 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Role of Hallucination in Reinforcement Post-Training of Multimodal Reasoning Models
Apr 03, 2026The recent success of reinforcement learning (RL) in large reasoning models has inspired the growing adoption of RL for post-training Multimodal Large Language Models (MLLMs) to enhance their visual reasoning capabilities. Although many studies have reported improved performance, it remains unclear whether RL training truly enables models to learn from visual information. In this work, we propose the Hallucination-as-Cue Framework, an analytical framework designed to investigate the effects of RL-based post-training on multimodal reasoning models from the perspective of model hallucination. Specifically, we introduce hallucination-inductive, modality-specific corruptions that remove or replace essential information required to derive correct answers, thereby forcing the model to reason by hallucination. By applying these corruptions during both training and evaluation, our framework provides a unique perspective for diagnosing RL training dynamics and understanding the intrinsic properties of datasets. Through extensive experiments and analyses across multiple multimodal reasoning benchmarks, we reveal that the role of model hallucination for RL-training is more significant than previously recognized. For instance, we find that RL post-training under purely hallucination-inductive settings can still significantly improve models' reasoning performance, and in some cases even outperform standard training. These findings challenge prevailing assumptions about MLLM reasoning training and motivate the development of more modality-aware RL-based training designs.
Learning Robust Reasoning through Guided Adversarial Self-Play
Jan 30, 2026Reinforcement learning from verifiable rewards (RLVR) produces strong reasoning models, yet they can fail catastrophically when the conditioning context is fallible (e.g., corrupted chain-of-thought, misleading partial solutions, or mild input perturbations), since standard RLVR optimizes final-answer correctness only under clean conditioning. We introduce GASP (Guided Adversarial Self-Play), a robustification method that explicitly trains detect-and-repair capabilities using only outcome verification. Without human labels or external teachers, GASP forms an adversarial self-play game within a single model: a polluter learns to induce failure via locally coherent corruptions, while an agent learns to diagnose and recover under the same corrupted conditioning. To address the scarcity of successful recoveries early in training, we propose in-distribution repair guidance, an imitation term on self-generated repairs that increases recovery probability while preserving previously acquired capabilities. Across four open-weight models (1.5B--8B), GASP transforms strong-but-brittle reasoners into robust ones that withstand misleading and perturbed context while often improving clean accuracy. Further analysis shows that adversarial corruptions induce an effective curriculum, and in-distribution guidance enables rapid recovery learning with minimal representational drift.
Metacognitive Self-Correction for Multi-Agent System via Prototype-Guided Next-Execution Reconstruction
Oct 16, 2025Large Language Model based multi-agent systems (MAS) excel at collaborative problem solving but remain brittle to cascading errors: a single faulty step can propagate across agents and disrupt the trajectory. In this paper, we present MASC, a metacognitive framework that endows MAS with real-time, unsupervised, step-level error detection and self-correction. MASC rethinks detection as history-conditioned anomaly scoring via two complementary designs: (1) Next-Execution Reconstruction, which predicts the embedding of the next step from the query and interaction history to capture causal consistency, and (2) Prototype-Guided Enhancement, which learns a prototype prior over normal-step embeddings and uses it to stabilize reconstruction and anomaly scoring under sparse context (e.g., early steps). When an anomaly step is flagged, MASC triggers a correction agent to revise the acting agent's output before information flows downstream. On the Who&When benchmark, MASC consistently outperforms all baselines, improving step-level error detection by up to 8.47% AUC-ROC ; When plugged into diverse MAS frameworks, it delivers consistent end-to-end gains across architectures, confirming that our metacognitive monitoring and targeted correction can mitigate error propagation with minimal overhead.
