 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Hard Negatives Hurt: Bridging the Generative-Discriminative Gap in Hard Negative Synthesis for Retrieval
May 31, 2026Hard negative mining has become the dominant strategy for training retrievers, yet it faces intrinsic limitations: negatives are bounded by corpus availability, selected by retriever score rather than diagnostic value, and increasingly contaminated by false positives as the retriever improves. LLM-based synthesis offers a principled alternative, where negatives that are unconstrained, targeted, and free from false positive risk. But we show that naively incorporating generated negatives into contrastive learning often degrades retrieval performance. We identify and formalize the root cause as a generative-discriminative gap: LLM generation optimizes for fluent, plausible text, while contrastive learning demands strategic violations of relevance at the decision boundary. Our analysis reveals two compounding failure modes: discriminative-agnostic generation, where the LLM lacks an explicit model of query information needs and defaults to generic or topic-drifted text that provides no contrastive signal; and source-dependent shortcuts, where distributional artifacts enable the model to distinguish negatives by origin rather than relevance, causing gradient drift that actively corrupts optimization. To close this gap, we propose CausalNeg consisting of two main modules: (1) CoT-guided counterfactual perturbation for data construction: decomposes why a document satisfies a query into explicit information requirements, then surgically violates individual requirements to construct negatives with controlled, interpretable hardness. (2) Query-view entropy maximization during training: disperses generated negatives across the similarity spectrum, minimizing the mutual information between source identity and similarity scores to suppress shortcut exploitation. We make our code publicly available at https://github.com/mzhangzhicheng/CausalNeg.
FairFS: Addressing Deep Feature Selection Biases for Recommender System
Feb 23, 2026Large-scale online marketplaces and recommender systems serve as critical technological support for e-commerce development. In industrial recommender systems, features play vital roles as they carry information for downstream models. Accurate feature importance estimation is critical because it helps identify the most useful feature subsets from thousands of feature candidates for online services. Such selection enables improved online performance while reducing computational cost. To address feature selection problems in deep learning, trainable gate-based and sensitivity-based methods have been proposed and proven effective in industrial practice. However, through the analysis of real-world cases, we identified three bias issues that cause feature importance estimation to rely on partial model layers, samples, or gradients, ultimately leading to inaccurate importance estimation. We refer to these as layer bias, baseline bias, and approximation bias. To mitigate these issues, we propose FairFS, a fair and accurate feature selection algorithm. FairFS regularizes feature importance estimated across all nonlinear transformation layers to address layer bias. It also introduces a smooth baseline feature close to the classifier decision boundary and adopts an aggregated approximation method to alleviate baseline and approximation biases. Extensive experiments demonstrate that FairFS effectively mitigates these biases and achieves state-of-the-art feature selection performance.
MALLOC: Benchmarking the Memory-aware Long Sequence Compression for Large Sequential Recommendation
Jan 29, 2026The scaling law, which indicates that model performance improves with increasing dataset and model capacity, has fueled a growing trend in expanding recommendation models in both industry and academia. However, the advent of large-scale recommenders also brings significantly higher computational costs, particularly under the long-sequence dependencies inherent in the user intent of recommendation systems. Current approaches often rely on pre-storing the intermediate states of the past behavior for each user, thereby reducing the quadratic re-computation cost for the following requests. Despite their effectiveness, these methods often treat memory merely as a medium for acceleration, without adequately considering the space overhead it introduces. This presents a critical challenge in real-world recommendation systems with billions of users, each of whom might initiate thousands of interactions and require massive memory for state storage. Fortunately, there have been several memory management strategies examined for compression in LLM, while most have not been evaluated on the recommendation task. To mitigate this gap, we introduce MALLOC, a comprehensive benchmark for memory-aware long sequence compression. MALLOC presents a comprehensive investigation and systematic classification of memory management techniques applicable to large sequential recommendations. These techniques are integrated into state-of-the-art recommenders, enabling a reproducible and accessible evaluation platform. Through extensive experiments across accuracy, efficiency, and complexity, we demonstrate the holistic reliability of MALLOC in advancing large-scale recommendation. Code is available at https://anonymous.4open.science/r/MALLOC.
Length-Adaptive Interest Network for Balancing Long and Short Sequence Modeling in CTR Prediction
Jan 27, 2026User behavior sequences in modern recommendation systems exhibit significant length heterogeneity, ranging from sparse short-term interactions to rich long-term histories. While longer sequences provide more context, we observe that increasing the maximum input sequence length in existing CTR models paradoxically degrades performance for short-sequence users due to attention polarization and length imbalance in training data. To address this, we propose LAIN(Length-Adaptive Interest Network), a plug-and-play framework that explicitly incorporates sequence length as a conditioning signal to balance long- and short-sequence modeling. LAIN consists of three lightweight components: a Spectral Length Encoder that maps length into continuous representations, Length-Conditioned Prompting that injects global contextual cues into both long- and short-term behavior branches, and Length-Modulated Attention that adaptively adjusts attention sharpness based on sequence length. Extensive experiments on three real-world benchmarks across five strong CTR backbones show that LAIN consistently improves overall performance, achieving up to 1.15% AUC gain and 2.25% log loss reduction. Notably, our method significantly improves accuracy for short-sequence users without sacrificing longsequence effectiveness. Our work offers a general, efficient, and deployable solution to mitigate length-induced bias in sequential recommendation.
