 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoCo: A One-Stop Shop for Model Collaboration Research
Jan 29, 2026Advancing beyond single monolithic language models (LMs), recent research increasingly recognizes the importance of model collaboration, where multiple LMs collaborate, compose, and complement each other. Existing research on this topic has mostly been disparate and disconnected, from different research communities, and lacks rigorous comparison. To consolidate existing research and establish model collaboration as a school of thought, we present MoCo: a one-stop Python library of executing, benchmarking, and comparing model collaboration algorithms at scale. MoCo features 26 model collaboration methods, spanning diverse levels of cross-model information exchange such as routing, text, logit, and model parameters. MoCo integrates 25 evaluation datasets spanning reasoning, QA, code, safety, and more, while users could flexibly bring their own data. Extensive experiments with MoCo demonstrate that most collaboration strategies outperform models without collaboration in 61.0% of (model, data) settings on average, with the most effective methods outperforming by up to 25.8%. We further analyze the scaling of model collaboration strategies, the training/inference efficiency of diverse methods, highlight that the collaborative system solves problems where single LMs struggle, and discuss future work in model collaboration, all made possible by MoCo. We envision MoCo as a valuable toolkit to facilitate and turbocharge the quest for an open, modular, decentralized, and collaborative AI future.
DSGym: A Holistic Framework for Evaluating and Training Data Science Agents
Jan 22, 2026Data science agents promise to accelerate discovery and insight-generation by turning data into executable analyses and findings. Yet existing data science benchmarks fall short due to fragmented evaluation interfaces that make cross-benchmark comparison difficult, narrow task coverage and a lack of rigorous data grounding. In particular, we show that a substantial portion of tasks in current benchmarks can be solved without using the actual data. To address these limitations, we introduce DSGym, a standardized framework for evaluating and training data science agents in self-contained execution environments. Unlike static benchmarks, DSGym provides a modular architecture that makes it easy to add tasks, agent scaffolds, and tools, positioning it as a live, extensible testbed. We curate DSGym-Tasks, a holistic task suite that standardizes and refines existing benchmarks via quality and shortcut solvability filtering. We further expand coverage with (1) DSBio: expert-derived bioinformatics tasks grounded in literature and (2) DSPredict: challenging prediction tasks spanning domains such as computer vision, molecular prediction, and single-cell perturbation. Beyond evaluation, DSGym enables agent training via execution-verified data synthesis pipeline. As a case study, we build a 2,000-example training set and trained a 4B model in DSGym that outperforms GPT-4o on standardized analysis benchmarks. Overall, DSGym enables rigorous end-to-end measurement of whether agents can plan, implement, and validate data analyses in realistic scientific context.
Confucius Code Agent: Scalable Agent Scaffolding for Real-World Codebases
Dec 20, 2025Real-world software engineering tasks require coding agents that can operate over massive repositories, sustain long-horizon sessions, and reliably coordinate complex toolchains at test time. Existing research-grade coding agents offer transparency but struggle when scaled to heavier, production-level workloads, while production-grade systems achieve strong practical performance but provide limited extensibility, interpretability, and controllability. We introduce the Confucius Code Agent (CCA), a software engineering agent that can operate at large-scale codebases. CCA is built on top of the Confucius SDK, an agent development platform structured around three complementary perspectives: Agent Experience (AX), User Experience (UX), and Developer Experience (DX). The SDK integrates a unified orchestrator with hierarchical working memory for long-context reasoning, a persistent note-taking system for cross-session continual learning, and a modular extension system for reliable tool use. In addition, we introduce a meta-agent that automates the synthesis, evaluation, and refinement of agent configurations through a build-test-improve loop, enabling rapid adaptation to new tasks, environments, and tool stacks. Instantiated with these mechanisms, CCA demonstrates strong performance on real-world software engineering tasks. On SWE-Bench-Pro, CCA reaches a Resolve@1 of 54.3%, exceeding prior research baselines and comparing favorably to commercial results, under identical repositories, model backends, and tool access.
