 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDR-Venus: Towards Frontier Edge-Scale Deep Research Agents with Only 10K Open Data
Apr 21, 2026Edge-scale deep research agents based on small language models are attractive for real-world deployment due to their advantages in cost, latency, and privacy. In this work, we study how to train a strong small deep research agent under limited open-data by improving both data quality and data utilization. We present DR-Venus, a frontier 4B deep research agent for edge-scale deployment, built entirely on open data. Our training recipe consists of two stages. In the first stage, we use agentic supervised fine-tuning (SFT) to establish basic agentic capability, combining strict data cleaning with resampling of long-horizon trajectories to improve data quality and utilization. In the second stage, we apply agentic reinforcement learning (RL) to further improve execution reliability on long-horizon deep research tasks. To make RL effective for small agents in this setting, we build on IGPO and design turn-level rewards based on information gain and format-aware regularization, thereby enhancing supervision density and turn-level credit assignment. Built entirely on roughly 10K open-data, DR-Venus-4B significantly outperforms prior agentic models under 9B parameters on multiple deep research benchmarks, while also narrowing the gap to much larger 30B-class systems. Our further analysis shows that 4B agents already possess surprisingly strong performance potential, highlighting both the deployment promise of small models and the value of test-time scaling in this setting. We release our models, code, and key recipes to support reproducible research on edge-scale deep research agents.
UI-Venus-1.5 Technical Report
Feb 09, 2026GUI agents have emerged as a powerful paradigm for automating interactions in digital environments, yet achieving both broad generality and consistently strong task performance remains challenging.In this report, we present UI-Venus-1.5, a unified, end-to-end GUI Agent designed for robust real-world applications.The proposed model family comprises two dense variants (2B and 8B) and one mixture-of-experts variant (30B-A3B) to meet various downstream application scenarios.Compared to our previous version, UI-Venus-1.5 introduces three key technical advances: (1) a comprehensive Mid-Training stage leveraging 10 billion tokens across 30+ datasets to establish foundational GUI semantics; (2) Online Reinforcement Learning with full-trajectory rollouts, aligning training objectives with long-horizon, dynamic navigation in large-scale environments; and (3) a single unified GUI Agent constructed via Model Merging, which synthesizes domain-specific models (grounding, web, and mobile) into one cohesive checkpoint. Extensive evaluations demonstrate that UI-Venus-1.5 establishes new state-of-the-art performance on benchmarks such as ScreenSpot-Pro (69.6%), VenusBench-GD (75.0%), and AndroidWorld (77.6%), significantly outperforming previous strong baselines. In addition, UI-Venus-1.5 demonstrates robust navigation capabilities across a variety of Chinese mobile apps, effectively executing user instructions in real-world scenarios. Code: https://github.com/inclusionAI/UI-Venus; Model: https://huggingface.co/collections/inclusionAI/ui-venus
Joint Deblurring and 3D Reconstruction for Macrophotography
Oct 02, 2025
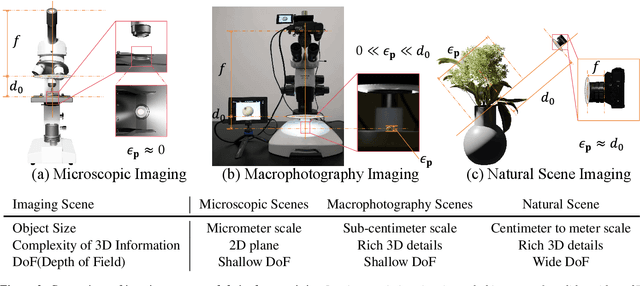
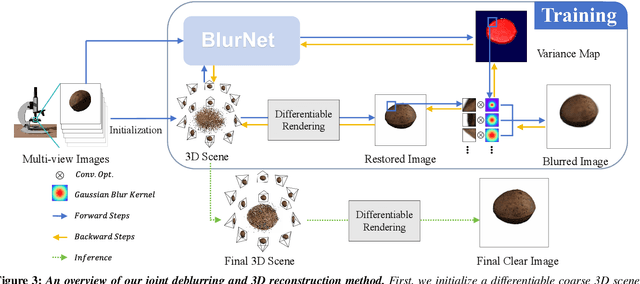

Macro lens has the advantages of high resolution and large magnification, and 3D modeling of small and detailed objects can provide richer information. However, defocus blur in macrophotography is a long-standing problem that heavily hinders the clear imaging of the captured objects and high-quality 3D reconstruction of them. Traditional image deblurring methods require a large number of images and annotations, and there is currently no multi-view 3D reconstruction method for macrophotography. In this work, we propose a joint deblurring and 3D reconstruction method for macrophotography. Starting from multi-view blurry images captured, we jointly optimize the clear 3D model of the object and the defocus blur kernel of each pixel. The entire framework adopts a differentiable rendering method to self-supervise the optimization of the 3D model and the defocus blur kernel. Extensive experiments show that from a small number of multi-view images, our proposed method can not only achieve high-quality image deblurring but also recover high-fidelity 3D appearance.
