 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDR-Venus: Towards Frontier Edge-Scale Deep Research Agents with Only 10K Open Data
Apr 21, 2026Edge-scale deep research agents based on small language models are attractive for real-world deployment due to their advantages in cost, latency, and privacy. In this work, we study how to train a strong small deep research agent under limited open-data by improving both data quality and data utilization. We present DR-Venus, a frontier 4B deep research agent for edge-scale deployment, built entirely on open data. Our training recipe consists of two stages. In the first stage, we use agentic supervised fine-tuning (SFT) to establish basic agentic capability, combining strict data cleaning with resampling of long-horizon trajectories to improve data quality and utilization. In the second stage, we apply agentic reinforcement learning (RL) to further improve execution reliability on long-horizon deep research tasks. To make RL effective for small agents in this setting, we build on IGPO and design turn-level rewards based on information gain and format-aware regularization, thereby enhancing supervision density and turn-level credit assignment. Built entirely on roughly 10K open-data, DR-Venus-4B significantly outperforms prior agentic models under 9B parameters on multiple deep research benchmarks, while also narrowing the gap to much larger 30B-class systems. Our further analysis shows that 4B agents already possess surprisingly strong performance potential, highlighting both the deployment promise of small models and the value of test-time scaling in this setting. We release our models, code, and key recipes to support reproducible research on edge-scale deep research agents.
UI-Venus-1.5 Technical Report
Feb 09, 2026GUI agents have emerged as a powerful paradigm for automating interactions in digital environments, yet achieving both broad generality and consistently strong task performance remains challenging.In this report, we present UI-Venus-1.5, a unified, end-to-end GUI Agent designed for robust real-world applications.The proposed model family comprises two dense variants (2B and 8B) and one mixture-of-experts variant (30B-A3B) to meet various downstream application scenarios.Compared to our previous version, UI-Venus-1.5 introduces three key technical advances: (1) a comprehensive Mid-Training stage leveraging 10 billion tokens across 30+ datasets to establish foundational GUI semantics; (2) Online Reinforcement Learning with full-trajectory rollouts, aligning training objectives with long-horizon, dynamic navigation in large-scale environments; and (3) a single unified GUI Agent constructed via Model Merging, which synthesizes domain-specific models (grounding, web, and mobile) into one cohesive checkpoint. Extensive evaluations demonstrate that UI-Venus-1.5 establishes new state-of-the-art performance on benchmarks such as ScreenSpot-Pro (69.6%), VenusBench-GD (75.0%), and AndroidWorld (77.6%), significantly outperforming previous strong baselines. In addition, UI-Venus-1.5 demonstrates robust navigation capabilities across a variety of Chinese mobile apps, effectively executing user instructions in real-world scenarios. Code: https://github.com/inclusionAI/UI-Venus; Model: https://huggingface.co/collections/inclusionAI/ui-venus
MatchTIR: Fine-Grained Supervision for Tool-Integrated Reasoning via Bipartite Matching
Jan 15, 2026Tool-Integrated Reasoning (TIR) empowers large language models (LLMs) to tackle complex tasks by interleaving reasoning steps with external tool interactions. However, existing reinforcement learning methods typically rely on outcome- or trajectory-level rewards, assigning uniform advantages to all steps within a trajectory. This coarse-grained credit assignment fails to distinguish effective tool calls from redundant or erroneous ones, particularly in long-horizon multi-turn scenarios. To address this, we propose MatchTIR, a framework that introduces fine-grained supervision via bipartite matching-based turn-level reward assignment and dual-level advantage estimation. Specifically, we formulate credit assignment as a bipartite matching problem between predicted and ground-truth traces, utilizing two assignment strategies to derive dense turn-level rewards. Furthermore, to balance local step precision with global task success, we introduce a dual-level advantage estimation scheme that integrates turn-level and trajectory-level signals, assigning distinct advantage values to individual interaction turns. Extensive experiments on three benchmarks demonstrate the superiority of MatchTIR. Notably, our 4B model surpasses the majority of 8B competitors, particularly in long-horizon and multi-turn tasks. Our codes are available at https://github.com/quchangle1/MatchTIR.
