 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyGE-Occ: Hybrid View-Transformation with 3D Gaussian and Edge Priors for 3D Panoptic Occupancy Prediction
Dec 22, 20253D Panoptic Occupancy Prediction aims to reconstruct a dense volumetric scene map by predicting the semantic class and instance identity of every occupied region in 3D space. Achieving such fine-grained 3D understanding requires precise geometric reasoning and spatially consistent scene representation across complex environments. However, existing approaches often struggle to maintain precise geometry and capture the precise spatial range of 3D instances critical for robust panoptic separation. To overcome these limitations, we introduce HyGE-Occ, a novel framework that leverages a hybrid view-transformation branch with 3D Gaussian and edge priors to enhance both geometric consistency and boundary awareness in 3D panoptic occupancy prediction. HyGE-Occ employs a hybrid view-transformation branch that fuses a continuous Gaussian-based depth representation with a discretized depth-bin formulation, producing BEV features with improved geometric consistency and structural coherence. In parallel, we extract edge maps from BEV features and use them as auxiliary information to learn edge cues. In our extensive experiments on the Occ3D-nuScenes dataset, HyGE-Occ outperforms existing work, demonstrating superior 3D geometric reasoning.
CATSplat: Context-Aware Transformer with Spatial Guidance for Generalizable 3D Gaussian Splatting from A Single-View Image
Dec 17, 2024



Recently, generalizable feed-forward methods based on 3D Gaussian Splatting have gained significant attention for their potential to reconstruct 3D scenes using finite resources. These approaches create a 3D radiance field, parameterized by per-pixel 3D Gaussian primitives, from just a few images in a single forward pass. However, unlike multi-view methods that benefit from cross-view correspondences, 3D scene reconstruction with a single-view image remains an underexplored area. In this work, we introduce CATSplat, a novel generalizable transformer-based framework designed to break through the inherent constraints in monocular settings. First, we propose leveraging textual guidance from a visual-language model to complement insufficient information from a single image. By incorporating scene-specific contextual details from text embeddings through cross-attention, we pave the way for context-aware 3D scene reconstruction beyond relying solely on visual cues. Moreover, we advocate utilizing spatial guidance from 3D point features toward comprehensive geometric understanding under single-view settings. With 3D priors, image features can capture rich structural insights for predicting 3D Gaussians without multi-view techniques. Extensive experiments on large-scale datasets demonstrate the state-of-the-art performance of CATSplat in single-view 3D scene reconstruction with high-quality novel view synthesis.
CMDA: Cross-Modal and Domain Adversarial Adaptation for LiDAR-Based 3D Object Detection
Mar 07, 2024Recent LiDAR-based 3D Object Detection (3DOD) methods show promising results, but they often do not generalize well to target domains outside the source (or training) data distribution. To reduce such domain gaps and thus to make 3DOD models more generalizable, we introduce a novel unsupervised domain adaptation (UDA) method, called CMDA, which (i) leverages visual semantic cues from an image modality (i.e., camera images) as an effective semantic bridge to close the domain gap in the cross-modal Bird's Eye View (BEV) representations. Further, (ii) we also introduce a self-training-based learning strategy, wherein a model is adversarially trained to generate domain-invariant features, which disrupt the discrimination of whether a feature instance comes from a source or an unseen target domain. Overall, our CMDA framework guides the 3DOD model to generate highly informative and domain-adaptive features for novel data distributions. In our extensive experiments with large-scale benchmarks, such as nuScenes, Waymo, and KITTI, those mentioned above provide significant performance gains for UDA tasks, achieving state-of-the-art performance.
ORA3D: Overlap Region Aware Multi-view 3D Object Detection
Jul 02, 2022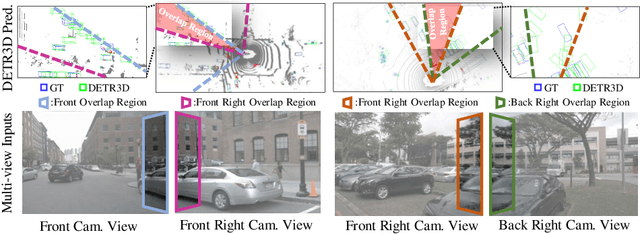
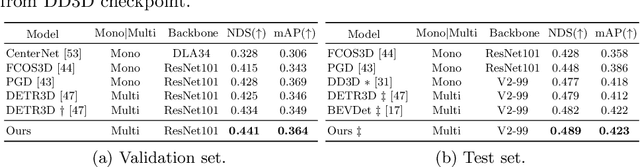
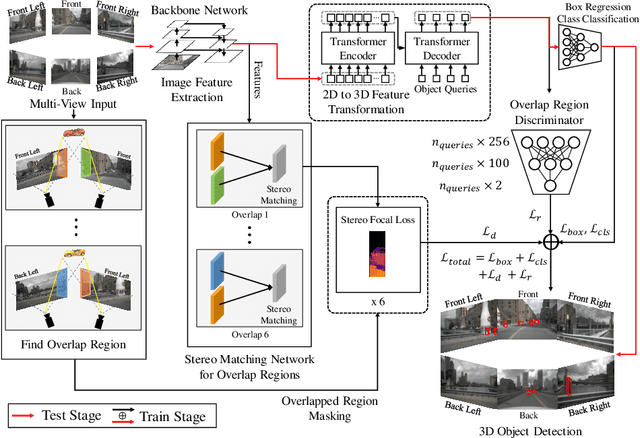