CollectiveKV: Decoupling and Sharing Collaborative Information in Sequential Recommendation
Jan 27, 2026Sequential recommendation models are widely used in applications, yet they face stringent latency requirements. Mainstream models leverage the Transformer attention mechanism to improve performance, but its computational complexity grows with the sequence length, leading to a latency challenge for long sequences. Consequently, KV cache technology has recently been explored in sequential recommendation systems to reduce inference latency. However, KV cache introduces substantial storage overhead in sequential recommendation systems, which often have a large user base with potentially very long user history sequences. In this work, we observe that KV sequences across different users exhibit significant similarities, indicating the existence of collaborative signals in KV. Furthermore, we analyze the KV using singular value decomposition (SVD) and find that the information in KV can be divided into two parts: the majority of the information is shareable across users, while a small portion is user-specific. Motivated by this, we propose CollectiveKV, a cross-user KV sharing mechanism. It captures the information shared across users through a learnable global KV pool. During inference, each user retrieves high-dimensional shared KV from the pool and concatenates them with low-dimensional user-specific KV to obtain the final KV. Experiments on five sequential recommendation models and three datasets show that our method can compress the KV cache to only 0.8% of its original size, while maintaining or even enhancing model performance.
BlossomRec: Block-level Fused Sparse Attention Mechanism for Sequential Recommendations
Dec 15, 2025Transformer structures have been widely used in sequential recommender systems (SRS). However, as user interaction histories increase, computational time and memory requirements also grow. This is mainly caused by the standard attention mechanism. Although there exist many methods employing efficient attention and SSM-based models, these approaches struggle to effectively model long sequences and may exhibit unstable performance on short sequences. To address these challenges, we design a sparse attention mechanism, BlossomRec, which models both long-term and short-term user interests through attention computation to achieve stable performance across sequences of varying lengths. Specifically, we categorize user interests in recommendation systems into long-term and short-term interests, and compute them using two distinct sparse attention patterns, with the results combined through a learnable gated output. Theoretically, it significantly reduces the number of interactions participating in attention computation. Extensive experiments on four public datasets demonstrate that BlossomRec, when integrated with state-of-the-art Transformer-based models, achieves comparable or even superior performance while significantly reducing memory usage, providing strong evidence of BlossomRec's efficiency and effectiveness.The code is available at https://github.com/ronineume/BlossomRec.
No One Left Behind: How to Exploit the Incomplete and Skewed Multi-Label Data for Conversion Rate Prediction
Dec 15, 2025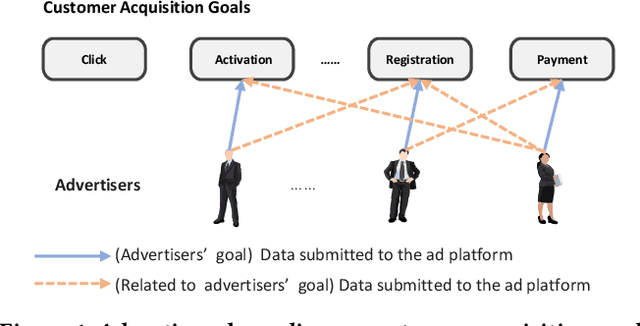

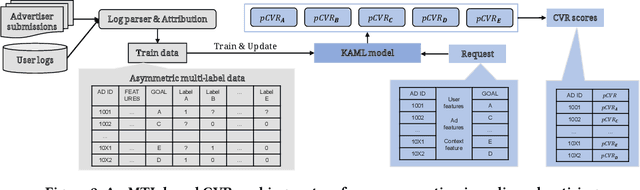
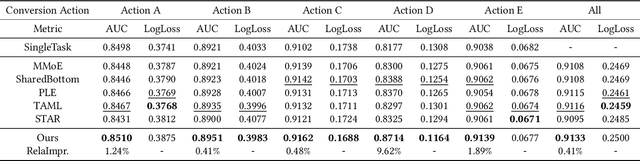
In most real-world online advertising systems, advertisers typically have diverse customer acquisition goals. A common solution is to use multi-task learning (MTL) to train a unified model on post-click data to estimate the conversion rate (CVR) for these diverse targets. In practice, CVR prediction often encounters missing conversion data as many advertisers submit only a subset of user conversion actions due to privacy or other constraints, making the labels of multi-task data incomplete. If the model is trained on all available samples where advertisers submit user conversion actions, it may struggle when deployed to serve a subset of advertisers targeting specific conversion actions, as the training and deployment data distributions are mismatched. While considerable MTL efforts have been made, a long-standing challenge is how to effectively train a unified model with the incomplete and skewed multi-label data. In this paper, we propose a fine-grained Knowledge transfer framework for Asymmetric Multi-Label data (KAML). We introduce an attribution-driven masking strategy (ADM) to better utilize data with asymmetric multi-label data in training. However, the more relaxed masking in ADM is a double-edged sword: it provides additional training signals but also introduces noise due to skewed data. To address this, we propose a hierarchical knowledge extraction mechanism (HKE) to model the sample discrepancy within the target task tower. Finally, to maximize the utility of unlabeled samples, we incorporate ranking loss strategy to further enhance our model. The effectiveness of KAML has been demonstrated through comprehensive evaluations on offline industry datasets and online A/B tests, which show significant performance improvements over existing MTL baselines.
