 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Short Videos and Live Streams: Reasoning-Guided Multimodal LLMs for Cross-Domain Representation Learning
Jun 03, 2026As live streaming services grow, many platforms offer short videos and live streams to meet diverse needs. Short videos carry substantial traffic and rich behavior signals, whereas live streaming is a core conversion scenario with sparse behavior data, making cold start severe. Transferring user interests from short videos to live streaming recommendation can alleviate these issues. Meanwhile, short videos and live streams are complex multimodal items, and integrating multimodal signals improves recommendation performance. Although Multimodal Large Language Models (MLLMs) show strong multimodal understanding and reasoning, their application to cross-domain recommendation remains underexplored. To this end, we propose Reasoning-Guided Cross-Domain Representation Learning (RGCD-Rep), a reasoning-guided framework for cross-domain recommendation from short videos to live streams. RGCD-Rep introduces MLLM reasoning resource-efficiently and learns transferable item representations guided by behavioral collaboration via two-stage training. First, reasoning-aware distillation lets a frozen teacher MLLM generate structured cross-domain reasoning knowledge and distills it into a lightweight student MLLM. Second, transferability-guided cross-domain representation learning decomposes item representations into transferable and domain residual representations. The resulting representations are computed offline and integrated into downstream retrieval tasks, enabling low-cost industrial deployment. Extensive offline experiments demonstrate RGCD-Rep's superiority. After deployment in Kuaishou's live streaming recommendation system, A/B tests show significant gains across multiple core business metrics, confirming its effectiveness and practicality in real industrial scenarios. RGCD-Rep is fully deployed and serves over 400 million users daily.
From Local Indices to Global Identifiers: Generative Reranking for Recommender Systems via Global Action Space
Apr 28, 2026In modern recommender systems, list-wise reranking serves as a critical phase within the multi-stage pipeline, finalizing the exposed item sequence and directly impacting user satisfaction by modeling complex intra-list item dependencies. Existing methods typically formulate this task as selecting indices from the local input list. However, this approach suffers from a semantically inconsistent action space: the same output neuron (logits) represents different items across different samples, preventing the model from establishing a stable, intrinsic understanding of the items. To address this, we propose GloRank (Global Action Space Ranker), a generative framework that shifts reranking from selecting local indices to generating global identifiers. Specifically, we represent items as sequences of discrete tokens and reformulate reranking as a token generation task. This design effectively decouples the scoring mechanism from the variable input order, ensuring that items are evaluated against a consistent global standard. We further enhance this with a two-stage optimization pipeline: a supervised pre-training phase to initialize the model with high-quality demonstrations, followed by a reinforcement learning-based post-training phase to directly maximize list-wise utility. Extensive experiments on two public benchmarks and a large-scale industrial dataset, coupled with online A/B tests, demonstrate that GloRank consistently outperforms state-of-the-art baselines and achieves superior robustness in cold-start scenarios.
FlashEvaluator: Expanding Search Space with Parallel Evaluation
Mar 03, 2026The Generator-Evaluator (G-E) framework, i.e., evaluating K sequences from a generator and selecting the top-ranked one according to evaluator scores, is a foundational paradigm in tasks such as Recommender Systems (RecSys) and Natural Language Processing (NLP). Traditional evaluators process sequences independently, suffering from two major limitations: (1) lack of explicit cross-sequence comparison, leading to suboptimal accuracy; (2) poor parallelization with linear complexity of O(K), resulting in inefficient resource utilization and negative impact on both throughput and latency. To address these challenges, we propose FlashEvaluator, which enables cross-sequence token information sharing and processes all sequences in a single forward pass. This yields sublinear computational complexity that improves the system's efficiency and supports direct inter-sequence comparisons that improve selection accuracy. The paper also provides theoretical proofs and extensive experiments on recommendation and NLP tasks, demonstrating clear advantages over conventional methods. Notably, FlashEvaluator has been deployed in online recommender system of Kuaishou, delivering substantial and sustained revenue gains in practice.
