 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJSCGC: Joint Source-Channel-Generation Coding for Wireless Generative Communications
Jun 11, 2026Conventional communication systems, including both separation-based coding and learning-based joint source-channel coding (JSCC), are typically designed under Shannon's rate-distortion theory. However, relying on generic distortion metrics fails to capture complex human visual perception, often resulting in blurred or unrealistic reconstructions. In this paper, we propose Joint Source-Channel-Generation Coding (JSCGC), a generative communication paradigm that replaces the conventional decoder with a generative model at the receiver. The received signal is treated as a condition that controls the sampling process into the learned conditional distribution, reformulating communication from deterministic reconstruction for distortion minimization to controlled generation for mutual information maximization under perceptual constraints. Based on this formulation, we develop a unified joint training and efficient stochastic sampling framework, and provide theoretical analysis of its effectiveness in both learning and inference stages. Extensive experiments on latent-space image transmission demonstrate that the JSCGC consistently improves feature-based, semantic-level, and distributional quality across diverse channel conditions, while exhibiting a distinct error behavior characterized by semantic inconsistency rather than distortion.
Domain-Adaptive Communication-Rate Optimization for Sim-to-Real Humanoid-Robot Wireless XR Teleoperation
May 19, 2026Wireless extended reality (XR) teleoperation provides embodied interaction capability for collecting humanoid robot demonstrations, but the large-scale adoption is restricted by the overhead of high-frequency motion transmission. This paper develops a system framework that integrates sampling, transmission, interpolation, and reconstruction and formulates a communication-rate optimization that aims to minimize the communication energy while maintaining the reconstruction accuracy of robot motion trajectories through dimension-wise sampling-rate control. Since acquiring real-time feedback from physical robots is limited by hardware costs, it is necessary to solve the problem through simulator interaction with offline real-domain data correction. To guide sim-to-real adaptation, we provide a PAC-Bayes generalization characterization that reveals the effects of latent density-ratio estimation, finite-sample deviation, and encoder bias. Building on this analysis, we propose a proximal policy optimization (PPO) method with density-ratio weighting and trust-region regularization. Experiments on public humanoid teleoperation dataset show that the proposed method improves the tradeoff between reconstruction error and communication energy consumption under sim-to-real distribution shift. We further analyze the effectiveness of the proposed algorithm across various wireless channels and dynamic motion trajectories.
HICT: High-precision 3D CBCT reconstruction from a single X-ray
Apr 01, 2026Accurate 3D dental imaging is vital for diagnosis and treatment planning, yet CBCT's high radiation dose and cost limit its accessibility. Reconstructing 3D volumes from a single low-dose panoramic X-ray is a promising alternative but remains challenging due to geometric inconsistencies and limited accuracy. We propose HiCT, a two-stage framework that first generates geometrically consistent multi-view projections from a single panoramic image using a video diffusion model, and then reconstructs high-fidelity CBCT from the projections using a ray-based dynamic attention network and an X-ray sampling strategy. To support this, we built XCT, a large-scale dataset combining public CBCT data with 500 paired PX-CBCT cases. Extensive experiments show that HiCT achieves state-of-the-art performance, delivering accurate and geometrically consistent reconstructions for clinical use.
Intent-Context Synergy Reinforcement Learning for Autonomous UAV Decision-Making in Air Combat
Mar 01, 2026Autonomous UAV infiltration in dynamic contested environments remains a significant challenge due to the partially observable nature of threats and the conflicting objectives of mission efficiency versus survivability. Traditional Reinforcement Learning (RL) approaches often suffer from myopic decision-making and struggle to balance these trade-offs in real-time. To address these limitations, this paper proposes an Intent-Context Synergy Reinforcement Learning (ICS-RL) framework. The framework introduces two core innovations: (1) An LSTM-based Intent Prediction Module that forecasts the future trajectories of hostile units, transforming the decision paradigm from reactive avoidance to proactive planning via state augmentation; (2) A Context-Analysis Synergy Mechanism that decomposes the mission into hierarchical sub-tasks (safe cruise, stealth planning, and hostile breakthrough). We design a heterogeneous ensemble of Dueling DQN agents, each specialized in a specific tactical context. A dynamic switching controller based on Max-Advantage values seamlessly integrates these agents, allowing the UAV to adaptively select the optimal policy without hard-coded rules. Extensive simulations demonstrate that ICS-RL significantly outperforms baselines (Standard DDQN) and traditional methods (PSO, Game Theory). The proposed method achieves a mission success rate of 88\% and reduces the average exposure frequency to 0.24 per episode, validating its superiority in ensuring robust and stealthy penetration in high-dynamic scenarios.