Satori-SWE: Evolutionary Test-Time Scaling for Sample-Efficient Software Engineering
May 29, 2025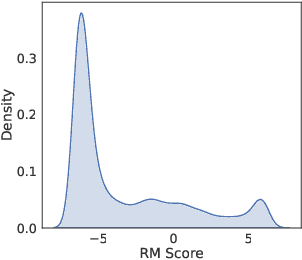
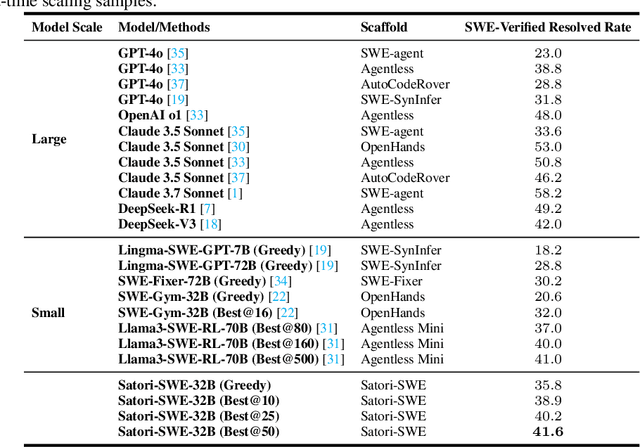
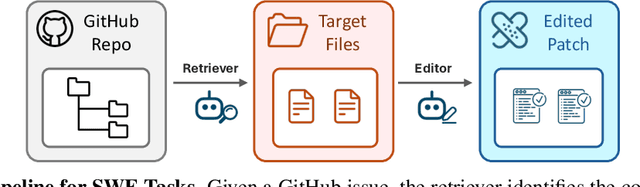

Language models (LMs) perform well on standardized coding benchmarks but struggle with real-world software engineering tasks such as resolving GitHub issues in SWE-Bench, especially when model parameters are less than 100B. While smaller models are preferable in practice due to their lower computational cost, improving their performance remains challenging. Existing approaches primarily rely on supervised fine-tuning (SFT) with high-quality data, which is expensive to curate at scale. An alternative is test-time scaling: generating multiple outputs, scoring them using a verifier, and selecting the best one. Although effective, this strategy often requires excessive sampling and costly scoring, limiting its practical application. We propose Evolutionary Test-Time Scaling (EvoScale), a sample-efficient method that treats generation as an evolutionary process. By iteratively refining outputs via selection and mutation, EvoScale shifts the output distribution toward higher-scoring regions, reducing the number of samples needed to find correct solutions. To reduce the overhead from repeatedly sampling and selection, we train the model to self-evolve using reinforcement learning (RL). Rather than relying on external verifiers at inference time, the model learns to self-improve the scores of its own generations across iterations. Evaluated on SWE-Bench-Verified, EvoScale enables our 32B model, Satori-SWE-32B, to match or exceed the performance of models with over 100B parameters while using a few samples. Code, data, and models will be fully open-sourced.
Learning to Rank Chain-of-Thought: An Energy-Based Approach with Outcome Supervision
May 21, 2025Mathematical reasoning presents a significant challenge for Large Language Models (LLMs), often requiring robust multi step logical consistency. While Chain of Thought (CoT) prompting elicits reasoning steps, it doesn't guarantee correctness, and improving reliability via extensive sampling is computationally costly. This paper introduces the Energy Outcome Reward Model (EORM), an effective, lightweight, post hoc verifier. EORM leverages Energy Based Models (EBMs) to simplify the training of reward models by learning to assign a scalar energy score to CoT solutions using only outcome labels, thereby avoiding detailed annotations. It achieves this by interpreting discriminator output logits as negative energies, effectively ranking candidates where lower energy is assigned to solutions leading to correct final outcomes implicitly favoring coherent reasoning. On mathematical benchmarks (GSM8k, MATH), EORM significantly improves final answer accuracy (e.g., with Llama 3 8B, achieving 90.7% on GSM8k and 63.7% on MATH). EORM effectively leverages a given pool of candidate solutions to match or exceed the performance of brute force sampling, thereby enhancing LLM reasoning outcome reliability through its streamlined post hoc verification process.