SOLAR: SVD-Optimized Lifelong Attention for Recommendation
Mar 03, 2026Attention mechanism remains the defining operator in Transformers since it provides expressive global credit assignment, yet its $O(N^2 d)$ time and memory cost in sequence length $N$ makes long-context modeling expensive and often forces truncation or other heuristics. Linear attention reduces complexity to $O(N d^2)$ by reordering computation through kernel feature maps, but this reformulation drops the softmax mechanism and shifts the attention score distribution. In recommender systems, low-rank structure in matrices is not a rare case, but rather the default inductive bias in its representation learning, particularly explicit in the user behavior sequence modeling. Leveraging this structure, we introduce SVD-Attention, which is theoretically lossless on low-rank matrices and preserves softmax while reducing attention complexity from $O(N^2 d)$ to $O(Ndr)$. With SVD-Attention, we propose SOLAR, SVD-Optimized Lifelong Attention for Recommendation, a sequence modeling framework that supports behavior sequences of ten-thousand scale and candidate sets of several thousand items in cascading process without any filtering. In Kuaishou's online recommendation scenario, SOLAR delivers a 0.68\% Video Views gain together with additional business metrics improvements.
Towards End-to-End Alignment of User Satisfaction via Questionnaire in Video Recommendation
Jan 28, 2026Short-video recommender systems typically optimize ranking models using dense user behavioral signals, such as clicks and watch time. However, these signals are only indirect proxies of user satisfaction and often suffer from noise and bias. Recently, explicit satisfaction feedback collected through questionnaires has emerged as a high-quality direct alignment supervision, but is extremely sparse and easily overwhelmed by abundant behavioral data, making it difficult to incorporate into online recommendation models. To address these challenges, we propose a novel framework which is towards End-to-End Alignment of user Satisfaction via Questionaire, named EASQ, to enable real-time alignment of ranking models with true user satisfaction. Specifically, we first construct an independent parameter pathway for sparse questionnaire signals by combining a multi-task architecture and a lightweight LoRA module. The multi-task design separates sparse satisfaction supervision from dense behavioral signals, preventing the former from being overwhelmed. The LoRA module pre-inject these preferences in a parameter-isolated manner, ensuring stability in the backbone while optimizing user satisfaction. Furthermore, we employ a DPO-based optimization objective tailored for online learning, which aligns the main model outputs with sparse satisfaction signals in real time. This design enables end-to-end online learning, allowing the model to continuously adapt to new questionnaire feedback while maintaining the stability and effectiveness of the backbone. Extensive offline experiments and large-scale online A/B tests demonstrate that EASQ consistently improves user satisfaction metrics across multiple scenarios. EASQ has been successfully deployed in a production short-video recommendation system, delivering significant and stable business gains.
GoalRank: Group-Relative Optimization for a Large Ranking Model
Sep 26, 2025Mainstream ranking approaches typically follow a Generator-Evaluator two-stage paradigm, where a generator produces candidate lists and an evaluator selects the best one. Recent work has attempted to enhance performance by expanding the number of candidate lists, for example, through multi-generator settings. However, ranking involves selecting a recommendation list from a combinatorially large space. Simply enlarging the candidate set remains ineffective, and performance gains quickly saturate. At the same time, recent advances in large recommendation models have shown that end-to-end one-stage models can achieve promising performance with the expectation of scaling laws. Motivated by this, we revisit ranking from a generator-only one-stage perspective. We theoretically prove that, for any (finite Multi-)Generator-Evaluator model, there always exists a generator-only model that achieves strictly smaller approximation error to the optimal ranking policy, while also enjoying scaling laws as its size increases. Building on this result, we derive an evidence upper bound of the one-stage optimization objective, from which we find that one can leverage a reward model trained on real user feedback to construct a reference policy in a group-relative manner. This reference policy serves as a practical surrogate of the optimal policy, enabling effective training of a large generator-only ranker. Based on these insights, we propose GoalRank, a generator-only ranking framework. Extensive offline experiments on public benchmarks and large-scale online A/B tests demonstrate that GoalRank consistently outperforms state-of-the-art methods.
