 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward User Preference Alignment in LLM Recommendation via Explicit Context Feedback
May 27, 2026Traditional recommender systems (RecSys) primarily infer user preferences from implicit signals (such as clicks, watches, and purchases), often neglecting the rich explicit contextual feedback users provide through verbal text, like comments and reviews. This explicit context feedback captures the nuanced reasons behind user decisions regarding their preferences. In addition, it offers critical heterogeneous information for user preference alignment and more explainable recommendations. Overlooking such signals can lead to misaligned user preferences and further reinforce filter bubbles, as algorithms fail to understand the "semantic context" behind user choices. Recent advances in Large Language Models (LLMs) present new opportunities to harness user-generated content for more accurate and diverse recommendations, yet current LLM-based recommendations still focus on using item meta-data and underutilize this resource. In this paper, we advocate for prioritizing explicit context feedback in the next generation of LLM-based RecSys. We review the evolution of recommendation paradigms, highlight the value of context-rich feedback, call for new benchmarks and metrics, and introduce frameworks for integrating explicit user signals into scalable LLM-driven RecSys. Centering on user-preference modeling, we aim to foster more personalized, transparent, and explainable RecSys online platforms.
LLM-Driven Reasoning for Constraint-Aware Feature Selection in Industrial Systems
Mar 26, 2026Feature selection is a crucial step in large-scale industrial machine learning systems, directly affecting model accuracy, efficiency, and maintainability. Traditional feature selection methods rely on labeled data and statistical heuristics, making them difficult to apply in production environments where labeled data are limited and multiple operational constraints must be satisfied. To address this, we propose Model Feature Agent (MoFA), a model-driven framework that performs sequential, reasoning-based feature selection using both semantic and quantitative feature information. MoFA incorporates feature definitions, importance scores, correlations, and metadata (e.g., feature groups or types) into structured prompts and selects features through interpretable, constraint-aware reasoning. We evaluate MoFA in three real-world industrial applications: (1) True Interest and Time-Worthiness Prediction, where it improves accuracy while reducing feature group complexity, (2) Value Model Enhancement, where it discovers high-order interaction terms that yield substantial engagement gains in online experiments, and (3) Notification Behavior Prediction, where it selects compact, high-value feature subsets that improve both model accuracy and inference efficiency. Together, these results demonstrate the practicality and effectiveness of LLM-based reasoning for feature selection in real production systems.
Principled Synthetic Data Enables the First Scaling Laws for LLMs in Recommendation
Feb 07, 2026Large Language Models (LLMs) represent a promising frontier for recommender systems, yet their development has been impeded by the absence of predictable scaling laws, which are crucial for guiding research and optimizing resource allocation. We hypothesize that this may be attributed to the inherent noise, bias, and incompleteness of raw user interaction data in prior continual pre-training (CPT) efforts. This paper introduces a novel, layered framework for generating high-quality synthetic data that circumvents such issues by creating a curated, pedagogical curriculum for the LLM. We provide powerful, direct evidence for the utility of our curriculum by showing that standard sequential models trained on our principled synthetic data significantly outperform ($+130\%$ on recall@100 for SasRec) models trained on real data in downstream ranking tasks, demonstrating its superiority for learning generalizable user preference patterns. Building on this, we empirically demonstrate, for the first time, robust power-law scaling for an LLM that is continually pre-trained on our high-quality, recommendation-specific data. Our experiments reveal consistent and predictable perplexity reduction across multiple synthetic data modalities. These findings establish a foundational methodology for reliable scaling LLM capabilities in the recommendation domain, thereby shifting the research focus from mitigating data deficiencies to leveraging high-quality, structured information.
Calibrated Multi-Preference Optimization for Aligning Diffusion Models
Feb 04, 2025