Information Gain-based Policy Optimization: A Simple and Effective Approach for Multi-Turn LLM Agents
Oct 16, 2025Large language model (LLM)-based agents are increasingly trained with reinforcement learning (RL) to enhance their ability to interact with external environments through tool use, particularly in search-based settings that require multi-turn reasoning and knowledge acquisition. However, existing approaches typically rely on outcome-based rewards that are only provided at the final answer. This reward sparsity becomes particularly problematic in multi-turn settings, where long trajectories exacerbate two critical issues: (i) advantage collapse, where all rollouts receive identical rewards and provide no useful learning signals, and (ii) lack of fine-grained credit assignment, where dependencies between turns are obscured, especially in long-horizon tasks. In this paper, we propose Information Gain-based Policy Optimization (IGPO), a simple yet effective RL framework that provides dense and intrinsic supervision for multi-turn agent training. IGPO models each interaction turn as an incremental process of acquiring information about the ground truth, and defines turn-level rewards as the marginal increase in the policy's probability of producing the correct answer. Unlike prior process-level reward approaches that depend on external reward models or costly Monte Carlo estimation, IGPO derives intrinsic rewards directly from the model's own belief updates. These intrinsic turn-level rewards are combined with outcome-level supervision to form dense reward trajectories. Extensive experiments on both in-domain and out-of-domain benchmarks demonstrate that IGPO consistently outperforms strong baselines in multi-turn scenarios, achieving higher accuracy and improved sample efficiency.
KuaiLive: A Real-time Interactive Dataset for Live Streaming Recommendation
Aug 07, 2025
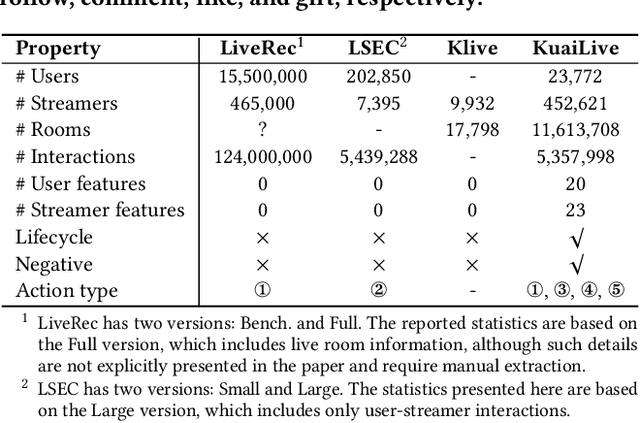

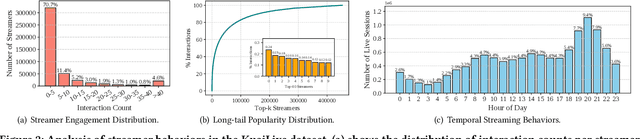
Live streaming platforms have become a dominant form of online content consumption, offering dynamically evolving content, real-time interactions, and highly engaging user experiences. These unique characteristics introduce new challenges that differentiate live streaming recommendation from traditional recommendation settings and have garnered increasing attention from industry in recent years. However, research progress in academia has been hindered by the lack of publicly available datasets that accurately reflect the dynamic nature of live streaming environments. To address this gap, we introduce KuaiLive, the first real-time, interactive dataset collected from Kuaishou, a leading live streaming platform in China with over 400 million daily active users. The dataset records the interaction logs of 23,772 users and 452,621 streamers over a 21-day period. Compared to existing datasets, KuaiLive offers several advantages: it includes precise live room start and end timestamps, multiple types of real-time user interactions (click, comment, like, gift), and rich side information features for both users and streamers. These features enable more realistic simulation of dynamic candidate items and better modeling of user and streamer behaviors. We conduct a thorough analysis of KuaiLive from multiple perspectives and evaluate several representative recommendation methods on it, establishing a strong benchmark for future research. KuaiLive can support a wide range of tasks in the live streaming domain, such as top-K recommendation, click-through rate prediction, watch time prediction, and gift price prediction. Moreover, its fine-grained behavioral data also enables research on multi-behavior modeling, multi-task learning, and fairness-aware recommendation. The dataset and related resources are publicly available at https://imgkkk574.github.io/KuaiLive.
