 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSHED Light on Segmentation for Dense Prediction
Jan 30, 2026Dense prediction infers per-pixel values from a single image and is fundamental to 3D perception and robotics. Although real-world scenes exhibit strong structure, existing methods treat it as an independent pixel-wise prediction, often resulting in structural inconsistencies. We propose SHED, a novel encoder-decoder architecture that enforces geometric prior explicitly by incorporating segmentation into dense prediction. By bidirectional hierarchical reasoning, segment tokens are hierarchically pooled in the encoder and unpooled in the decoder to reverse the hierarchy. The model is supervised only at the final output, allowing the segment hierarchy to emerge without explicit segmentation supervision. SHED improves depth boundary sharpness and segment coherence, while demonstrating strong cross-domain generalization from synthetic to the real-world environments. Its hierarchy-aware decoder better captures global 3D scene layouts, leading to improved semantic segmentation performance. Moreover, SHED enhances 3D reconstruction quality and reveals interpretable part-level structures that are often missed by conventional pixel-wise methods.
Cropper: Vision-Language Model for Image Cropping through In-Context Learning
Aug 14, 2024



The goal of image cropping is to identify visually appealing crops within an image. Conventional methods rely on specialized architectures trained on specific datasets, which struggle to be adapted to new requirements. Recent breakthroughs in large vision-language models (VLMs) have enabled visual in-context learning without explicit training. However, effective strategies for vision downstream tasks with VLMs remain largely unclear and underexplored. In this paper, we propose an effective approach to leverage VLMs for better image cropping. First, we propose an efficient prompt retrieval mechanism for image cropping to automate the selection of in-context examples. Second, we introduce an iterative refinement strategy to iteratively enhance the predicted crops. The proposed framework, named Cropper, is applicable to a wide range of cropping tasks, including free-form cropping, subject-aware cropping, and aspect ratio-aware cropping. Extensive experiments and a user study demonstrate that Cropper significantly outperforms state-of-the-art methods across several benchmarks.
Parrot: Pareto-optimal Multi-Reward Reinforcement Learning Framework for Text-to-Image Generation
Jan 11, 2024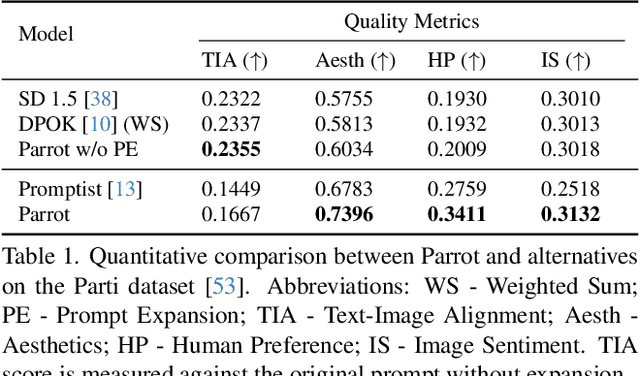
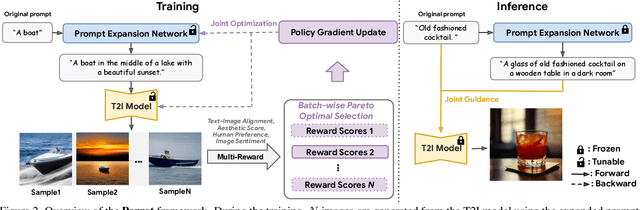


Recent works demonstrate that using reinforcement learning (RL) with quality rewards can enhance the quality of generated images in text-to-image (T2I) generation. However, a simple aggregation of multiple rewards may cause over-optimization in certain metrics and degradation in others, and it is challenging to manually find the optimal weights. An effective strategy to jointly optimize multiple rewards in RL for T2I generation is highly desirable. This paper introduces Parrot, a novel multi-reward RL framework for T2I generation. Through the use of the batch-wise Pareto optimal selection, Parrot automatically identifies the optimal trade-off among different rewards during the RL optimization of the T2I generation. Additionally, Parrot employs a joint optimization approach for the T2I model and the prompt expansion network, facilitating the generation of quality-aware text prompts, thus further enhancing the final image quality. To counteract the potential catastrophic forgetting of the original user prompt due to prompt expansion, we introduce original prompt centered guidance at inference time, ensuring that the generated image remains faithful to the user input. Extensive experiments and a user study demonstrate that Parrot outperforms several baseline methods across various quality criteria, including aesthetics, human preference, image sentiment, and text-image alignment.