Aligning text-to-image (T2I) diffusion models with preference optimization is valuable for human-annotated datasets, but the heavy cost of manual data collection limits scalability. Using reward models offers an alternative, however, current preference optimization methods fall short in exploiting the rich information, as they only consider pairwise preference distribution. Furthermore, they lack generalization to multi-preference scenarios and struggle to handle inconsistencies between rewards. To address this, we present Calibrated Preference Optimization (CaPO), a novel method to align T2I diffusion models by incorporating the general preference from multiple reward models without human annotated data. The core of our approach involves a reward calibration method to approximate the general preference by computing the expected win-rate against the samples generated by the pretrained models. Additionally, we propose a frontier-based pair selection method that effectively manages the multi-preference distribution by selecting pairs from Pareto frontiers. Finally, we use regression loss to fine-tune diffusion models to match the difference between calibrated rewards of a selected pair. Experimental results show that CaPO consistently outperforms prior methods, such as Direct Preference Optimization (DPO), in both single and multi-reward settings validated by evaluation on T2I benchmarks, including GenEval and T2I-Compbench.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Optical Diffusion Models for Image Generation
Jul 15, 2024



Diffusion models generate new samples by progressively decreasing the noise from the initially provided random distribution. This inference procedure generally utilizes a trained neural network numerous times to obtain the final output, creating significant latency and energy consumption on digital electronic hardware such as GPUs. In this study, we demonstrate that the propagation of a light beam through a semi-transparent medium can be programmed to implement a denoising diffusion model on image samples. This framework projects noisy image patterns through passive diffractive optical layers, which collectively only transmit the predicted noise term in the image. The optical transparent layers, which are trained with an online training approach, backpropagating the error to the analytical model of the system, are passive and kept the same across different steps of denoising. Hence this method enables high-speed image generation with minimal power consumption, benefiting from the bandwidth and energy efficiency of optical information processing.
PRDP: Proximal Reward Difference Prediction for Large-Scale Reward Finetuning of Diffusion Models
Feb 13, 2024



Reward finetuning has emerged as a promising approach to aligning foundation models with downstream objectives. Remarkable success has been achieved in the language domain by using reinforcement learning (RL) to maximize rewards that reflect human preference. However, in the vision domain, existing RL-based reward finetuning methods are limited by their instability in large-scale training, rendering them incapable of generalizing to complex, unseen prompts. In this paper, we propose Proximal Reward Difference Prediction (PRDP), enabling stable black-box reward finetuning for diffusion models for the first time on large-scale prompt datasets with over 100K prompts. Our key innovation is the Reward Difference Prediction (RDP) objective that has the same optimal solution as the RL objective while enjoying better training stability. Specifically, the RDP objective is a supervised regression objective that tasks the diffusion model with predicting the reward difference of generated image pairs from their denoising trajectories. We theoretically prove that the diffusion model that obtains perfect reward difference prediction is exactly the maximizer of the RL objective. We further develop an online algorithm with proximal updates to stably optimize the RDP objective. In experiments, we demonstrate that PRDP can match the reward maximization ability of well-established RL-based methods in small-scale training. Furthermore, through large-scale training on text prompts from the Human Preference Dataset v2 and the Pick-a-Pic v1 dataset, PRDP achieves superior generation quality on a diverse set of complex, unseen prompts whereas RL-based methods completely fail.
Parrot: Pareto-optimal Multi-Reward Reinforcement Learning Framework for Text-to-Image Generation
Jan 11, 2024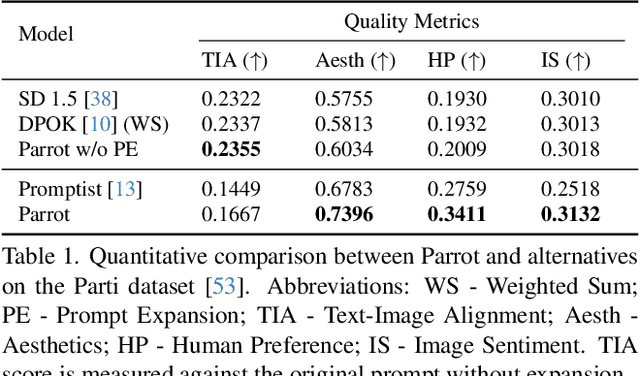
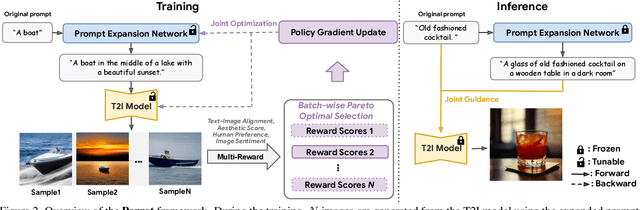