Differentiable Rule Induction from Raw Sequence Inputs
Feb 14, 2026Rule learning-based models are widely used in highly interpretable scenarios due to their transparent structures. Inductive logic programming (ILP), a form of machine learning, induces rules from facts while maintaining interpretability. Differentiable ILP models enhance this process by leveraging neural networks to improve robustness and scalability. However, most differentiable ILP methods rely on symbolic datasets, facing challenges when learning directly from raw data. Specifically, they struggle with explicit label leakage: The inability to map continuous inputs to symbolic variables without explicit supervision of input feature labels. In this work, we address this issue by integrating a self-supervised differentiable clustering model with a novel differentiable ILP model, enabling rule learning from raw data without explicit label leakage. The learned rules effectively describe raw data through its features. We demonstrate that our method intuitively and precisely learns generalized rules from time series and image data.
Joint Source-Channel-Generation Coding: From Distortion-oriented Reconstruction to Semantic-consistent Generation
Jan 19, 2026Conventional communication systems, including both separation-based coding and AI-driven joint source-channel coding (JSCC), are largely guided by Shannon's rate-distortion theory. However, relying on generic distortion metrics fails to capture complex human visual perception, often resulting in blurred or unrealistic reconstructions. In this paper, we propose Joint Source-Channel-Generation Coding (JSCGC), a novel paradigm that shifts the focus from deterministic reconstruction to probabilistic generation. JSCGC leverages a generative model at the receiver as a generator rather than a conventional decoder to parameterize the data distribution, enabling direct maximization of mutual information under channel constraints while controlling stochastic sampling to produce outputs residing on the authentic data manifold with high fidelity. We further derive a theoretical lower bound on the maximum semantic inconsistency with given transmitted mutual information, elucidating the fundamental limits of communication in controlling the generative process. Extensive experiments on image transmission demonstrate that JSCGC substantially improves perceptual quality and semantic fidelity, significantly outperforming conventional distortion-oriented JSCC methods.
Listen, Look, Drive: Coupling Audio Instructions for User-aware VLA-based Autonomous Driving
Jan 17, 2026Vision Language Action (VLA) models promise an open-vocabulary interface that can translate perceptual ambiguity into semantically grounded driving decisions, yet they still treat language as a static prior fixed at inference time. As a result, the model must infer continuously shifting objectives from pixels alone, yielding delayed or overly conservative maneuvers. We argue that effective VLAs for autonomous driving need an online channel in which users can influence driving with specific intentions. To this end, we present EchoVLA, a user-aware VLA that couples camera streams with in situ audio instructions. We augment the nuScenes dataset with temporally aligned, intent-specific speech commands generated by converting ego-motion descriptions into synthetic audios. Further, we compose emotional speech-trajectory pairs into a multimodal Chain-of-Thought (CoT) for fine-tuning a Multimodal Large Model (MLM) based on Qwen2.5-Omni. Specifically, we synthesize the audio-augmented dataset with different emotion types paired with corresponding driving behaviors, leveraging the emotional cues embedded in tone, pitch, and speech tempo to reflect varying user states, such as urgent or hesitant intentions, thus enabling our EchoVLA to interpret not only the semantic content but also the emotional context of audio commands for more nuanced and emotionally adaptive driving behavior. In open-loop benchmarks, our approach reduces the average L2 error by $59.4\%$ and the collision rate by $74.4\%$ compared to the baseline of vision-only perception. More experiments on nuScenes dataset validate that EchoVLA not only steers the trajectory through audio instructions, but also modulates driving behavior in response to the emotions detected in the user's speech.
LLMTrack: Semantic Multi-Object Tracking with Multi-modal Large Language Models
Jan 10, 2026Traditional Multi-Object Tracking (MOT) systems have achieved remarkable precision in localization and association, effectively answering \textit{where} and \textit{who}. However, they often function as autistic observers, capable of tracing geometric paths but blind to the semantic \textit{what} and \textit{why} behind object behaviors. To bridge the gap between geometric perception and cognitive reasoning, we propose \textbf{LLMTrack}, a novel end-to-end framework for Semantic Multi-Object Tracking (SMOT). We adopt a bionic design philosophy that decouples strong localization from deep understanding, utilizing Grounding DINO as the eyes and the LLaVA-OneVision multimodal large model as the brain. We introduce a Spatio-Temporal Fusion Module that aggregates instance-level interaction features and video-level contexts, enabling the Large Language Model (LLM) to comprehend complex trajectories. Furthermore, we design a progressive three-stage training strategy, Visual Alignment, Temporal Fine-tuning, and Semantic Injection via LoRA to efficiently adapt the massive model to the tracking domain. Extensive experiments on the BenSMOT benchmark demonstrate that LLMTrack achieves state-of-the-art performance, significantly outperforming existing methods in instance description, interaction recognition, and video summarization while maintaining robust tracking stability.