SAR-RARP50: Segmentation of surgical instrumentation and Action Recognition on Robot-Assisted Radical Prostatectomy Challenge
Dec 31, 2023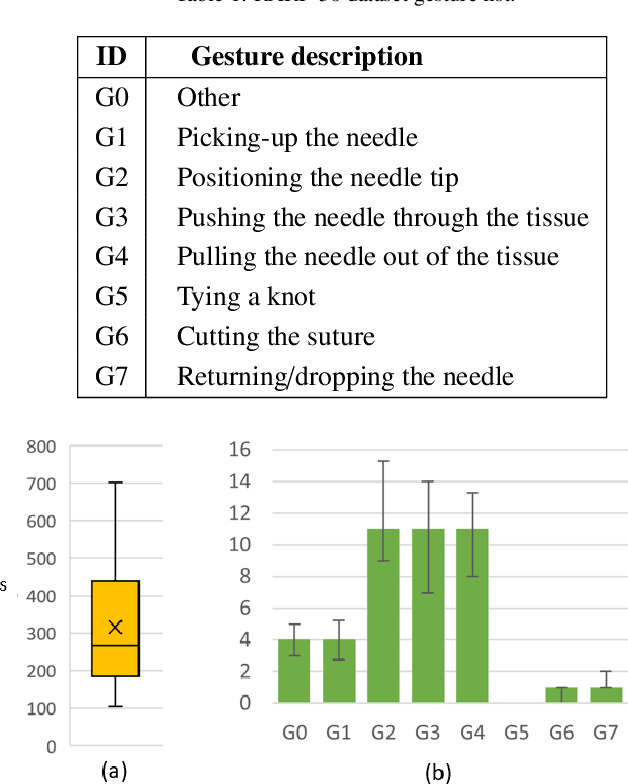
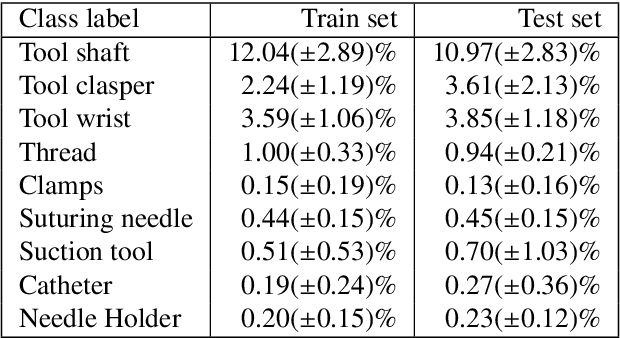
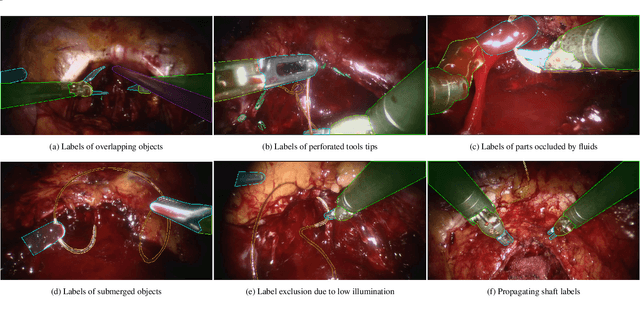
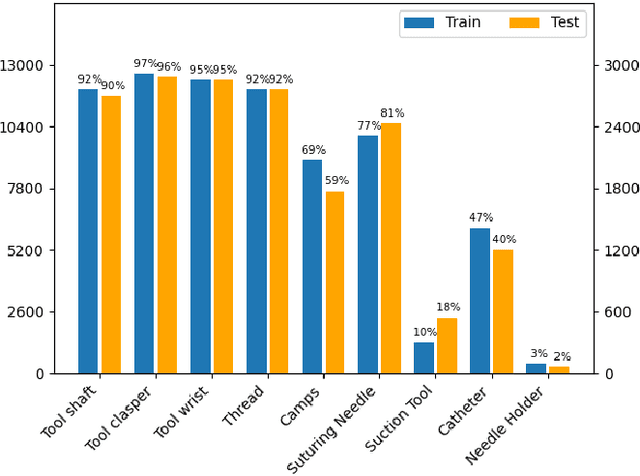
Surgical tool segmentation and action recognition are fundamental building blocks in many computer-assisted intervention applications, ranging from surgical skills assessment to decision support systems. Nowadays, learning-based action recognition and segmentation approaches outperform classical methods, relying, however, on large, annotated datasets. Furthermore, action recognition and tool segmentation algorithms are often trained and make predictions in isolation from each other, without exploiting potential cross-task relationships. With the EndoVis 2022 SAR-RARP50 challenge, we release the first multimodal, publicly available, in-vivo, dataset for surgical action recognition and semantic instrumentation segmentation, containing 50 suturing video segments of Robotic Assisted Radical Prostatectomy (RARP). The aim of the challenge is twofold. First, to enable researchers to leverage the scale of the provided dataset and develop robust and highly accurate single-task action recognition and tool segmentation approaches in the surgical domain. Second, to further explore the potential of multitask-based learning approaches and determine their comparative advantage against their single-task counterparts. A total of 12 teams participated in the challenge, contributing 7 action recognition methods, 9 instrument segmentation techniques, and 4 multitask approaches that integrated both action recognition and instrument segmentation.