Recent works demonstrate that using reinforcement learning (RL) with quality rewards can enhance the quality of generated images in text-to-image (T2I) generation. However, a simple aggregation of multiple rewards may cause over-optimization in certain metrics and degradation in others, and it is challenging to manually find the optimal weights. An effective strategy to jointly optimize multiple rewards in RL for T2I generation is highly desirable. This paper introduces Parrot, a novel multi-reward RL framework for T2I generation. Through the use of the batch-wise Pareto optimal selection, Parrot automatically identifies the optimal trade-off among different rewards during the RL optimization of the T2I generation. Additionally, Parrot employs a joint optimization approach for the T2I model and the prompt expansion network, facilitating the generation of quality-aware text prompts, thus further enhancing the final image quality. To counteract the potential catastrophic forgetting of the original user prompt due to prompt expansion, we introduce original prompt centered guidance at inference time, ensuring that the generated image remains faithful to the user input. Extensive experiments and a user study demonstrate that Parrot outperforms several baseline methods across various quality criteria, including aesthetics, human preference, image sentiment, and text-image alignment.
On-device Real-time Custom Hand Gesture Recognition
Sep 19, 2023



Most existing hand gesture recognition (HGR) systems are limited to a predefined set of gestures. However, users and developers often want to recognize new, unseen gestures. This is challenging due to the vast diversity of all plausible hand shapes, e.g. it is impossible for developers to include all hand gestures in a predefined list. In this paper, we present a user-friendly framework that lets users easily customize and deploy their own gesture recognition pipeline. Our framework provides a pre-trained single-hand embedding model that can be fine-tuned for custom gesture recognition. Users can perform gestures in front of a webcam to collect a small amount of images per gesture. We also offer a low-code solution to train and deploy the custom gesture recognition model. This makes it easy for users with limited ML expertise to use our framework. We further provide a no-code web front-end for users without any ML expertise. This makes it even easier to build and test the end-to-end pipeline. The resulting custom HGR is then ready to be run on-device for real-time scenarios. This can be done by calling a simple function in our open-sourced model inference API, MediaPipe Tasks. This entire process only takes a few minutes.
Forward-Forward Training of an Optical Neural Network
May 30, 2023



Neural networks (NN) have demonstrated remarkable capabilities in various tasks, but their computation-intensive nature demands faster and more energy-efficient hardware implementations. Optics-based platforms, using technologies such as silicon photonics and spatial light modulators, offer promising avenues for achieving this goal. However, training multiple trainable layers in tandem with these physical systems poses challenges, as they are difficult to fully characterize and describe with differentiable functions, hindering the use of error backpropagation algorithm. The recently introduced Forward-Forward Algorithm (FFA) eliminates the need for perfect characterization of the learning system and shows promise for efficient training with large numbers of programmable parameters. The FFA does not require backpropagating an error signal to update the weights, rather the weights are updated by only sending information in one direction. The local loss function for each set of trainable weights enables low-power analog hardware implementations without resorting to metaheuristic algorithms or reinforcement learning. In this paper, we present an experiment utilizing multimode nonlinear wave propagation in an optical fiber demonstrating the feasibility of the FFA approach using an optical system. The results show that incorporating optical transforms in multilayer NN architectures trained with the FFA, can lead to performance improvements, even with a relatively small number of trainable weights. The proposed method offers a new path to the challenge of training optical NNs and provides insights into leveraging physical transformations for enhancing NN performance.