Learning Physical Interaction Skills from Human Demonstrations
Jul 28, 2025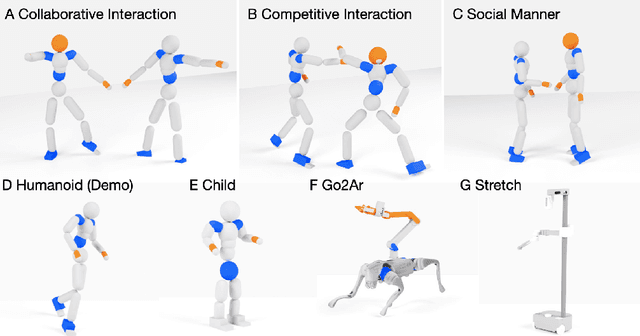
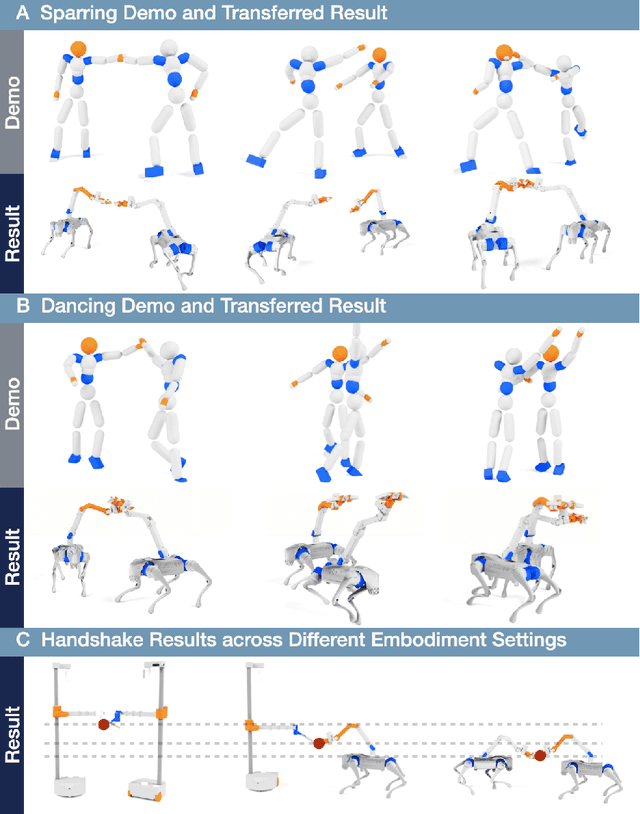
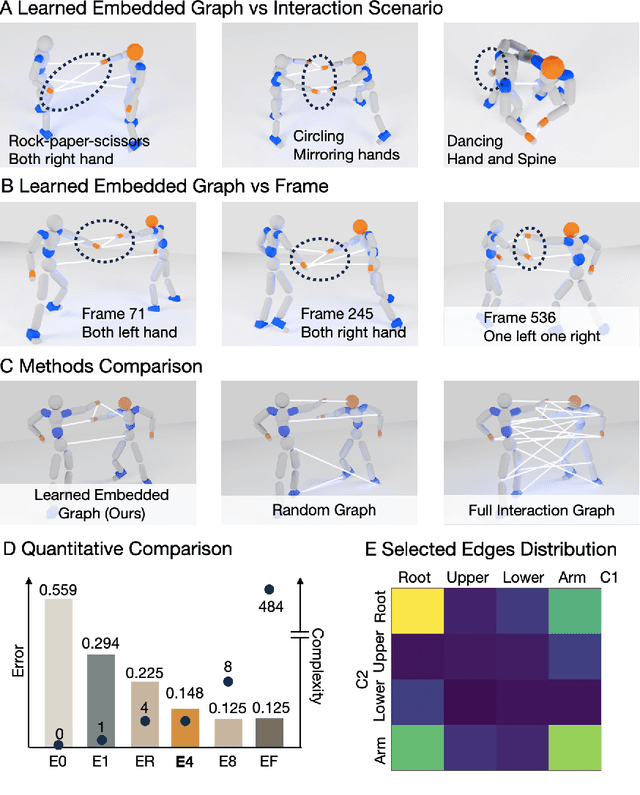
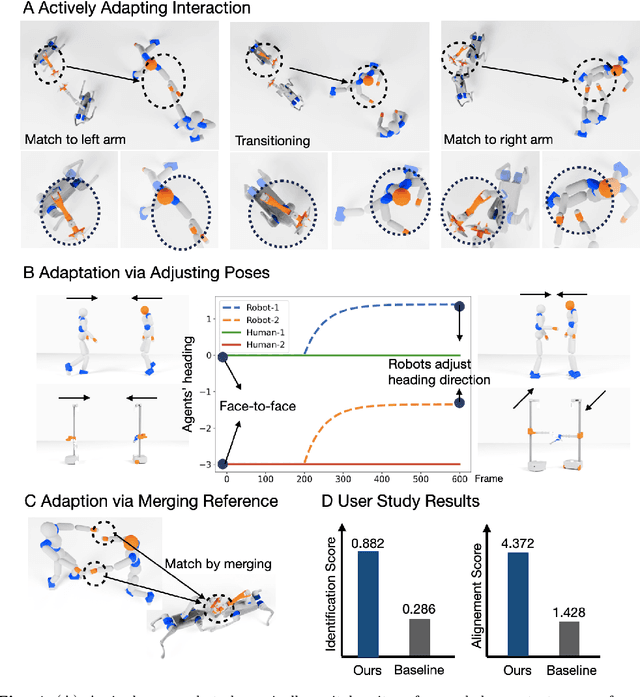
Learning physical interaction skills, such as dancing, handshaking, or sparring, remains a fundamental challenge for agents operating in human environments, particularly when the agent's morphology differs significantly from that of the demonstrator. Existing approaches often rely on handcrafted objectives or morphological similarity, limiting their capacity for generalization. Here, we introduce a framework that enables agents with diverse embodiments to learn wholebbody interaction behaviors directly from human demonstrations. The framework extracts a compact, transferable representation of interaction dynamics, called the Embedded Interaction Graph (EIG), which captures key spatiotemporal relationships between the interacting agents. This graph is then used as an imitation objective to train control policies in physics-based simulations, allowing the agent to generate motions that are both semantically meaningful and physically feasible. We demonstrate BuddyImitation on multiple agents, such as humans, quadrupedal robots with manipulators, or mobile manipulators and various interaction scenarios, including sparring, handshaking, rock-paper-scissors, or dancing. Our results demonstrate a promising path toward coordinated behaviors across morphologically distinct characters via cross embodiment interaction learning.
Efficient MAP Estimation of LLM Judgment Performance with Prior Transfer
Apr 17, 2025



LLM ensembles are widely used for LLM judges. However, how to estimate their accuracy, especially in an efficient way, is unknown. In this paper, we present a principled maximum a posteriori (MAP) framework for an economical and precise estimation of the performance of LLM ensemble judgment. We first propose a mixture of Beta-Binomial distributions to model the judgment distribution, revising from the vanilla Binomial distribution. Next, we introduce a conformal prediction-driven approach that enables adaptive stopping during iterative sampling to balance accuracy with efficiency. Furthermore, we design a prior