WaTeRFlow: Watermark Temporal Robustness via Flow Consistency
Dec 22, 2025Image watermarking supports authenticity and provenance, yet many schemes are still easy to bypass with various distortions and powerful generative edits. Deep learning-based watermarking has improved robustness to diffusion-based image editing, but a gap remains when a watermarked image is converted to video by image-to-video (I2V), in which per-frame watermark detection weakens. I2V has quickly advanced from short, jittery clips to multi-second, temporally coherent scenes, and it now serves not only content creation but also world-modeling and simulation workflows, making cross-modal watermark recovery crucial. We present WaTeRFlow, a framework tailored for robustness under I2V. It consists of (i) FUSE (Flow-guided Unified Synthesis Engine), which exposes the encoder-decoder to realistic distortions via instruction-driven edits and a fast video diffusion proxy during training, (ii) optical-flow warping with a Temporal Consistency Loss (TCL) that stabilizes per-frame predictions, and (iii) a semantic preservation loss that maintains the conditioning signal. Experiments across representative I2V models show accurate watermark recovery from frames, with higher first-frame and per-frame bit accuracy and resilience when various distortions are applied before or after video generation.
StereoMV2D: A Sparse Temporal Stereo-Enhanced Framework for Robust Multi-View 3D Object Detection
Dec 19, 2025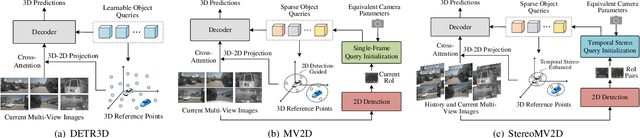
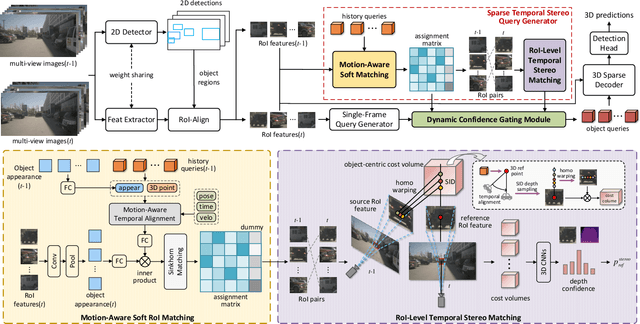
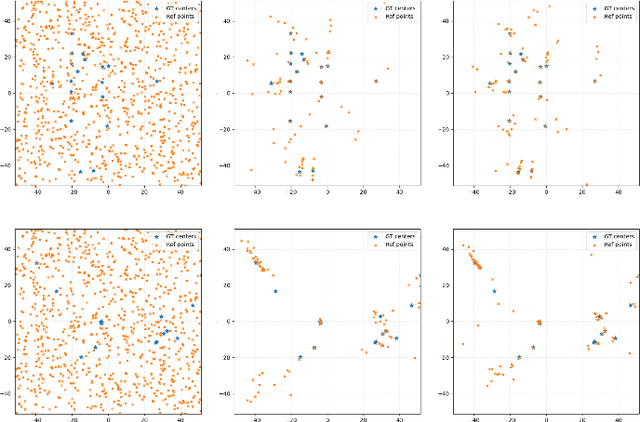

Multi-view 3D object detection is a fundamental task in autonomous driving perception, where achieving a balance between detection accuracy and computational efficiency remains crucial. Sparse query-based 3D detectors efficiently aggregate object-relevant features from multi-view images through a set of learnable queries, offering a concise and end-to-end detection paradigm. Building on this foundation, MV2D leverages 2D detection results to provide high-quality object priors for query initialization, enabling higher precision and recall. However, the inherent depth ambiguity in single-frame 2D detections still limits the accuracy of 3D query generation. To address this issue, we propose StereoMV2D, a unified framework that integrates temporal stereo modeling into the 2D detection-guided multi-view 3D detector. By exploiting cross-temporal disparities of the same object across adjacent frames, StereoMV2D enhances depth perception and refines the query priors, while performing all computations efficiently within 2D regions of interest (RoIs). Furthermore, a dynamic confidence gating mechanism adaptively evaluates the reliability of temporal stereo cues through learning statistical patterns derived from the inter-frame matching matrix together with appearance consistency, ensuring robust detection under object appearance and occlusion. Extensive experiments on the nuScenes and Argoverse 2 datasets demonstrate that StereoMV2D achieves superior detection performance without incurring significant computational overhead. Code will be available at https://github.com/Uddd821/StereoMV2D.