RecGPT Technical Report
Jul 30, 2025



Recommender systems are among the most impactful applications of artificial intelligence, serving as critical infrastructure connecting users, merchants, and platforms. However, most current industrial systems remain heavily reliant on historical co-occurrence patterns and log-fitting objectives, i.e., optimizing for past user interactions without explicitly modeling user intent. This log-fitting approach often leads to overfitting to narrow historical preferences, failing to capture users' evolving and latent interests. As a result, it reinforces filter bubbles and long-tail phenomena, ultimately harming user experience and threatening the sustainability of the whole recommendation ecosystem. To address these challenges, we rethink the overall design paradigm of recommender systems and propose RecGPT, a next-generation framework that places user intent at the center of the recommendation pipeline. By integrating large language models (LLMs) into key stages of user interest mining, item retrieval, and explanation generation, RecGPT transforms log-fitting recommendation into an intent-centric process. To effectively align general-purpose LLMs to the above domain-specific recommendation tasks at scale, RecGPT incorporates a multi-stage training paradigm, which integrates reasoning-enhanced pre-alignment and self-training evolution, guided by a Human-LLM cooperative judge system. Currently, RecGPT has been fully deployed on the Taobao App. Online experiments demonstrate that RecGPT achieves consistent performance gains across stakeholders: users benefit from increased content diversity and satisfaction, merchants and the platform gain greater exposure and conversions. These comprehensive improvement results across all stakeholders validates that LLM-driven, intent-centric design can foster a more sustainable and mutually beneficial recommendation ecosystem.
Revisiting Clustering of Neural Bandits: Selective Reinitialization for Mitigating Loss of Plasticity
Jun 14, 2025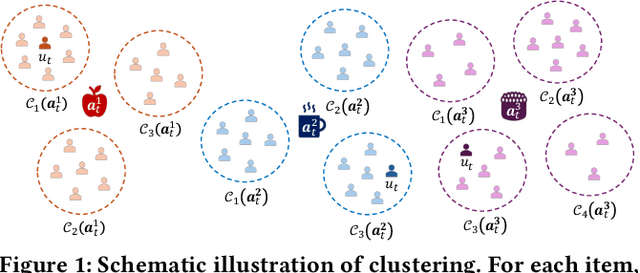
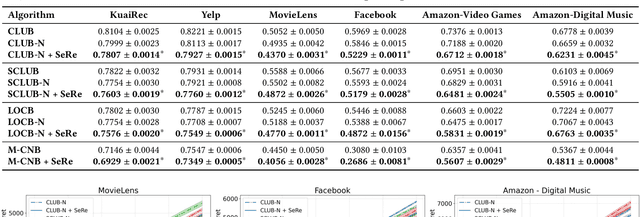
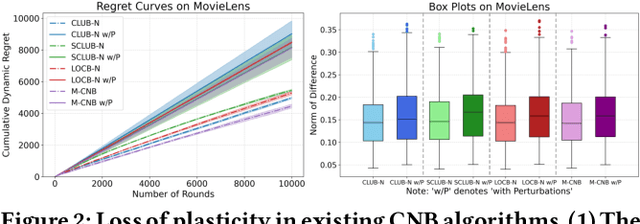

Clustering of Bandits (CB) methods enhance sequential decision-making by grouping bandits into clusters based on similarity and incorporating cluster-level contextual information, demonstrating effectiveness and adaptability in applications like personalized streaming recommendations. However, when extending CB algorithms to their neural version (commonly referred to as Clustering of Neural Bandits, or CNB), they suffer from loss of plasticity, where neural network parameters become rigid and less adaptable over time, limiting their ability to adapt to non-stationary environments (e.g., dynamic user preferences in recommendation). To address this challenge, we propose Selective Reinitialization (SeRe), a novel bandit learning framework that dynamically preserves the adaptability of CNB algorithms in evolving environments. SeRe leverages a contribution utility metric to identify and selectively reset underutilized units, mitigating loss of plasticity while maintaining stable knowledge retention. Furthermore, when combining SeRe with CNB algorithms, the adaptive change detection mechanism adjusts the reinitialization frequency according to the degree of non-stationarity, ensuring effective adaptation without unnecessary resets. Theoretically, we prove that SeRe enables sublinear cumulative regret in piecewise-stationary environments, outperforming traditional CNB approaches in long-term performances. Extensive experiments on six real-world recommendation datasets demonstrate that SeRe-enhanced CNB algorithms can effectively mitigate the loss of plasticity with lower regrets, improving adaptability and robustness in dynamic settings.