NestGNN: A Graph Neural Network Framework Generalizing the Nested Logit Model for Travel Mode Choice
Sep 08, 2025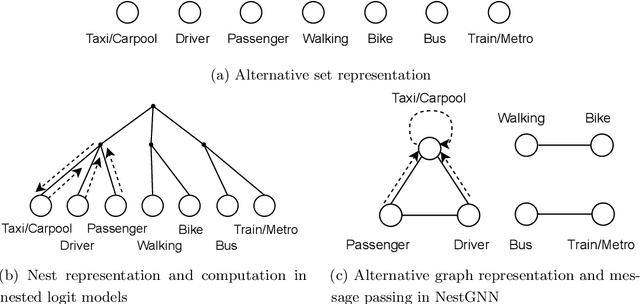
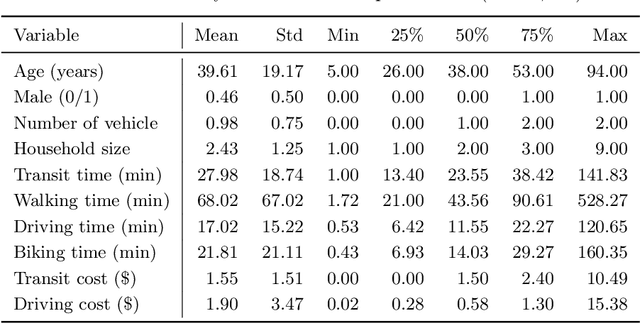
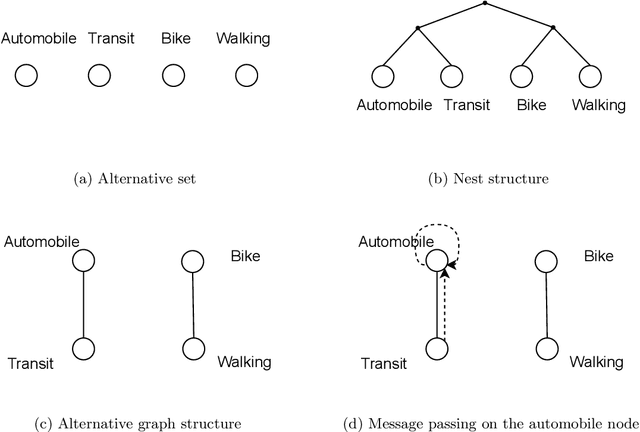

Nested logit (NL) has been commonly used for discrete choice analysis, including a wide range of applications such as travel mode choice, automobile ownership, or location decisions. However, the classical NL models are restricted by their limited representation capability and handcrafted utility specification. While researchers introduced deep neural networks (DNNs) to tackle such challenges, the existing DNNs cannot explicitly capture inter-alternative correlations in the discrete choice context. To address the challenges, this study proposes a novel concept - alternative graph - to represent the relationships among travel mode alternatives. Using a nested alternative graph, this study further designs a nested-utility graph neural network (NestGNN) as a generalization of the classical NL model in the neural network family. Theoretically, NestGNNs generalize the classical NL models and existing DNNs in terms of model representation, while retaining the crucial two-layer substitution patterns of the NL models: proportional substitution within a nest but non-proportional substitution beyond a nest. Empirically, we find that the NestGNNs significantly outperform the benchmark models, particularly the corresponding NL models by 9.2\%. As shown by elasticity tables and substitution visualization, NestGNNs retain the two-layer substitution patterns as the NL model, and yet presents more flexibility in its model design space. Overall, our study demonstrates the power of NestGNN in prediction, interpretation, and its flexibility of generalizing the classical NL model for analyzing travel mode choice.