Process vs. Outcome Reward: Which is Better for Agentic RAG Reinforcement Learning
May 20, 2025Retrieval-augmented generation (RAG) enhances the text generation capabilities of large language models (LLMs) by integrating external knowledge and up-to-date information. However, traditional RAG systems are limited by static workflows and lack the adaptability required for multistep reasoning and complex task management. To address these limitations, agentic RAG systems (e.g., DeepResearch) have been proposed, enabling dynamic retrieval strategies, iterative context refinement, and adaptive workflows for handling complex search queries beyond the capabilities of conventional RAG. Recent advances, such as Search-R1, have demonstrated promising gains using outcome-based reinforcement learning, where the correctness of the final answer serves as the reward signal. Nevertheless, such outcome-supervised agentic RAG methods face challenges including low exploration efficiency, gradient conflict, and sparse reward signals. To overcome these challenges, we propose to utilize fine-grained, process-level rewards to improve training stability, reduce computational costs, and enhance efficiency. Specifically, we introduce a novel method ReasonRAG that automatically constructs RAG-ProGuide, a high-quality dataset providing process-level rewards for (i) query generation, (ii) evidence extraction, and (iii) answer generation, thereby enhancing model inherent capabilities via process-supervised reinforcement learning. With the process-level policy optimization, the proposed framework empowers LLMs to autonomously invoke search, generate queries, extract relevant evidence, and produce final answers. Compared to existing approaches such as Search-R1 and traditional RAG systems, ReasonRAG, leveraging RAG-ProGuide, achieves superior performance on five benchmark datasets using only 5k training instances, significantly fewer than the 90k training instances required by Search-R1.
LSRP: A Leader-Subordinate Retrieval Framework for Privacy-Preserving Cloud-Device Collaboration
May 08, 2025Cloud-device collaboration leverages on-cloud Large Language Models (LLMs) for handling public user queries and on-device Small Language Models (SLMs) for processing private user data, collectively forming a powerful and privacy-preserving solution. However, existing approaches often fail to fully leverage the scalable problem-solving capabilities of on-cloud LLMs while underutilizing the advantage of on-device SLMs in accessing and processing personalized data. This leads to two interconnected issues: 1) Limited utilization of the problem-solving capabilities of on-cloud LLMs, which fail to align with personalized user-task needs, and 2) Inadequate integration of user data into on-device SLM responses, resulting in mismatches in contextual user information. In this paper, we propose a Leader-Subordinate Retrieval framework for Privacy-preserving cloud-device collaboration (LSRP), a novel solution that bridges these gaps by: 1) enhancing on-cloud LLM guidance to on-device SLM through a dynamic selection of task-specific leader strategies named as user-to-user retrieval-augmented generation (U-U-RAG), and 2) integrating the data advantages of on-device SLMs through small model feedback Direct Preference Optimization (SMFB-DPO) for aligning the on-cloud LLM with the on-device SLM. Experiments on two datasets demonstrate that LSRP consistently outperforms state-of-the-art baselines, significantly improving question-answer relevance and personalization, while preserving user privacy through efficient on-device retrieval. Our code is available at: https://github.com/Zhang-Yingyi/LSRP.
A Survey of Personalization: From RAG to Agent
Apr 14, 2025Personalization has become an essential capability in modern AI systems, enabling customized interactions that align with individual user preferences, contexts, and goals. Recent research has increasingly concentrated on Retrieval-Augmented Generation (RAG) frameworks and their evolution into more advanced agent-based architectures within personalized settings to enhance user satisfaction. Building on this foundation, this survey systematically examines personalization across the three core stages of RAG: pre-retrieval, retrieval, and generation. Beyond RAG, we further extend its capabilities into the realm of Personalized LLM-based Agents, which enhance traditional RAG systems with agentic functionalities, including user understanding, personalized planning and execution, and dynamic generation. For both personalization in RAG and agent-based personalization, we provide formal definitions, conduct a comprehensive review of recent literature, and summarize key datasets and evaluation metrics. Additionally, we discuss fundamental challenges, limitations, and promising research directions in this evolving field. Relevant papers and resources are continuously updated at https://github.com/Applied-Machine-Learning-Lab/Awesome-Personalized-RAG-Agent.