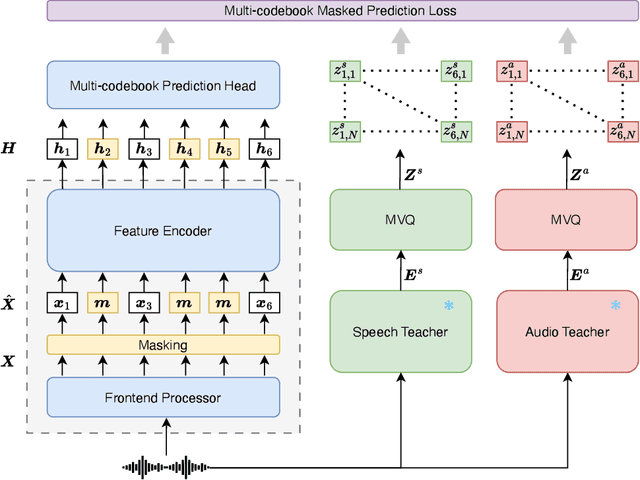

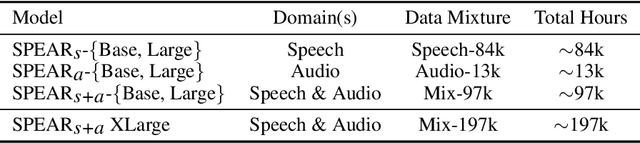
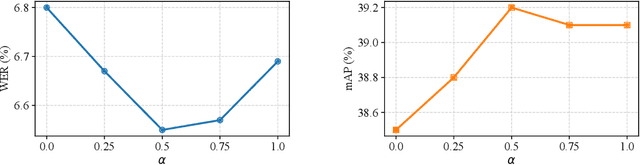
Self-Supervised Learning (SSL) excels at learning generic representations of acoustic signals, yet prevailing methods remain domain-specific, tailored to either speech or general audio, hindering the development of a unified representation model with a comprehensive capability over both domains. To address this, we present SPEAR (SPEech and Audio Representations), the first SSL framework to successfully learn unified speech and audio representations from a mixture of speech and audio data. SPEAR proposes a unified pre-training objective based on masked prediction of fine-grained discrete tokens for both speech and general audio. These tokens are derived from continuous speech and audio representations using a Multi-codebook Vector Quantisation (MVQ) method, retaining rich acoustic detail essential for modelling both speech and complex audio events. SPEAR is applied to pre-train both single-domain and unified speech-and-audio SSL models. Our speech-domain model establishes a new state-of-the-art on the SUPERB benchmark, a speech processing benchmark for SSL models, matching or surpassing the highly competitive WavLM Large on 12 out of 15 tasks with the same pre-training corpora and a similar model size. Crucially, our unified model learns complementary features and demonstrates comprehensive capabilities across two major benchmarks, SUPERB and HEAR, for evaluating audio representations. By further scaling up the model size and pre-training data, we present a unified model with 600M parameters that excels in both domains, establishing it as one of the most powerful and versatile open-source SSL models for auditory understanding. The inference code and pre-trained models will be made publicly available.