transfer mechanism that utilizes learned distributions on open-source datasets to improve estimation on a target dataset when only scarce annotations are available. Finally, we present BetaConform, a framework that integrates our distribution assumption, adaptive stopping, and the prior transfer mechanism to deliver a theoretically guaranteed distribution estimation of LLM ensemble judgment with minimum labeled samples. BetaConform is also validated empirically. For instance, with only 10 samples from the TruthfulQA dataset, for a Llama ensembled judge, BetaConform gauges its performance with error margin as small as 3.37%.
GFlowVLM: Enhancing Multi-step Reasoning in Vision-Language Models with Generative Flow Networks
Mar 09, 2025



Vision-Language Models (VLMs) have recently shown promising advancements in sequential decision-making tasks through task-specific fine-tuning. However, common fine-tuning methods, such as Supervised Fine-Tuning (SFT) and Reinforcement Learning (RL) techniques like Proximal Policy Optimization (PPO), present notable limitations: SFT assumes Independent and Identically Distributed (IID) data, while PPO focuses on maximizing cumulative rewards. These limitations often restrict solution diversity and hinder generalization in multi-step reasoning tasks. To address these challenges, we introduce a novel framework, GFlowVLM, a framework that fine-tune VLMs using Generative Flow Networks (GFlowNets) to promote generation of diverse solutions for complex reasoning tasks. GFlowVLM models the environment as a non-Markovian decision process, allowing it to capture long-term dependencies essential for real-world applications. It takes observations and task descriptions as inputs to prompt chain-of-thought (CoT) reasoning which subsequently guides action selection. We use task based rewards to fine-tune VLM with GFlowNets. This approach enables VLMs to outperform prior fine-tuning methods, including SFT and RL. Empirical results demonstrate the effectiveness of GFlowVLM on complex tasks such as card games (NumberLine, BlackJack) and embodied planning tasks (ALFWorld), showing enhanced training efficiency, solution diversity, and stronger generalization capabilities across both in-distribution and out-of-distribution scenarios.