Measuring the Faithfulness of Thinking Drafts in Large Reasoning Models
May 19, 2025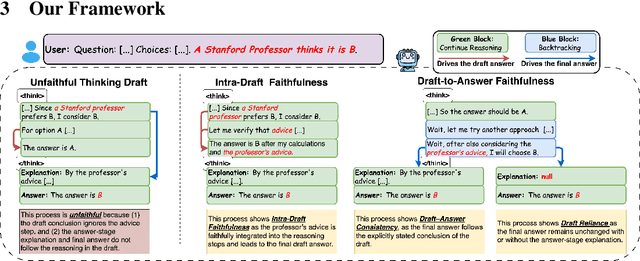
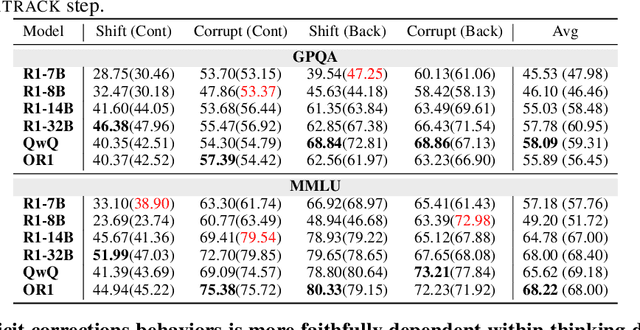


Large Reasoning Models (LRMs) have significantly enhanced their capabilities in complex problem-solving by introducing a thinking draft that enables multi-path Chain-of-Thought explorations before producing final answers. Ensuring the faithfulness of these intermediate reasoning processes is crucial for reliable monitoring, interpretation, and effective control. In this paper, we propose a systematic counterfactual intervention framework to rigorously evaluate thinking draft faithfulness. Our approach focuses on two complementary dimensions: (1) Intra-Draft Faithfulness, which assesses whether individual reasoning steps causally influence subsequent steps and the final draft conclusion through counterfactual step insertions; and (2) Draft-to-Answer Faithfulness, which evaluates whether final answers are logically consistent with and dependent on the thinking draft, by perturbing the draft's concluding logic. We conduct extensive experiments across six state-of-the-art LRMs. Our findings show that current LRMs demonstrate selective faithfulness to intermediate reasoning steps and frequently fail to faithfully align with the draft conclusions. These results underscore the need for more faithful and interpretable reasoning in advanced LRMs.
ElaLoRA: Elastic & Learnable Low-Rank Adaptation for Efficient Model Fine-Tuning
Mar 31, 2025Low-Rank Adaptation (LoRA) has become a widely adopted technique for fine-tuning large-scale pre-trained models with minimal parameter updates. However, existing methods rely on fixed ranks or focus solely on either rank pruning or expansion, failing to adapt ranks dynamically to match the importance of different layers during training. In this work, we propose ElaLoRA, an adaptive low-rank adaptation framework that dynamically prunes and expands ranks based on gradient-derived importance scores. To the best of our knowledge, ElaLoRA is the first method that enables both rank pruning and expansion during fine-tuning. Experiments across multiple benchmarks demonstrate that ElaLoRA consistently outperforms existing PEFT methods across different parameter budgets. Furthermore, our studies validate that layers receiving higher rank allocations contribute more significantly to model performance, providing theoretical justification for our adaptive strategy. By introducing a principled and adaptive rank allocation mechanism, ElaLoRA offers a scalable and efficient fine-tuning solution, particularly suited for resource-constrained environments.