Soundini: Sound-Guided Diffusion for Natural Video Editing
Apr 13, 2023



We propose a method for adding sound-guided visual effects to specific regions of videos with a zero-shot setting. Animating the appearance of the visual effect is challenging because each frame of the edited video should have visual changes while maintaining temporal consistency. Moreover, existing video editing solutions focus on temporal consistency across frames, ignoring the visual style variations over time, e.g., thunderstorm, wave, fire crackling. To overcome this limitation, we utilize temporal sound features for the dynamic style. Specifically, we guide denoising diffusion probabilistic models with an audio latent representation in the audio-visual latent space. To the best of our knowledge, our work is the first to explore sound-guided natural video editing from various sound sources with sound-specialized properties, such as intensity, timbre, and volume. Additionally, we design optical flow-based guidance to generate temporally consistent video frames, capturing the pixel-wise relationship between adjacent frames. Experimental results show that our method outperforms existing video editing techniques, producing more realistic visual effects that reflect the properties of sound. Please visit our page: https://kuai-lab.github.io/soundini-gallery/.
LISA: Localized Image Stylization with Audio via Implicit Neural Representation
Nov 21, 2022
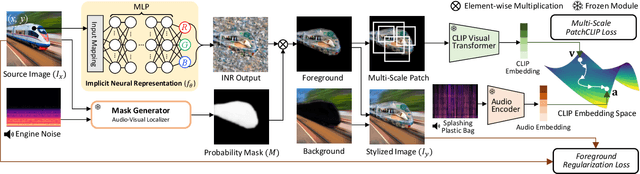
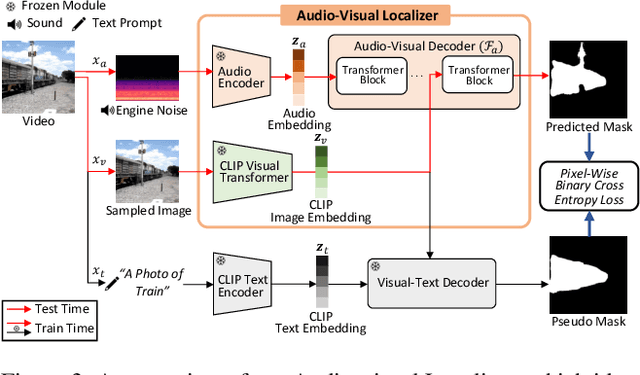
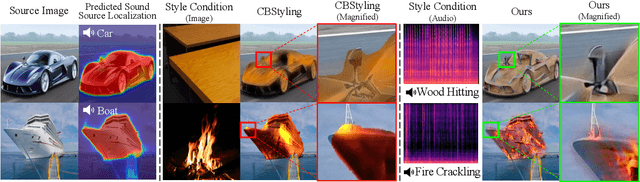
We present a novel framework, Localized Image Stylization with Audio (LISA) which performs audio-driven localized image stylization. Sound often provides information about the specific context of the scene and is closely related to a certain part of the scene or object. However, existing image stylization works have focused on stylizing the entire image using an image or text input. Stylizing a particular part of the image based on audio input is natural but challenging. In this work, we propose a framework that a user provides an audio input to localize the sound source in the input image and another for locally stylizing the target object or scene. LISA first produces a delicate localization map with an audio-visual localization network by leveraging CLIP embedding space. We then utilize implicit neural representation (INR) along with the predicted localization map to stylize the target object or scene based on sound information. The proposed INR can manipulate the localized pixel values to be semantically consistent with the provided audio input. Through a series of experiments, we show that the proposed framework outperforms the other audio-guided stylization methods. Moreover, LISA constructs concise localization maps and naturally manipulates the target object or scene in accordance with the given audio input.
