 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoRouter: Dynamic Paradigm Routing for Worldwide Image Geolocalization
Mar 25, 2026Worldwide image geolocalization aims to predict precise GPS coordinates for images captured anywhere on Earth, which is challenging due to the large visual and geographic diversity. Recent methods mainly follow two paradigms: retrieval-based approaches that match queries against a reference database, and generation-based approaches that directly predict coordinates using Large Vision-Language Models (LVLMs). However, we observe distinct error profiles between them: retrieval excels at fine-grained instance matching, while generation offers robust semantic reasoning. This complementary heterogeneity suggests that no single paradigm is universally superior. To harness this potential, we propose GeoRouter, a dynamic routing framework that adaptively assigns each query to the optimal paradigm. GeoRouter leverages an LVLM backbone to analyze visual content and provide routing decisions. To optimize GeoRouter, we introduce a distance-aware preference objective that converts the distance gap between paradigms into a continuous supervision signal, explicitly reflecting relative performance differences. Furthermore, we construct GeoRouting, the first large-scale dataset tailored for training routing policies with independent paradigm predictions. Extensive experiments on IM2GPS3k and YFCC4k demonstrate that GeoRouter significantly outperforms state-of-the-art baselines.
Evoking User Memory: Personalizing LLM via Recollection-Familiarity Adaptive Retrieval
Mar 10, 2026Personalized large language models (LLMs) rely on memory retrieval to incorporate user-specific histories, preferences, and contexts. Existing approaches either overload the LLM by feeding all the user's past memory into the prompt, which is costly and unscalable, or simplify retrieval into a one-shot similarity search, which captures only surface matches. Cognitive science, however, shows that human memory operates through a dual process: Familiarity, offering fast but coarse recognition, and Recollection, enabling deliberate, chain-like reconstruction for deeply recovering episodic content. Current systems lack both the ability to perform recollection retrieval and mechanisms to adaptively switch between the dual retrieval paths, leading to either insufficient recall or the inclusion of noise. To address this, we propose RF-Mem (Recollection-Familiarity Memory Retrieval), a familiarity uncertainty-guided dual-path memory retriever. RF-Mem measures the familiarity signal through the mean score and entropy. High familiarity leads to the direct top-K Familiarity retrieval path, while low familiarity activates the Recollection path. In the Recollection path, the system clusters candidate memories and applies alpha-mix with the query to iteratively expand evidence in embedding space, simulating deliberate contextual reconstruction. This design embeds human-like dual-process recognition into the retriever, avoiding full-context overhead and enabling scalable, adaptive personalization. Experiments across three benchmarks and corpus scales demonstrate that RF-Mem consistently outperforms both one-shot retrieval and full-context reasoning under fixed budget and latency constraints. Our code can be found in the Reproducibility Statement.
To Search or Not to Search: Aligning the Decision Boundary of Deep Search Agents via Causal Intervention
Feb 03, 2026Deep search agents, which autonomously iterate through multi-turn web-based reasoning, represent a promising paradigm for complex information-seeking tasks. However, current agents suffer from critical inefficiency: they conduct excessive searches as they cannot accurately judge when to stop searching and start answering. This stems from outcome-centric training that prioritize final results over the search process itself. We identify the root cause as misaligned decision boundaries, the threshold determining when accumulated information suffices to answer. This causes over-search (redundant searching despite sufficient knowledge) and under-search (premature termination yielding incorrect answers). To address these errors, we propose a comprehensive framework comprising two key components. First, we introduce causal intervention-based diagnosis that identifies boundary errors by comparing factual and counterfactual trajectories at each decision point. Second, we develop Decision Boundary Alignment for Deep Search agents (DAS), which constructs preference datasets from causal feedback and aligns policies via preference optimization. Experiments on public datasets demonstrate that decision boundary errors are pervasive across state-of-the-art agents. Our DAS method effectively calibrates these boundaries, mitigating both over-search and under-search to achieve substantial gains in accuracy and efficiency. Our code and data are publicly available at: https://github.com/Applied-Machine-Learning-Lab/WWW2026_DAS.