OneRec-V2 Technical Report
Aug 28, 2025



Recent breakthroughs in generative AI have transformed recommender systems through end-to-end generation. OneRec reformulates recommendation as an autoregressive generation task, achieving high Model FLOPs Utilization. While OneRec-V1 has shown significant empirical success in real-world deployment, two critical challenges hinder its scalability and performance: (1) inefficient computational allocation where 97.66% of resources are consumed by sequence encoding rather than generation, and (2) limitations in reinforcement learning relying solely on reward models. To address these challenges, we propose OneRec-V2, featuring: (1) Lazy Decoder-Only Architecture: Eliminates encoder bottlenecks, reducing total computation by 94% and training resources by 90%, enabling successful scaling to 8B parameters. (2) Preference Alignment with Real-World User Interactions: Incorporates Duration-Aware Reward Shaping and Adaptive Ratio Clipping to better align with user preferences using real-world feedback. Extensive A/B tests on Kuaishou demonstrate OneRec-V2's effectiveness, improving App Stay Time by 0.467%/0.741% while balancing multi-objective recommendations. This work advances generative recommendation scalability and alignment with real-world feedback, representing a step forward in the development of end-to-end recommender systems.
An End-to-End Multi-objective Ensemble Ranking Framework for Video Recommendation
Aug 07, 2025We propose a novel End-to-end Multi-objective Ensemble Ranking framework (EMER) for the multi-objective ensemble ranking module, which is the most critical component of the short video recommendation system. EMER enhances personalization by replacing manually-designed heuristic formulas with an end-to-end modeling paradigm. EMER introduces a meticulously designed loss function to address the fundamental challenge of defining effective supervision for ensemble ranking, where no single ground-truth signal can fully capture user satisfaction. Moreover, EMER introduces novel sample organization method and transformer-based network architecture to capture the comparative relationships among candidates, which are critical for effective ranking. Additionally, we have proposed an offline-online consistent evaluation system to enhance the efficiency of offline model optimization, which is an established yet persistent challenge within the multi-objective ranking domain in industry. Abundant empirical tests are conducted on a real industrial dataset, and the results well demonstrate the effectiveness of our proposed framework. In addition, our framework has been deployed in the primary scenarios of Kuaishou, a short video recommendation platform with hundreds of millions of daily active users, achieving a 1.39% increase in overall App Stay Time and a 0.196% increase in 7-day user Lifetime(LT7), which are substantial improvements.
OneRec Technical Report
Jun 16, 2025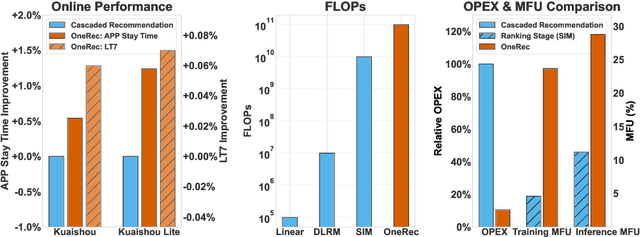

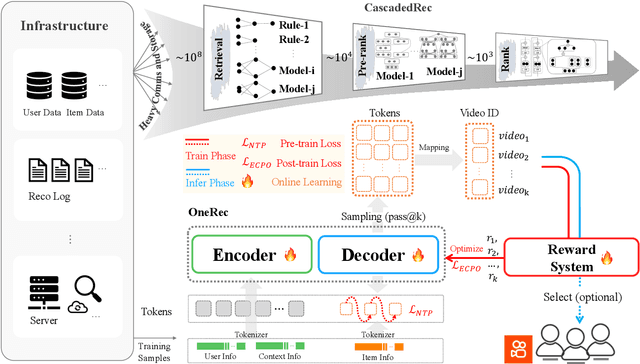

Recommender systems have been widely used in various large-scale user-oriented platforms for many years. However, compared to the rapid developments in the AI community, recommendation systems have not achieved a breakthrough in recent years. For instance, they still rely on a multi-stage cascaded architecture rather than an end-to-end approach, leading to computational fragmentation and optimization inconsistencies, and hindering the effective application of key breakthrough technologies from the AI community in recommendation scenarios. To address these issues, we propose OneRec, which reshapes the recommendation system through an end-to-end generative approach and achieves promising results. Firstly, we have enhanced the computational FLOPs of the current recommendation model by 10 $\times$ and have identified the scaling laws for recommendations within certain boundaries. Secondly, reinforcement learning techniques, previously difficult to apply for optimizing recommendations, show significant potential in this framework. Lastly, through infrastructure optimizations, we have achieved 23.7% and 28.8% Model FLOPs Utilization (MFU) on flagship GPUs during training and inference, respectively, aligning closely with the LLM community. This architecture significantly reduces communication and storage overhead, resulting in operating expense that is only 10.6% of traditional recommendation pipelines. Deployed in Kuaishou/Kuaishou Lite APP, it handles 25% of total queries per second, enhancing overall App Stay Time by 0.54% and 1.24%, respectively. Additionally, we have observed significant increases in metrics such as 7-day Lifetime, which is a crucial indicator of recommendation experience. We also provide practical lessons and insights derived from developing, optimizing, and maintaining a production-scale recommendation system with significant real-world impact.