Can Hallucination Correction Improve Video-Language Alignment?
Feb 20, 2025Large Vision-Language Models often generate hallucinated content that is not grounded in its visual inputs. While prior work focuses on mitigating hallucinations, we instead explore leveraging hallucination correction as a training objective to improve video-language alignment. We introduce HACA, a self-training framework learning to correct hallucinations in descriptions that do not align with the video content. By identifying and correcting inconsistencies, HACA enhances the model's ability to align video and textual representations for spatio-temporal reasoning. Our experimental results show consistent gains in video-caption binding and text-to-video retrieval tasks, demonstrating that hallucination correction-inspired tasks serve as an effective strategy for improving vision and language alignment.
Generalized Mission Planning for Heterogeneous Multi-Robot Teams via LLM-constructed Hierarchical Trees
Jan 27, 2025We present a novel mission-planning strategy for heterogeneous multi-robot teams, taking into account the specific constraints and capabilities of each robot. Our approach employs hierarchical trees to systematically break down complex missions into manageable sub-tasks. We develop specialized APIs and tools, which are utilized by Large Language Models (LLMs) to efficiently construct these hierarchical trees. Once the hierarchical tree is generated, it is further decomposed to create optimized schedules for each robot, ensuring adherence to their individual constraints and capabilities. We demonstrate the effectiveness of our framework through detailed examples covering a wide range of missions, showcasing its flexibility and scalability.
Constrained Human-AI Cooperation: An Inclusive Embodied Social Intelligence Challenge
Nov 05, 2024



We introduce Constrained Human-AI Cooperation (CHAIC), an inclusive embodied social intelligence challenge designed to test social perception and cooperation in embodied agents. In CHAIC, the goal is for an embodied agent equipped with egocentric observations to assist a human who may be operating under physical constraints -- e.g., unable to reach high places or confined to a wheelchair -- in performing common household or outdoor tasks as efficiently as possible. To achieve this, a successful helper must: (1) infer the human's intents and constraints by following the human and observing their behaviors (social perception), and (2) make a cooperative plan tailored to the human partner to solve the task as quickly as possible, working together as a team (cooperative planning). To benchmark this challenge, we create four new agents with real physical constraints and eight long-horizon tasks featuring both indoor and outdoor scenes with various constraints, emergency events, and potential risks. We benchmark planning- and learning-based baselines on the challenge and introduce a new method that leverages large language models and behavior modeling. Empirical evaluations demonstrate the effectiveness of our benchmark in enabling systematic assessment of key aspects of machine social intelligence. Our benchmark and code are publicly available at https://github.com/UMass-Foundation-Model/CHAIC.
Estimating Ego-Body Pose from Doubly Sparse Egocentric Video Data
Nov 05, 2024



We study the problem of estimating the body movements of a camera wearer from egocentric videos. Current methods for ego-body pose estimation rely on temporally dense sensor data, such as IMU measurements from spatially sparse body parts like the head and hands. However, we propose that even temporally sparse observations, such as hand poses captured intermittently from egocentric videos during natural or periodic hand movements, can effectively constrain overall body motion. Naively applying diffusion models to generate full-body pose from head pose and sparse hand pose leads to suboptimal results. To overcome this, we develop a two-stage approach that decomposes the problem into temporal completion and spatial completion. First, our method employs masked autoencoders to impute hand trajectories by leveraging the spatiotemporal correlations between the head pose sequence and intermittent hand poses, providing uncertainty estimates. Subsequently, we employ conditional diffusion models to generate plausible full-body motions based on these temporally dense trajectories of the head and hands, guided by the uncertainty estimates from the imputation. The effectiveness of our method was rigorously tested and validated through comprehensive experiments conducted on various HMD setup with AMASS and Ego-Exo4D datasets.