Exploring Recommender System Evaluation: A Multi-Modal User Agent Framework for A/B Testing
Jan 08, 2026In recommender systems, online A/B testing is a crucial method for evaluating the performance of different models. However, conducting online A/B testing often presents significant challenges, including substantial economic costs, user experience degradation, and considerable time requirements. With the Large Language Models' powerful capacity, LLM-based agent shows great potential to replace traditional online A/B testing. Nonetheless, current agents fail to simulate the perception process and interaction patterns, due to the lack of real environments and visual perception capability. To address these challenges, we introduce a multi-modal user agent for A/B testing (A/B Agent). Specifically, we construct a recommendation sandbox environment for A/B testing, enabling multimodal and multi-page interactions that align with real user behavior on online platforms. The designed agent leverages multimodal information perception, fine-grained user preferences, and integrates profiles, action memory retrieval, and a fatigue system to simulate complex human decision-making. We validated the potential of the agent as an alternative to traditional A/B testing from three perspectives: model, data, and features. Furthermore, we found that the data generated by A/B Agent can effectively enhance the capabilities of recommendation models. Our code is publicly available at https://github.com/Applied-Machine-Learning-Lab/ABAgent.
Process vs. Outcome Reward: Which is Better for Agentic RAG Reinforcement Learning
May 20, 2025Retrieval-augmented generation (RAG) enhances the text generation capabilities of large language models (LLMs) by integrating external knowledge and up-to-date information. However, traditional RAG systems are limited by static workflows and lack the adaptability required for multistep reasoning and complex task management. To address these limitations, agentic RAG systems (e.g., DeepResearch) have been proposed, enabling dynamic retrieval strategies, iterative context refinement, and adaptive workflows for handling complex search queries beyond the capabilities of conventional RAG. Recent advances, such as Search-R1, have demonstrated promising gains using outcome-based reinforcement learning, where the correctness of the final answer serves as the reward signal. Nevertheless, such outcome-supervised agentic RAG methods face challenges including low exploration efficiency, gradient conflict, and sparse reward signals. To overcome these challenges, we propose to utilize fine-grained, process-level rewards to improve training stability, reduce computational costs, and enhance efficiency. Specifically, we introduce a novel method ReasonRAG that automatically constructs RAG-ProGuide, a high-quality dataset providing process-level rewards for (i) query generation, (ii) evidence extraction, and (iii) answer generation, thereby enhancing model inherent capabilities via process-supervised reinforcement learning. With the process-level policy optimization, the proposed framework empowers LLMs to autonomously invoke search, generate queries, extract relevant evidence, and produce final answers. Compared to existing approaches such as Search-R1 and traditional RAG systems, ReasonRAG, leveraging RAG-ProGuide, achieves superior performance on five benchmark datasets using only 5k training instances, significantly fewer than the 90k training instances required by Search-R1.
A Survey of Personalization: From RAG to Agent
Apr 14, 2025Personalization has become an essential capability in modern AI systems, enabling customized interactions that align with individual user preferences, contexts, and goals. Recent research has increasingly concentrated on Retrieval-Augmented Generation (RAG) frameworks and their evolution into more advanced agent-based architectures within personalized settings to enhance user satisfaction. Building on this foundation, this survey systematically examines personalization across the three core stages of RAG: pre-retrieval, retrieval, and generation. Beyond RAG, we further extend its capabilities into the realm of Personalized LLM-based Agents, which enhance traditional RAG systems with agentic functionalities, including user understanding, personalized planning and execution, and dynamic generation. For both personalization in RAG and agent-based personalization, we provide formal definitions, conduct a comprehensive review of recent literature, and summarize key datasets and evaluation metrics. Additionally, we discuss fundamental challenges, limitations, and promising research directions in this evolving field. Relevant papers and resources are continuously updated at https://github.com/Applied-Machine-Learning-Lab/Awesome-Personalized-RAG-Agent.