Robust Sound-Guided Image Manipulation
Aug 31, 2022
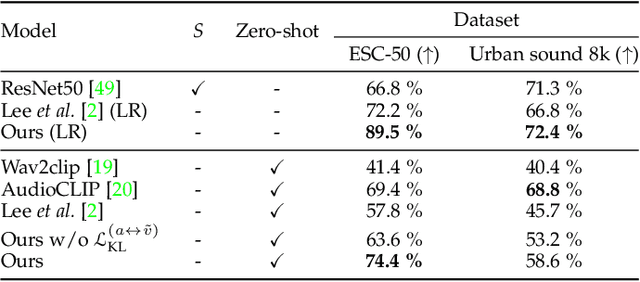


Recent successes suggest that an image can be manipulated by a text prompt, e.g., a landscape scene on a sunny day is manipulated into the same scene on a rainy day driven by a text input "raining". These approaches often utilize a StyleCLIP-based image generator, which leverages multi-modal (text and image) embedding space. However, we observe that such text inputs are often bottlenecked in providing and synthesizing rich semantic cues, e.g., differentiating heavy rain from rain with thunderstorms. To address this issue, we advocate leveraging an additional modality, sound, which has notable advantages in image manipulation as it can convey more diverse semantic cues (vivid emotions or dynamic expressions of the natural world) than texts. In this paper, we propose a novel approach that first extends the image-text joint embedding space with sound and applies a direct latent optimization method to manipulate a given image based on audio input, e.g., the sound of rain. Our extensive experiments show that our sound-guided image manipulation approach produces semantically and visually more plausible manipulation results than the state-of-the-art text and sound-guided image manipulation methods, which are further confirmed by our human evaluations. Our downstream task evaluations also show that our learned image-text-sound joint embedding space effectively encodes sound inputs.
Sound-Guided Semantic Video Generation
Apr 21, 2022
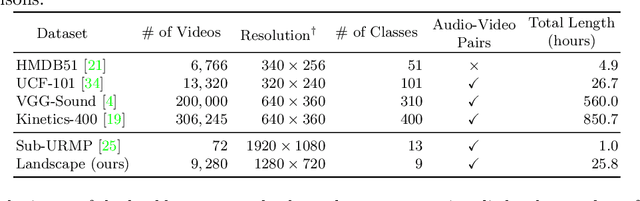
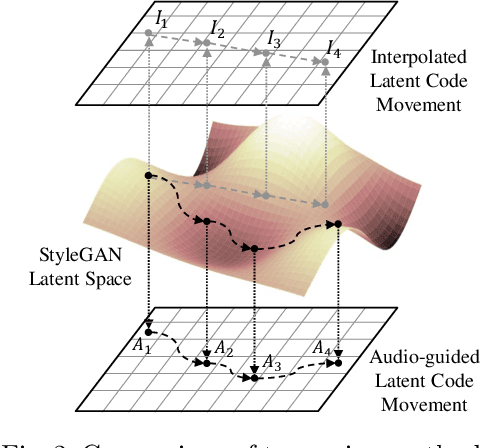

The recent success in StyleGAN demonstrates that pre-trained StyleGAN latent space is useful for realistic video generation. However, the generated motion in the video is usually not semantically meaningful due to the difficulty of determining the direction and magnitude in the StyleGAN latent space. In this paper, we propose a framework to generate realistic videos by leveraging multimodal (sound-image-text) embedding space. As sound provides the temporal contexts of the scene, our framework learns to generate a video that is semantically consistent with sound. First, our sound inversion module maps the audio directly into the StyleGAN latent space. We then incorporate the CLIP-based multimodal embedding space to further provide the audio-visual relationships. Finally, the proposed frame generator learns to find the trajectory in the latent space which is coherent with the corresponding sound and generates a video in a hierarchical manner. We provide the new high-resolution landscape video dataset (audio-visual pair) for the sound-guided video generation task. The experiments show that our model outperforms the state-of-the-art methods in terms of video quality. We further show several applications including image and video editing to verify the effectiveness of our method.