MAGI-1: Autoregressive Video Generation at Scale
May 19, 2025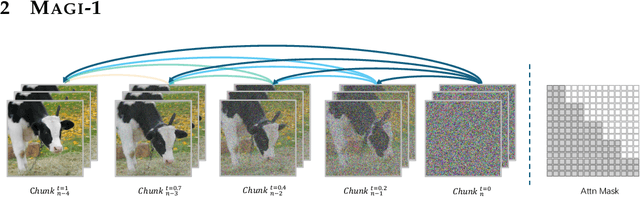
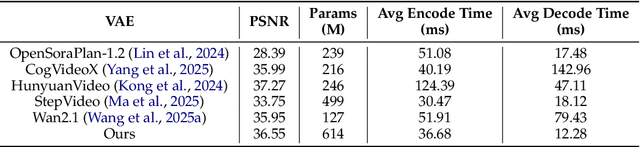
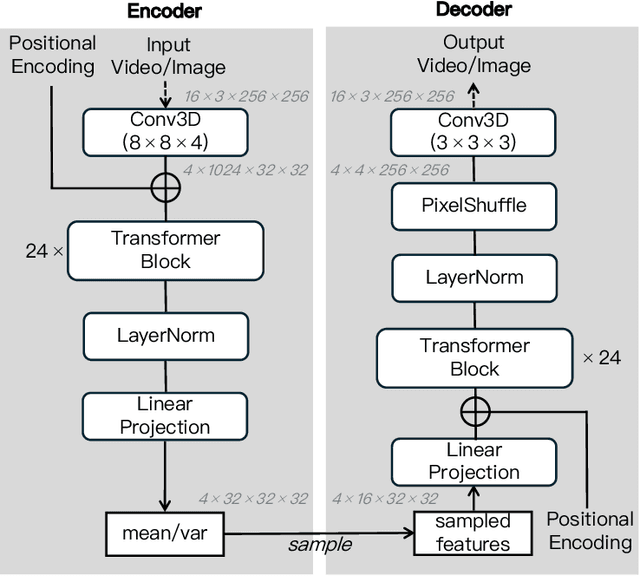
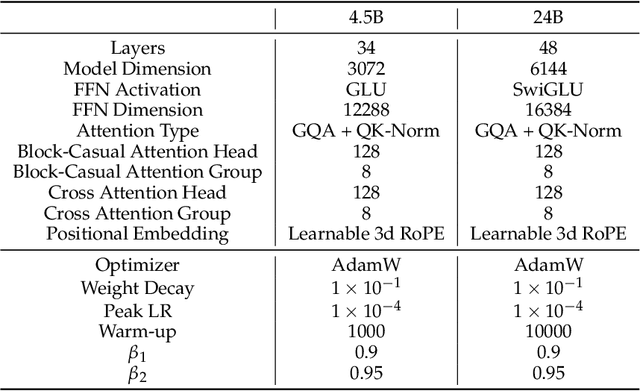
We present MAGI-1, a world model that generates videos by autoregressively predicting a sequence of video chunks, defined as fixed-length segments of consecutive frames. Trained to denoise per-chunk noise that increases monotonically over time, MAGI-1 enables causal temporal modeling and naturally supports streaming generation. It achieves strong performance on image-to-video (I2V) tasks conditioned on text instructions, providing high temporal consistency and scalability, which are made possible by several algorithmic innovations and a dedicated infrastructure stack. MAGI-1 facilitates controllable generation via chunk-wise prompting and supports real-time, memory-efficient deployment by maintaining constant peak inference cost, regardless of video length. The largest variant of MAGI-1 comprises 24 billion parameters and supports context lengths of up to 4 million tokens, demonstrating the scalability and robustness of our approach. The code and models are available at https://github.com/SandAI-org/MAGI-1 and https://github.com/SandAI-org/MagiAttention. The product can be accessed at https://sand.ai.
Walking the Tightrope: Disentangling Beneficial and Detrimental Drifts in Non-Stationary Custom-Tuning
May 19, 2025This paper uncovers a critical yet overlooked phenomenon in multi-modal large language models (MLLMs): detrimental concept drift within chain-of-thought (CoT) reasoning during non-stationary reinforcement fine-tuning (RFT), where reasoning token distributions evolve unpredictably, thereby introducing significant biases in final predictions. To address this, we are pioneers in establishing the theoretical bridge between concept drift theory and RFT processes by formalizing CoT's autoregressive token streams as non-stationary distributions undergoing arbitrary temporal shifts. Leveraging this framework, we propose a novel counterfact-aware RFT that systematically decouples beneficial distribution adaptation from harmful concept drift through concept graph-empowered LLM experts generating counterfactual reasoning trajectories. Our solution, Counterfactual Preference Optimization (CPO), enables stable RFT in non-stationary environments, particularly within the medical domain, through custom-tuning of counterfactual-aware preference alignment. Extensive experiments demonstrate our superior performance of robustness, generalization and coordination within RFT. Besides, we also contributed a large-scale dataset CXR-CounterFact (CCF), comprising 320,416 meticulously curated counterfactual reasoning trajectories derived from MIMIC-CXR. Our code and data are public.