Who You Are Matters: Bridging Topics and Social Roles via LLM-Enhanced Logical Recommendation
May 16, 2025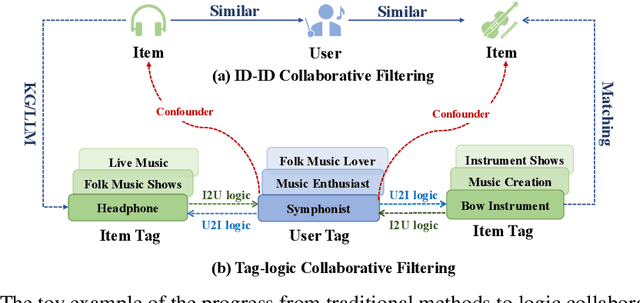
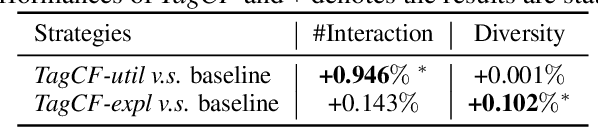
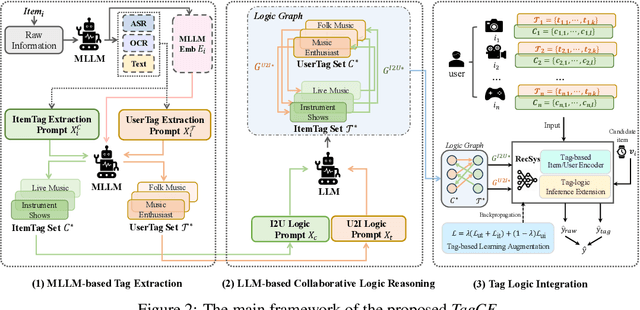
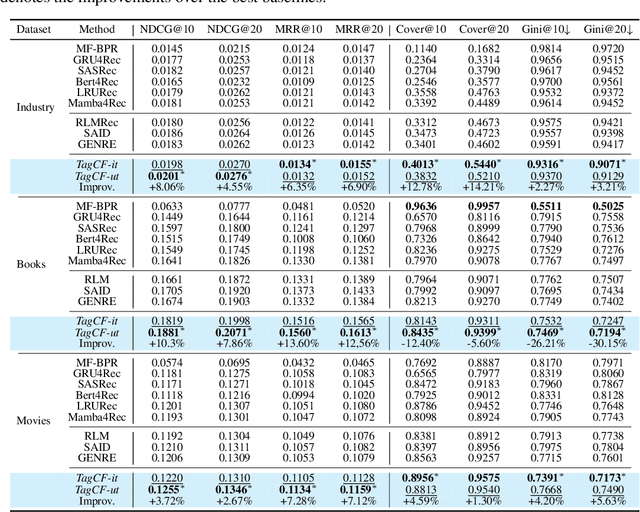
Recommender systems filter contents/items valuable to users by inferring preferences from user features and historical behaviors. Mainstream approaches follow the learning-to-rank paradigm, which focus on discovering and modeling item topics (e.g., categories), and capturing user preferences on these topics based on historical interactions. However, this paradigm often neglects the modeling of user characteristics and their social roles, which are logical confounders influencing the correlated interest and user preference transition. To bridge this gap, we introduce the user role identification task and the behavioral logic modeling task that aim to explicitly model user roles and learn the logical relations between item topics and user social roles. We show that it is possible to explicitly solve these tasks through an efficient integration framework of Large Language Model (LLM) and recommendation systems, for which we propose TagCF. On the one hand, the exploitation of the LLM's world knowledge and logic inference ability produces a virtual logic graph that reveals dynamic and expressive knowledge of users, augmenting the recommendation performance. On the other hand, the user role aligns the user behavioral logic with the observed user feedback, refining our understanding of user behaviors. Additionally, we also show that the extracted user-item logic graph is empirically a general knowledge that can benefit a wide range of recommendation tasks, and conduct experiments on industrial and several public datasets as verification.