Sound-Guided Semantic Image Manipulation
Nov 30, 2021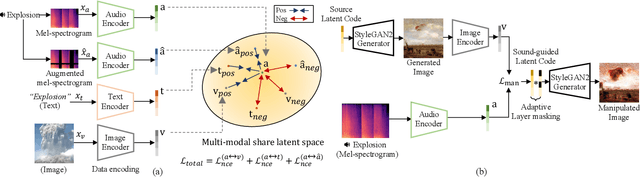
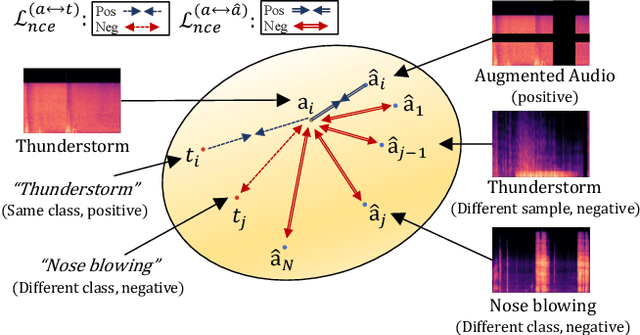


The recent success of the generative model shows that leveraging the multi-modal embedding space can manipulate an image using text information. However, manipulating an image with other sources rather than text, such as sound, is not easy due to the dynamic characteristics of the sources. Especially, sound can convey vivid emotions and dynamic expressions of the real world. Here, we propose a framework that directly encodes sound into the multi-modal (image-text) embedding space and manipulates an image from the space. Our audio encoder is trained to produce a latent representation from an audio input, which is forced to be aligned with image and text representations in the multi-modal embedding space. We use a direct latent optimization method based on aligned embeddings for sound-guided image manipulation. We also show that our method can mix text and audio modalities, which enrich the variety of the image modification. We verify the effectiveness of our sound-guided image manipulation quantitatively and qualitatively. We also show that our method can mix different modalities, i.e., text and audio, which enrich the variety of the image modification. The experiments on zero-shot audio classification and semantic-level image classification show that our proposed model outperforms other text and sound-guided state-of-the-art methods.
Metric-based Regularization and Temporal Ensemble for Multi-task Learning using Heterogeneous Unsupervised Tasks
Aug 29, 2019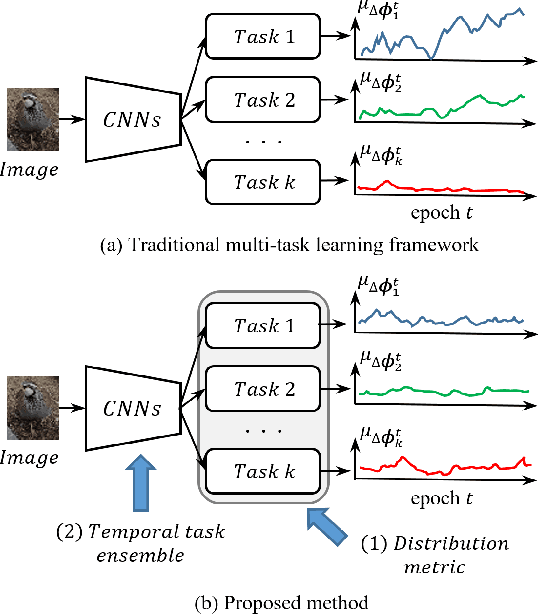

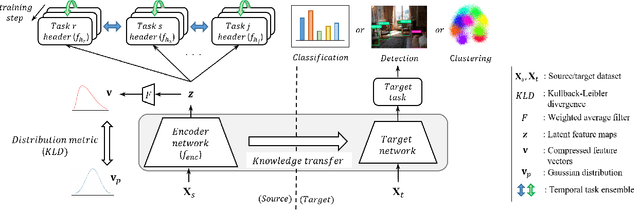
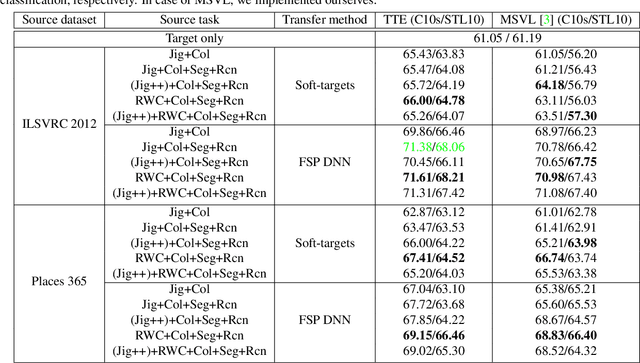
One of the ways to improve the performance of a target task is to learn the transfer of abundant knowledge of a pre-trained network. However, learning of the pre-trained network requires high computation capability and large-scale labeled dataset. To mitigate the burden of large-scale labeling, learning in un/self-supervised manner can be a solution. In addition, using unsupervised multi-task learning, a generalized feature representation can be learned. However, unsupervised multi-task learning can be biased to a specific task. To overcome this problem, we propose the metric-based regularization term and temporal task ensemble (TTE) for multi-task learning. Since these two techniques prevent the entire network from learning in a state deviated to a specific task, it is possible to learn a generalized feature representation that appropriately reflects the characteristics of each task without biasing. Experimental results for three target tasks such as classification, object detection and embedding clustering prove that the TTE-based multi-task framework is more effective than the state-of-the-art (SOTA) method in improving the performance of a target task.