GUI-G1: Understanding R1-Zero-Like Training for Visual Grounding in GUI Agents
May 21, 2025Recent Graphical User Interface (GUI) agents replicate the R1-Zero paradigm, coupling online Reinforcement Learning (RL) with explicit chain-of-thought reasoning prior to object grounding and thereby achieving substantial performance gains. In this paper, we first conduct extensive analysis experiments of three key components of that training pipeline: input design, output evaluation, and policy update-each revealing distinct challenges arising from blindly applying general-purpose RL without adapting to GUI grounding tasks. Input design: Current templates encourage the model to generate chain-of-thought reasoning, but longer chains unexpectedly lead to worse grounding performance. Output evaluation: Reward functions based on hit signals or box area allow models to exploit box size, leading to reward hacking and poor localization quality. Policy update: Online RL tends to overfit easy examples due to biases in length and sample difficulty, leading to under-optimization on harder cases. To address these issues, we propose three targeted solutions. First, we adopt a Fast Thinking Template that encourages direct answer generation, reducing excessive reasoning during training. Second, we incorporate a box size constraint into the reward function to mitigate reward hacking. Third, we revise the RL objective by adjusting length normalization and adding a difficulty-aware scaling factor, enabling better optimization on hard samples. Our GUI-G1-3B, trained on 17K public samples with Qwen2.5-VL-3B-Instruct, achieves 90.3% accuracy on ScreenSpot and 37.1% on ScreenSpot-Pro. This surpasses all prior models of similar size and even outperforms the larger UI-TARS-7B, establishing a new state-of-the-art in GUI agent grounding. The project repository is available at https://github.com/Yuqi-Zhou/GUI-G1.
Controlling Avatar Diffusion with Learnable Gaussian Embedding
Mar 20, 2025Recent advances in diffusion models have made significant progress in digital human generation. However, most existing models still struggle to maintain 3D consistency, temporal coherence, and motion accuracy. A key reason for these shortcomings is the limited representation ability of commonly used control signals(e.g., landmarks, depth maps, etc.). In addition, the lack of diversity in identity and pose variations in public datasets further hinders progress in this area. In this paper, we analyze the shortcomings of current control signals and introduce a novel control signal representation that is optimizable, dense, expressive, and 3D consistent. Our method embeds a learnable neural Gaussian onto a parametric head surface, which greatly enhances the consistency and expressiveness of diffusion-based head models. Regarding the dataset, we synthesize a large-scale dataset with multiple poses and identities. In addition, we use real/synthetic labels to effectively distinguish real and synthetic data, minimizing the impact of imperfections in synthetic data on the generated head images. Extensive experiments show that our model outperforms existing methods in terms of realism, expressiveness, and 3D consistency. Our code, synthetic datasets, and pre-trained models will be released in our project page: https://ustc3dv.github.io/Learn2Control/
CHOP: Mobile Operating Assistant with Constrained High-frequency Optimized Subtask Planning
Mar 05, 2025The advancement of visual language models (VLMs) has enhanced mobile device operations, allowing simulated human-like actions to address user requirements. Current VLM-based mobile operating assistants can be structured into three levels: task, subtask, and action. The subtask level, linking high-level goals with low-level executable actions, is crucial for task completion but faces two challenges: ineffective subtasks that lower-level agent cannot execute and inefficient subtasks that fail to contribute to the completion of the higher-level task. These challenges stem from VLM's lack of experience in decomposing subtasks within GUI scenarios in multi-agent architecture. To address these, we propose a new mobile assistant architecture with constrained high-frequency o}ptimized planning (CHOP). Our approach overcomes the VLM's deficiency in GUI scenarios planning by using human-planned subtasks as the basis vector. We evaluate our architecture in both English and Chinese contexts across 20 Apps, demonstrating significant improvements in both effectiveness and efficiency. Our dataset and code is available at https://github.com/Yuqi-Zhou/CHOP
Transmission Line Outage Probability Prediction Under Extreme Events Using Peter-Clark Bayesian Structural Learning
Nov 18, 2024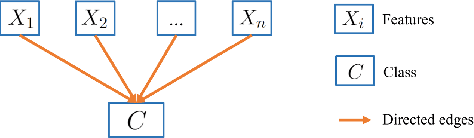
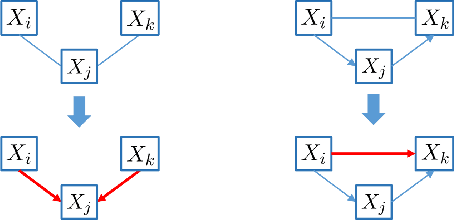
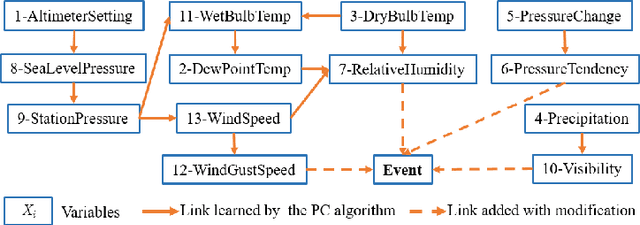
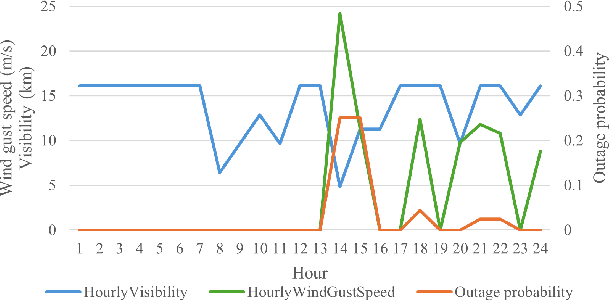
Recent years have seen a notable increase in the frequency and intensity of extreme weather events. With a rising number of power outages caused by these events, accurate prediction of power line outages is essential for safe and reliable operation of power grids. The Bayesian network is a probabilistic model that is very effective for predicting line outages under weather-related uncertainties. However, most existing studies in this area offer general risk assessments, but fall short of providing specific outage probabilities. In this work, we introduce a novel approach for predicting transmission line outage probabilities using a Bayesian network combined with Peter-Clark (PC) structural learning. Our approach not only enables precise outage probability calculations, but also demonstrates better scalability and robust performance, even with limited data. Case studies using data from BPA and NOAA show the effectiveness of this approach, while comparisons with several existing methods further highlight its advantages.