Tired of Plugins? Large Language Models Can Be End-To-End Recommenders
Apr 07, 2024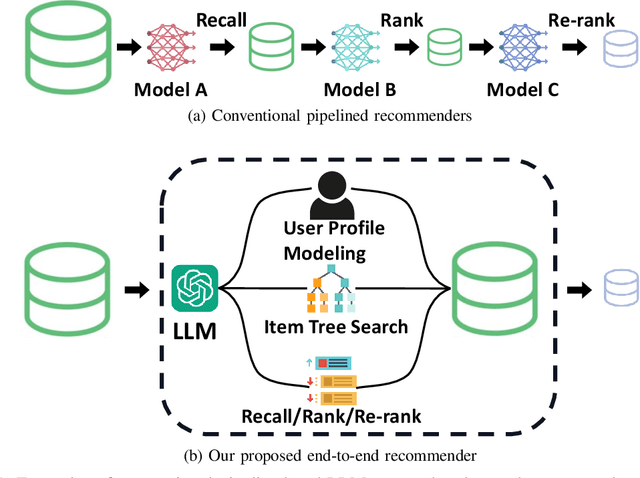
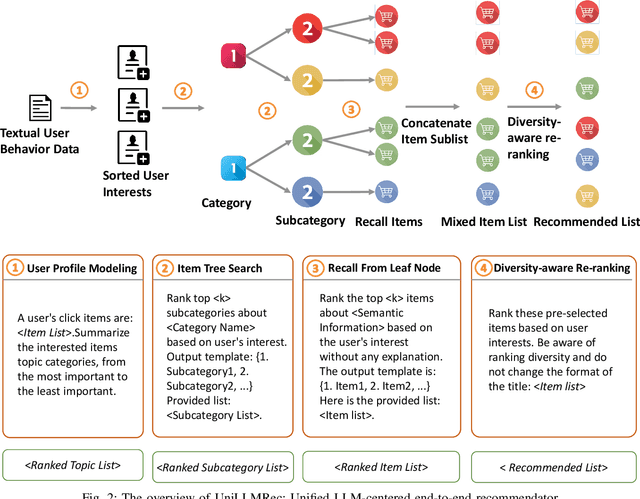
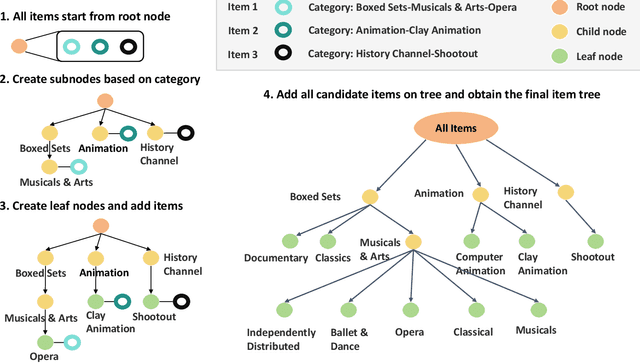
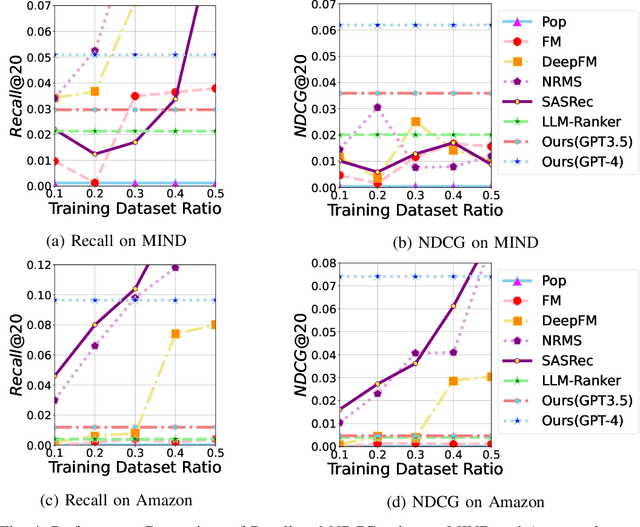
Recommender systems aim to predict user interest based on historical behavioral data. They are mainly designed in sequential pipelines, requiring lots of data to train different sub-systems, and are hard to scale to new domains. Recently, Large Language Models (LLMs) have demonstrated remarkable generalized capabilities, enabling a singular model to tackle diverse recommendation tasks across various scenarios. Nonetheless, existing LLM-based recommendation systems utilize LLM purely for a single task of the recommendation pipeline. Besides, these systems face challenges in presenting large-scale item sets to LLMs in natural language format, due to the constraint of input length. To address these challenges, we introduce an LLM-based end-to-end recommendation framework: UniLLMRec. Specifically, UniLLMRec integrates multi-stage tasks (e.g. recall, ranking, re-ranking) via chain-of-recommendations. To deal with large-scale items, we propose a novel strategy to structure all items into an item tree, which can be dynamically updated and effectively retrieved. UniLLMRec shows promising zero-shot results in comparison with conventional supervised models. Additionally, it boasts high efficiency, reducing the input token need by 86% compared to existing LLM-based models. Such efficiency not only accelerates task completion but also optimizes resource utilization. To facilitate model understanding and to ensure reproducibility, we have made our code publicly available.
Depth-induced Saliency Comparison Network for Diagnosis of Alzheimer's Disease via Jointly Analysis of Visual Stimuli and Eye Movements
Mar 15, 2024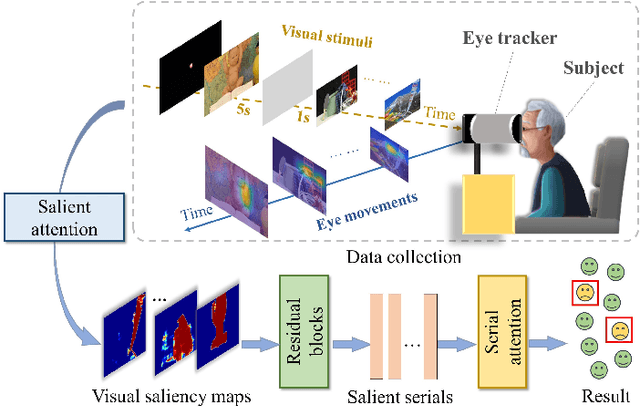
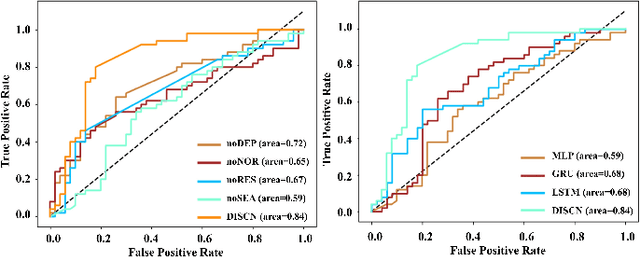
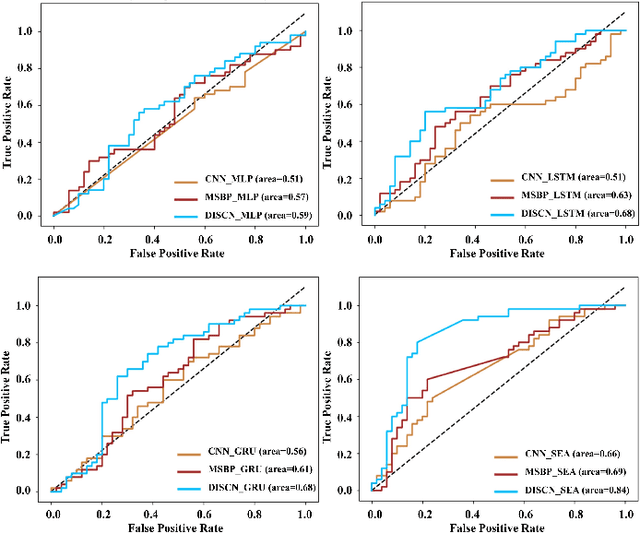