GUI-G1: Understanding R1-Zero-Like Training for Visual Grounding in GUI Agents
May 21, 2025Recent Graphical User Interface (GUI) agents replicate the R1-Zero paradigm, coupling online Reinforcement Learning (RL) with explicit chain-of-thought reasoning prior to object grounding and thereby achieving substantial performance gains. In this paper, we first conduct extensive analysis experiments of three key components of that training pipeline: input design, output evaluation, and policy update-each revealing distinct challenges arising from blindly applying general-purpose RL without adapting to GUI grounding tasks. Input design: Current templates encourage the model to generate chain-of-thought reasoning, but longer chains unexpectedly lead to worse grounding performance. Output evaluation: Reward functions based on hit signals or box area allow models to exploit box size, leading to reward hacking and poor localization quality. Policy update: Online RL tends to overfit easy examples due to biases in length and sample difficulty, leading to under-optimization on harder cases. To address these issues, we propose three targeted solutions. First, we adopt a Fast Thinking Template that encourages direct answer generation, reducing excessive reasoning during training. Second, we incorporate a box size constraint into the reward function to mitigate reward hacking. Third, we revise the RL objective by adjusting length normalization and adding a difficulty-aware scaling factor, enabling better optimization on hard samples. Our GUI-G1-3B, trained on 17K public samples with Qwen2.5-VL-3B-Instruct, achieves 90.3% accuracy on ScreenSpot and 37.1% on ScreenSpot-Pro. This surpasses all prior models of similar size and even outperforms the larger UI-TARS-7B, establishing a new state-of-the-art in GUI agent grounding. The project repository is available at https://github.com/Yuqi-Zhou/GUI-G1.
NExT-Search: Rebuilding User Feedback Ecosystem for Generative AI Search
May 20, 2025Generative AI search is reshaping information retrieval by offering end-to-end answers to complex queries, reducing users' reliance on manually browsing and summarizing multiple web pages. However, while this paradigm enhances convenience, it disrupts the feedback-driven improvement loop that has historically powered the evolution of traditional Web search. Web search can continuously improve their ranking models by collecting large-scale, fine-grained user feedback (e.g., clicks, dwell time) at the document level. In contrast, generative AI search operates through a much longer search pipeline, spanning query decomposition, document retrieval, and answer generation, yet typically receives only coarse-grained feedback on the final answer. This introduces a feedback loop disconnect, where user feedback for the final output cannot be effectively mapped back to specific system components, making it difficult to improve each intermediate stage and sustain the feedback loop. In this paper, we envision NExT-Search, a next-generation paradigm designed to reintroduce fine-grained, process-level feedback into generative AI search. NExT-Search integrates two complementary modes: User Debug Mode, which allows engaged users to intervene at key stages; and Shadow User Mode, where a personalized user agent simulates user preferences and provides AI-assisted feedback for less interactive users. Furthermore, we envision how these feedback signals can be leveraged through online adaptation, which refines current search outputs in real-time, and offline update, which aggregates interaction logs to periodically fine-tune query decomposition, retrieval, and generation models. By restoring human control over key stages of the generative AI search pipeline, we believe NExT-Search offers a promising direction for building feedback-rich AI search systems that can evolve continuously alongside human feedback.
Think Before Recommend: Unleashing the Latent Reasoning Power for Sequential Recommendation
Mar 28, 2025Sequential Recommendation (SeqRec) aims to predict the next item by capturing sequential patterns from users' historical interactions, playing a crucial role in many real-world recommender systems. However, existing approaches predominantly adopt a direct forward computation paradigm, where the final hidden state of the sequence encoder serves as the user representation. We argue that this inference paradigm, due to its limited computational depth, struggles to model the complex evolving nature of user preferences and lacks a nuanced understanding of long-tail items, leading to suboptimal performance. To address this issue, we propose \textbf{ReaRec}, the first inference-time computing framework for recommender systems, which enhances user representations through implicit multi-step reasoning. Specifically, ReaRec autoregressively feeds the sequence's last hidden state into the sequential recommender while incorporating special reasoning position embeddings to decouple the original item encoding space from the multi-step reasoning space. Moreover, we introduce two lightweight reasoning-based learning methods, Ensemble Reasoning Learning (ERL) and Progressive Reasoning Learning (PRL), to further effectively exploit ReaRec's reasoning potential. Extensive experiments on five public real-world datasets and different SeqRec architectures demonstrate the generality and effectiveness of our proposed ReaRec. Remarkably, post-hoc analyses reveal that ReaRec significantly elevates the performance ceiling of multiple sequential recommendation backbones by approximately 30\%-50\%. Thus, we believe this work can open a new and promising avenue for future research in inference-time computing for sequential recommendation.