 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCATSplat: Context-Aware Transformer with Spatial Guidance for Generalizable 3D Gaussian Splatting from A Single-View Image
Dec 17, 2024



Recently, generalizable feed-forward methods based on 3D Gaussian Splatting have gained significant attention for their potential to reconstruct 3D scenes using finite resources. These approaches create a 3D radiance field, parameterized by per-pixel 3D Gaussian primitives, from just a few images in a single forward pass. However, unlike multi-view methods that benefit from cross-view correspondences, 3D scene reconstruction with a single-view image remains an underexplored area. In this work, we introduce CATSplat, a novel generalizable transformer-based framework designed to break through the inherent constraints in monocular settings. First, we propose leveraging textual guidance from a visual-language model to complement insufficient information from a single image. By incorporating scene-specific contextual details from text embeddings through cross-attention, we pave the way for context-aware 3D scene reconstruction beyond relying solely on visual cues. Moreover, we advocate utilizing spatial guidance from 3D point features toward comprehensive geometric understanding under single-view settings. With 3D priors, image features can capture rich structural insights for predicting 3D Gaussians without multi-view techniques. Extensive experiments on large-scale datasets demonstrate the state-of-the-art performance of CATSplat in single-view 3D scene reconstruction with high-quality novel view synthesis.
Estimating Ego-Body Pose from Doubly Sparse Egocentric Video Data
Nov 05, 2024



We study the problem of estimating the body movements of a camera wearer from egocentric videos. Current methods for ego-body pose estimation rely on temporally dense sensor data, such as IMU measurements from spatially sparse body parts like the head and hands. However, we propose that even temporally sparse observations, such as hand poses captured intermittently from egocentric videos during natural or periodic hand movements, can effectively constrain overall body motion. Naively applying diffusion models to generate full-body pose from head pose and sparse hand pose leads to suboptimal results. To overcome this, we develop a two-stage approach that decomposes the problem into temporal completion and spatial completion. First, our method employs masked autoencoders to impute hand trajectories by leveraging the spatiotemporal correlations between the head pose sequence and intermittent hand poses, providing uncertainty estimates. Subsequently, we employ conditional diffusion models to generate plausible full-body motions based on these temporally dense trajectories of the head and hands, guided by the uncertainty estimates from the imputation. The effectiveness of our method was rigorously tested and validated through comprehensive experiments conducted on various HMD setup with AMASS and Ego-Exo4D datasets.
M2D2M: Multi-Motion Generation from Text with Discrete Diffusion Models
Jul 19, 2024



We introduce the Multi-Motion Discrete Diffusion Models (M2D2M), a novel approach for human motion generation from textual descriptions of multiple actions, utilizing the strengths of discrete diffusion models. This approach adeptly addresses the challenge of generating multi-motion sequences, ensuring seamless transitions of motions and coherence across a series of actions. The strength of M2D2M lies in its dynamic transition probability within the discrete diffusion model, which adapts transition probabilities based on the proximity between motion tokens, encouraging mixing between different modes. Complemented by a two-phase sampling strategy that includes independent and joint denoising steps, M2D2M effectively generates long-term, smooth, and contextually coherent human motion sequences, utilizing a model trained for single-motion generation. Extensive experiments demonstrate that M2D2M surpasses current state-of-the-art benchmarks for motion generation from text descriptions, showcasing its efficacy in interpreting language semantics and generating dynamic, realistic motions.
InfoGCN++: Learning Representation by Predicting the Future for Online Human Skeleton-based Action Recognition
Oct 16, 2023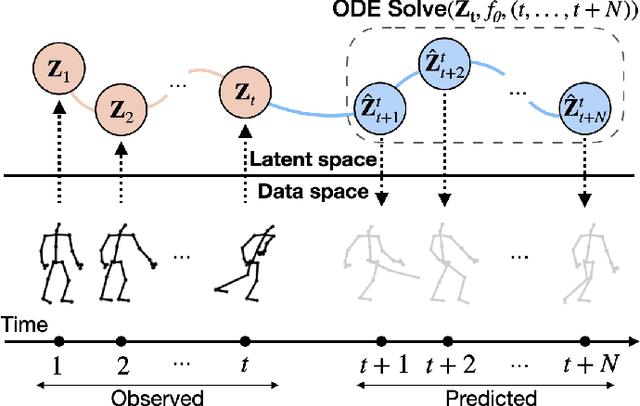
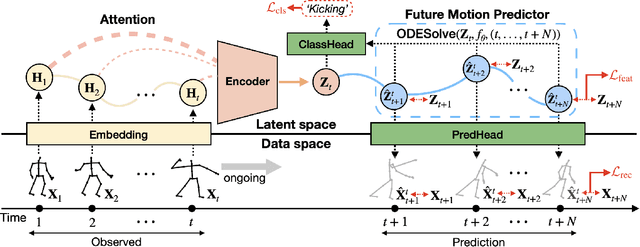
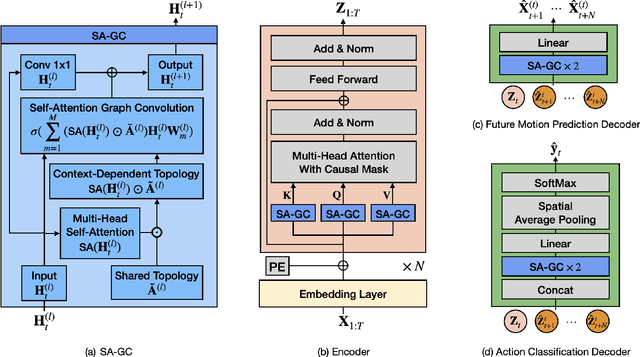
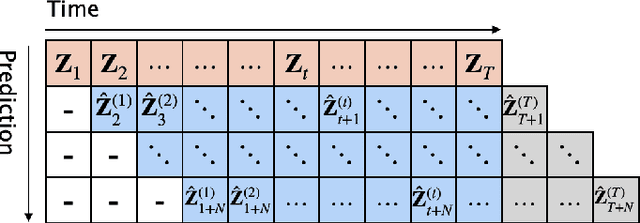
Skeleton-based action recognition has made significant advancements recently, with models like InfoGCN showcasing remarkable accuracy. However, these models exhibit a key limitation: they necessitate complete action observation prior to classification, which constrains their applicability in real-time situations such as surveillance and robotic systems. To overcome this barrier, we introduce InfoGCN++, an innovative extension of InfoGCN, explicitly developed for online skeleton-based action recognition. InfoGCN++ augments the abilities of the original InfoGCN model by allowing real-time categorization of action types, independent of the observation sequence's length. It transcends conventional approaches by learning from current and anticipated future movements, thereby creating a more thorough representation of the entire sequence. Our approach to prediction is managed as an extrapolation issue, grounded on observed actions. To enable this, InfoGCN++ incorporates Neural Ordinary Differential Equations, a concept that lets it effectively model the continuous evolution of hidden states. Following rigorous evaluations on three skeleton-based action recognition benchmarks, InfoGCN++ demonstrates exceptional performance in online action recognition. It consistently equals or exceeds existing techniques, highlighting its significant potential to reshape the landscape of real-time action recognition applications. Consequently, this work represents a major leap forward from InfoGCN, pushing the limits of what's possible in online, skeleton-based action recognition. The code for InfoGCN++ is publicly available at https://github.com/stnoah1/infogcn2 for further exploration and validation.