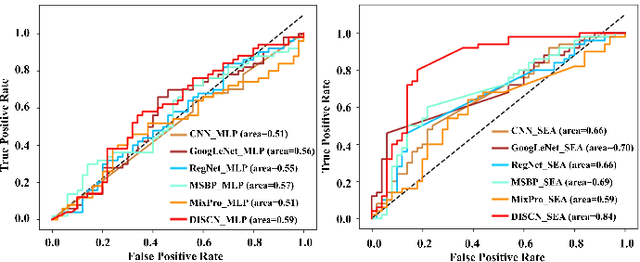
Early diagnosis of Alzheimer's Disease (AD) is very important for following medical treatments, and eye movements under special visual stimuli may serve as a potential non-invasive biomarker for detecting cognitive abnormalities of AD patients. In this paper, we propose an Depth-induced saliency comparison network (DISCN) for eye movement analysis, which may be used for diagnosis the Alzheimers disease. In DISCN, a salient attention module fuses normal eye movements with RGB and depth maps of visual stimuli using hierarchical salient attention (SAA) to evaluate comprehensive saliency maps, which contain information from both visual stimuli and normal eye movement behaviors. In addition, we introduce serial attention module (SEA) to emphasis the most abnormal eye movement behaviors to reduce personal bias for a more robust result. According to our experiments, the DISCN achieves consistent validity in classifying the eye movements between the AD patients and normal controls.
Knowledge Unlearning for LLMs: Tasks, Methods, and Challenges
Dec 08, 2023



In recent years, large language models (LLMs) have spurred a new research paradigm in natural language processing. Despite their excellent capability in knowledge-based question answering and reasoning, their potential to retain faulty or even harmful knowledge poses risks of malicious application. The challenge of mitigating this issue and transforming these models into purer assistants is crucial for their widespread applicability. Unfortunately, Retraining LLMs repeatedly to eliminate undesirable knowledge is impractical due to their immense parameters. Knowledge unlearning, derived from analogous studies on machine unlearning, presents a promising avenue to address this concern and is notably advantageous in the context of LLMs. It allows for the removal of harmful knowledge in an efficient manner, without affecting unrelated knowledge in the model. To this end, we provide