In multi-view 3D object detection tasks, disparity supervision over overlapping image regions substantially improves the overall detection performance. However, current multi-view 3D object detection methods often fail to detect objects in the overlap region properly, and the network's understanding of the scene is often limited to that of a monocular detection network. To mitigate this issue, we advocate for applying the traditional stereo disparity estimation method to obtain reliable disparity information for the overlap region. Given the disparity estimates as a supervision, we propose to regularize the network to fully utilize the geometric potential of binocular images, and improve the overall detection accuracy. Moreover, we propose to use an adversarial overlap region discriminator, which is trained to minimize the representational gap between non-overlap regions and overlapping regions where objects are often largely occluded or suffer from deformation due to camera distortion, causing a domain shift. We demonstrate the effectiveness of the proposed method with the large-scale multi-view 3D object detection benchmark, called nuScenes. Our experiment shows that our proposed method outperforms the current state-of-the-art methods.
Sound-Guided Semantic Image Manipulation
Nov 30, 2021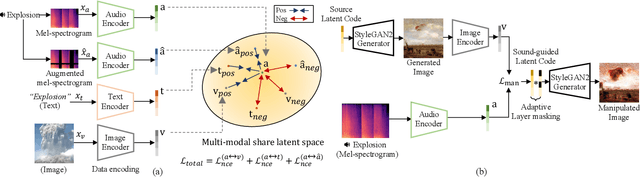
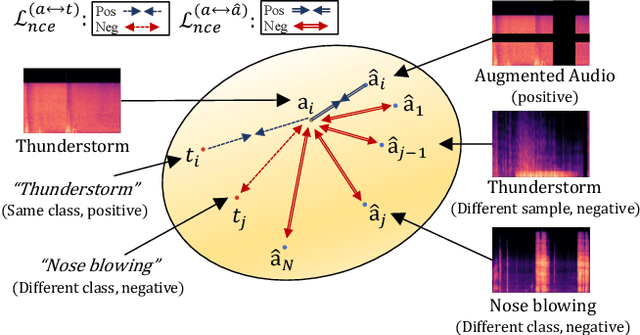


The recent success of the generative model shows that leveraging the multi-modal embedding space can manipulate an image using text information. However, manipulating an image with other sources rather than text, such as sound, is not easy due to the dynamic characteristics of the sources. Especially, sound can convey vivid emotions and dynamic expressions of the real world. Here, we propose a framework that directly encodes sound into the multi-modal (image-text) embedding space and manipulates an image from the space. Our audio encoder is trained to produce a latent representation from an audio input, which is forced to be aligned with image and text representations in the multi-modal embedding space. We use a direct latent optimization method based on aligned embeddings for sound-guided image manipulation. We also show that our method can mix text and audio modalities, which enrich the variety of the image modification. We verify the effectiveness of our sound-guided image manipulation quantitatively and qualitatively. We also show that our method can mix different modalities, i.e., text and audio, which enrich the variety of the image modification. The experiments on zero-shot audio classification and semantic-level image classification show that our proposed model outperforms other text and sound-guided state-of-the-art methods.