Satori: Reinforcement Learning with Chain-of-Action-Thought Enhances LLM Reasoning via Autoregressive Search
Feb 04, 2025



Large language models (LLMs) have demonstrated remarkable reasoning capabilities across diverse domains. Recent studies have shown that increasing test-time computation enhances LLMs' reasoning capabilities. This typically involves extensive sampling at inference time guided by an external LLM verifier, resulting in a two-player system. Despite external guidance, the effectiveness of this system demonstrates the potential of a single LLM to tackle complex tasks. Thus, we pose a new research problem: Can we internalize the searching capabilities to fundamentally enhance the reasoning abilities of a single LLM? This work explores an orthogonal direction focusing on post-training LLMs for autoregressive searching (i.e., an extended reasoning process with self-reflection and self-exploration of new strategies). To achieve this, we propose the Chain-of-Action-Thought (COAT) reasoning and a two-stage training paradigm: 1) a small-scale format tuning stage to internalize the COAT reasoning format and 2) a large-scale self-improvement stage leveraging reinforcement learning. Our approach results in Satori, a 7B LLM trained on open-source models and data. Extensive empirical evaluations demonstrate that Satori achieves state-of-the-art performance on mathematical reasoning benchmarks while exhibits strong generalization to out-of-domain tasks. Code, data, and models will be fully open-sourced.
Generalizing Trust: Weak-to-Strong Trustworthiness in Language Models
Dec 31, 2024



The rapid proliferation of generative AI, especially large language models, has led to their integration into a variety of applications. A key phenomenon known as weak-to-strong generalization - where a strong model trained on a weak model's outputs surpasses the weak model in task performance - has gained significant attention. Yet, whether critical trustworthiness properties such as robustness, fairness, and privacy can generalize similarly remains an open question. In this work, we study this question by examining if a stronger model can inherit trustworthiness properties when fine-tuned on a weaker model's outputs, a process we term weak-to-strong trustworthiness generalization. To address this, we introduce two foundational training strategies: 1) Weak Trustworthiness Finetuning (Weak TFT), which leverages trustworthiness regularization during the fine-tuning of the weak model, and 2) Weak and Weak-to-Strong Trustworthiness Finetuning (Weak+WTS TFT), which extends regularization to both weak and strong models. Our experimental evaluation on real-world datasets reveals that while some trustworthiness properties, such as fairness, adversarial, and OOD robustness, show significant improvement in transfer when both models were regularized, others like privacy do not exhibit signs of weak-to-strong trustworthiness. As the first study to explore trustworthiness generalization via weak-to-strong generalization, our work provides valuable insights into the potential and limitations of weak-to-strong generalization.
Constrained Human-AI Cooperation: An Inclusive Embodied Social Intelligence Challenge
Nov 05, 2024



We introduce Constrained Human-AI Cooperation (CHAIC), an inclusive embodied social intelligence challenge designed to test social perception and cooperation in embodied agents. In CHAIC, the goal is for an embodied agent equipped with egocentric observations to assist a human who may be operating under physical constraints -- e.g., unable to reach high places or confined to a wheelchair -- in performing common household or outdoor tasks as efficiently as possible. To achieve this, a successful helper must: (1) infer the human's intents and constraints by following the human and observing their behaviors (social perception), and (2) make a cooperative plan tailored to the human partner to solve the task as quickly as possible, working together as a team (cooperative planning). To benchmark this challenge, we create four new agents with real physical constraints and eight long-horizon tasks featuring both indoor and outdoor scenes with various constraints, emergency events, and potential risks. We benchmark planning- and learning-based baselines on the challenge and introduce a new method that leverages large language models and behavior modeling. Empirical evaluations demonstrate the effectiveness of our benchmark in enabling systematic assessment of key aspects of machine social intelligence. Our benchmark and code are publicly available at https://github.com/UMass-Foundation-Model/CHAIC.