a survey of knowledge unlearning in the era of LLMs. Firstly, we formally define the knowledge unlearning problem and distinguish it from related works. Subsequently, we categorize existing knowledge unlearning methods into three classes: those based on parameter optimization, parameter merging, and in-context learning, and introduce details of these unlearning methods. We further present evaluation datasets used in existing methods, and finally conclude this survey by presenting the ongoing challenges and future directions.
Tuning Large language model for End-to-end Speech Translation
Oct 03, 2023



With the emergence of large language models (LLMs), multimodal models based on LLMs have demonstrated significant potential. Models such as LLaSM, X-LLM, and SpeechGPT exhibit an impressive ability to comprehend and generate human instructions. However, their performance often falters when faced with complex tasks like end-to-end speech translation (E2E-ST), a cross-language and cross-modal translation task. In comparison to single-modal models, multimodal models lag behind in these scenarios. This paper introduces LST, a Large multimodal model designed to excel at the E2E-ST task. LST consists of a speech frontend, an adapter, and a LLM backend. The training of LST consists of two stages: (1) Modality adjustment, where the adapter is tuned to align speech representation with text embedding space, and (2) Downstream task fine-tuning, where both the adapter and LLM model are trained to optimize performance on the E2EST task. Experimental results on the MuST-C speech translation benchmark demonstrate that LST-13B achieves BLEU scores of 30.39/41.55/35.33 on En-De/En-Fr/En-Es language pairs, surpassing previous models and establishing a new state-of-the-art. Additionally, we conduct an in-depth analysis of single-modal model selection and the impact of training strategies, which lays the foundation for future research. We will open up our code and models after review.