Learning Robust Spectral Dynamics for Temporal Domain Generalization
May 19, 2025
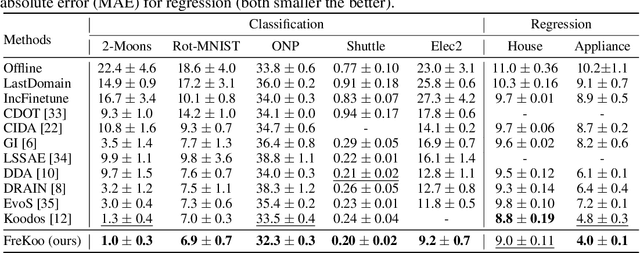
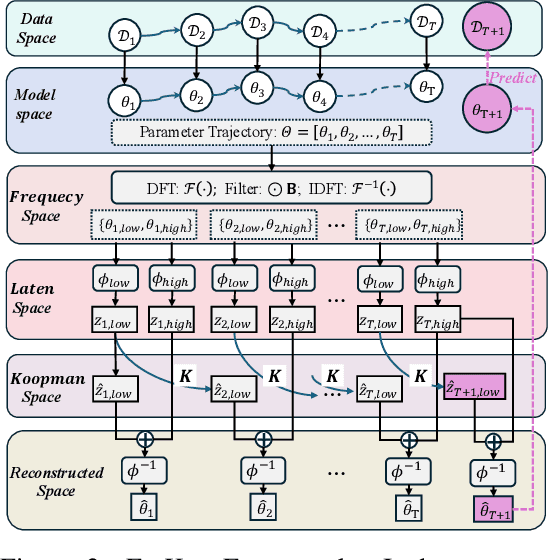

Modern machine learning models struggle to maintain performance in dynamic environments where temporal distribution shifts, \emph{i.e., concept drift}, are prevalent. Temporal Domain Generalization (TDG) seeks to enable model generalization across evolving domains, yet existing approaches typically assume smooth incremental changes, struggling with complex real-world drifts involving long-term structure (incremental evolution/periodicity) and local uncertainties. To overcome these limitations, we introduce FreKoo, which tackles these challenges via a novel frequency-domain analysis of parameter trajectories. It leverages the Fourier transform to disentangle parameter evolution into distinct spectral bands. Specifically, low-frequency component with dominant dynamics are learned and extrapolated using the Koopman operator, robustly capturing diverse drift patterns including both incremental and periodicity. Simultaneously, potentially disruptive high-frequency variations are smoothed via targeted temporal regularization, preventing overfitting to transient noise and domain uncertainties. In addition, this dual spectral strategy is rigorously grounded through theoretical analysis, providing stability guarantees for the Koopman prediction, a principled Bayesian justification for the high-frequency regularization, and culminating in a multiscale generalization bound connecting spectral dynamics to improved generalization. Extensive experiments demonstrate FreKoo's significant superiority over SOTA TDG approaches, particularly excelling in real-world streaming scenarios with complex drifts and uncertainties.
Who You Are Matters: Bridging Topics and Social Roles via LLM-Enhanced Logical Recommendation
May 16, 2025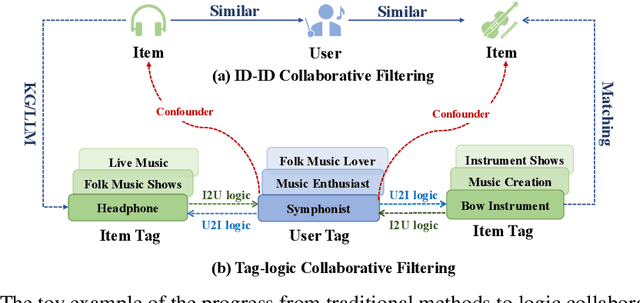
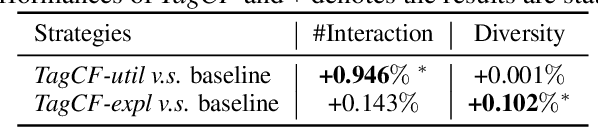
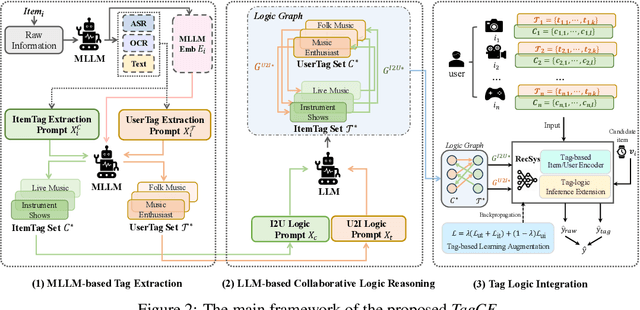
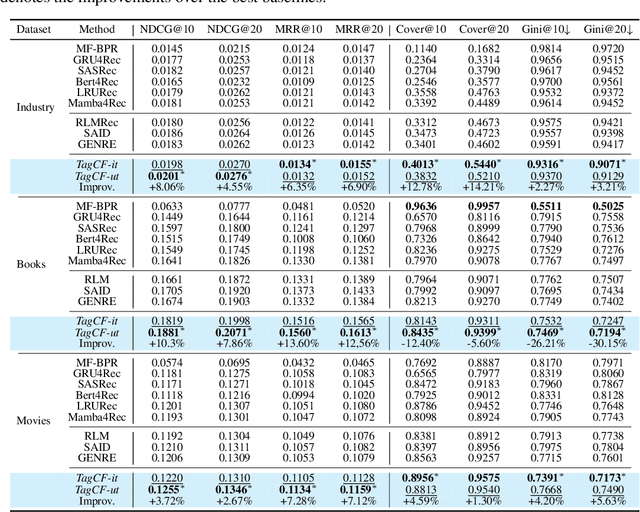
Recommender systems filter contents/items valuable to users by inferring preferences from user features and historical behaviors. Mainstream approaches follow the learning-to-rank paradigm, which focus on discovering and modeling item topics (e.g., categories), and capturing user preferences on these topics based on historical interactions. However, this paradigm often neglects the modeling of user characteristics and their social roles, which are logical confounders influencing the correlated interest and user preference transition. To bridge this gap, we introduce the user role identification task and the behavioral logic modeling task that aim to explicitly model user roles and learn the logical relations between item topics and user social roles. We show that it is possible to explicitly solve these tasks through an efficient integration framework of Large Language Model (LLM) and recommendation systems, for which we propose TagCF. On the one hand, the exploitation of the LLM's world knowledge and logic inference ability produces a virtual logic graph that reveals dynamic and expressive knowledge of users, augmenting the recommendation performance. On the other hand, the user role aligns the user behavioral logic with the observed user feedback, refining our understanding of user behaviors. Additionally, we also show that the extracted user-item logic graph is empirically a general knowledge that can benefit a wide range of recommendation tasks, and conduct experiments on industrial and several public datasets as verification.