Length-Induced Embedding Collapse in Transformer-based Models
Oct 31, 2024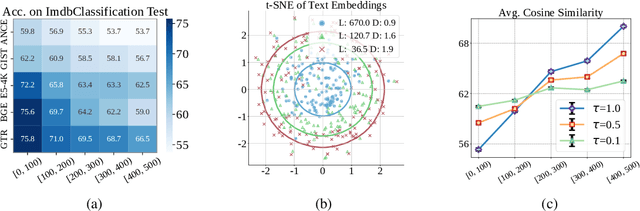
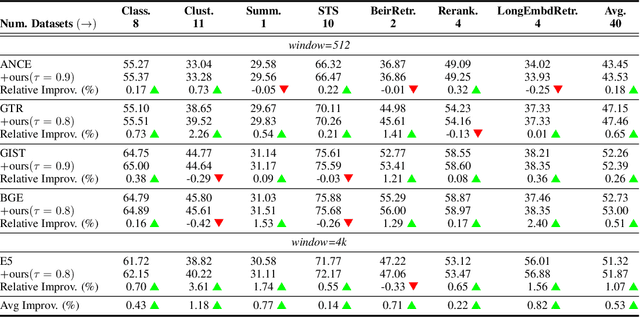
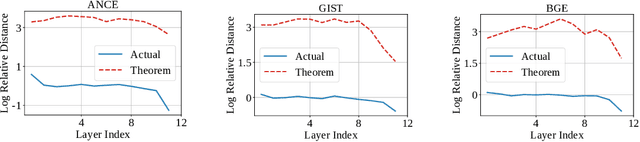

Text embeddings enable various applications, but their performance deteriorates on longer texts. In this paper, we find that the performance degradation is due to a phenomenon called Length Collapse, where longer text embeddings collapse into a narrow space. This collapse results in a distributional inconsistency between embeddings of different text lengths, ultimately hurting the performance of downstream tasks. Theoretically, by considering the self-attention mechanism inherently functions as a low-pass filter, we prove that long sequences increase the attenuation rate of the low-pass filter effect of the self-attention mechanism. With layers going deeper, excessive low-pass filtering causes the token signals to retain only their Direct-Current (DC) component, which means the input token feature maps will collapse into a narrow space, especially in long texts. Based on the above analysis, we propose to mitigate the undesirable length collapse limitation by introducing a temperature in softmax(), which achieves a higher low-filter attenuation rate. The tuning-free method, called TempScale, can be plugged into multiple transformer-based embedding models. Empirically, we demonstrate that TempScale can improve existing embedding models, especially on long text inputs, bringing up to 0.53% performance gains on 40 datasets from Massive Text Embedding Benchmark (MTEB) and 0.82% performance gains on 4 datasets from LongEmbed, which specifically focuses on long context retrieval.
Machine Learning for Equitable Load Shedding: Real-time Solution via Learning Binding Constraints
Jul 25, 2024



Timely and effective load shedding in power systems is critical for maintaining supply-demand balance and preventing cascading blackouts. To eliminate load shedding bias against specific regions in the system, optimization-based methods are uniquely positioned to help balance between economical and equity considerations. However, the resulting optimization problem involves complex constraints, which can be time-consuming to solve and thus cannot meet the real-time requirements of load shedding. To tackle this challenge, in this paper we present an efficient machine learning algorithm to enable millisecond-level computation for the optimization-based load shedding problem. Numerical studies on both a 3-bus toy example and a realistic RTS-GMLC system have demonstrated the validity and efficiency of the proposed algorithm for delivering equitable and real-time load shedding decisions.