Comprehensive List Generation for Multi-Generator Reranking
Apr 22, 2025Reranking models solve the final recommendation lists that best fulfill users' demands. While existing solutions focus on finding parametric models that approximate optimal policies, recent approaches find that it is better to generate multiple lists to compete for a ``pass'' ticket from an evaluator, where the evaluator serves as the supervisor who accurately estimates the performance of the candidate lists. In this work, we show that we can achieve a more efficient and effective list proposal with a multi-generator framework and provide empirical evidence on two public datasets and online A/B tests. More importantly, we verify that the effectiveness of a generator is closely related to how much it complements the views of other generators with sufficiently different rerankings, which derives the metric of list comprehensiveness. With this intuition, we design an automatic complementary generator-finding framework that learns a policy that simultaneously aligns the users' preferences and maximizes the list comprehensiveness metric. The experimental results indicate that the proposed framework can further improve the multi-generator reranking performance.
* 11 pages, 6 figures, 9 tables
Explicit Uncertainty Modeling for Video Watch Time Prediction
Apr 10, 2025In video recommendation, a critical component that determines the system's recommendation accuracy is the watch-time prediction module, since how long a user watches a video directly reflects personalized preferences. One of the key challenges of this problem is the user's stochastic watch-time behavior. To improve the prediction accuracy for such an uncertain behavior, existing approaches show that one can either reduce the noise through duration bias modeling or formulate a distribution modeling task to capture the uncertainty. However, the uncontrolled uncertainty is not always equally distributed across users and videos, inducing a balancing paradox between the model accuracy and the ability to capture out-of-distribution samples. In practice, we find that the uncertainty of the watch-time prediction model also provides key information about user behavior, which, in turn, could benefit the prediction task itself. Following this notion, we derive an explicit uncertainty modeling strategy for the prediction model and propose an adversarial optimization framework that can better exploit the user watch-time behavior. This framework has been deployed online on an industrial video sharing platform that serves hundreds of millions of daily active users, which obtains a significant increase in users' video watch time by 0.31% through the online A/B test. Furthermore, extended offline experiments on two public datasets verify the effectiveness of the proposed framework across various watch-time prediction backbones.