 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Branch Residual Network for Cross-Domain Few-Shot Hyperspectral Image Classification with Refined Prototype
Apr 27, 2025Convolutional neural networks (CNNs) are effective for hyperspectral image (HSI) classification, but their 3D convolutional structures introduce high computational costs and limited generalization in few-shot scenarios. Domain shifts caused by sensor differences and environmental variations further hinder cross-dataset adaptability. Metric-based few-shot learning (FSL) prototype networks mitigate this problem, yet their performance is sensitive to prototype quality, especially with limited samples. To overcome these challenges, a dual-branch residual network that integrates spatial and spectral features via parallel branches is proposed in this letter. Additionally, more robust refined prototypes are obtained through a regulation term. Furthermore, a kernel probability matching strategy aligns source and target domain features, alleviating domain shift. Experiments on four publicly available HSI datasets illustrate that the proposal achieves superior performance compared to other methods.
Towards Student Actions in Classroom Scenes: New Dataset and Baseline
Sep 02, 2024



Analyzing student actions is an important and challenging task in educational research. Existing efforts have been hampered by the lack of accessible datasets to capture the nuanced action dynamics in classrooms. In this paper, we present a new multi-label student action video (SAV) dataset for complex classroom scenes. The dataset consists of 4,324 carefully trimmed video clips from 758 different classrooms, each labeled with 15 different actions displayed by students in classrooms. Compared to existing behavioral datasets, our dataset stands out by providing a wide range of real classroom scenarios, high-quality video data, and unique challenges, including subtle movement differences, dense object engagement, significant scale differences, varied shooting angles, and visual occlusion. The increased complexity of the dataset brings new opportunities and challenges for benchmarking action detection. Innovatively, we also propose a new baseline method, a visual transformer for enhancing attention to key local details in small and dense object regions. Our method achieves excellent performance with mean Average Precision (mAP) of 67.9\% and 27.4\% on SAV and AVA, respectively. This paper not only provides the dataset but also calls for further research into AI-driven educational tools that may transform teaching methodologies and learning outcomes. The code and dataset will be released at https://github.com/Ritatanz/SAV.
Low-Rank Matrix Recovery from Noisy via an MDL Framework-based Atomic Norm
Sep 17, 2020



The recovery of the underlying low-rank structure of clean data corrupted with sparse noise/outliers is attracting increasing interest. However, in many low-level vision problems, the exact target rank of the underlying structure, the particular locations and values of the sparse outliers are not known. Thus, the conventional methods can not separate the low-rank and sparse components completely, especially gross outliers or deficient observations. Therefore, in this study, we employ the Minimum Description Length (MDL) principle and atomic norm for low-rank matrix recovery to overcome these limitations. First, we employ the atomic norm to find all the candidate atoms of low-rank and sparse terms, and then we minimize the description length of the model in order to select the appropriate atoms of low-rank and the sparse matrix, respectively. Our experimental analyses show that the proposed approach can obtain a higher success rate than the state-of-the-art methods even when the number of observations is limited or the corruption ratio is high. Experimental results about synthetic data and real sensing applications (high dynamic range imaging, background modeling, removing shadows and specularities) demonstrate the effectiveness, robustness and efficiency of the proposed method.
Learning a Deep Part-based Representation by Preserving Data Distribution
Sep 17, 2020



Unsupervised dimensionality reduction is one of the commonly used techniques in the field of high dimensional data recognition problems. The deep autoencoder network which constrains the weights to be non-negative, can learn a low dimensional part-based representation of data. On the other hand, the inherent structure of the each data cluster can be described by the distribution of the intraclass samples. Then one hopes to learn a new low dimensional representation which can preserve the intrinsic structure embedded in the original high dimensional data space perfectly. In this paper, by preserving the data distribution, a deep part-based representation can be learned, and the novel algorithm is called Distribution Preserving Network Embedding (DPNE). In DPNE, we first need to estimate the distribution of the original high dimensional data using the $k$-nearest neighbor kernel density estimation, and then we seek a part-based representation which respects the above distribution. The experimental results on the real-world data sets show that the proposed algorithm has good performance in terms of cluster accuracy and AMI. It turns out that the manifold structure in the raw data can be well preserved in the low dimensional feature space.
A Multiscale Image Denoising Algorithm Based On Dilated Residual Convolution Network
Dec 21, 2018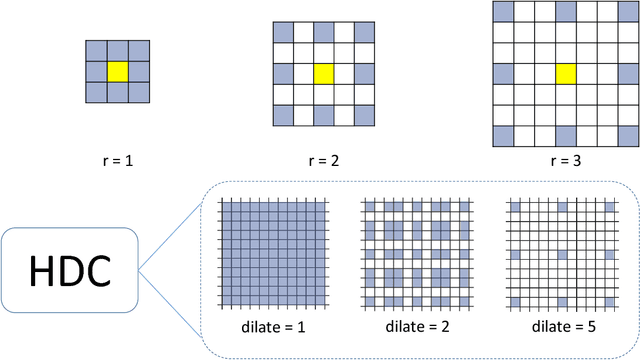

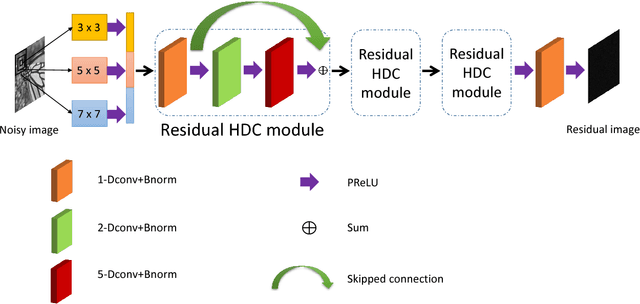
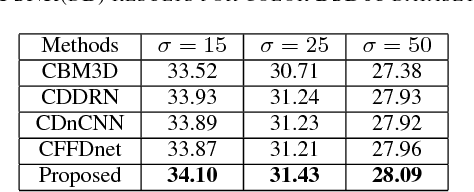
Image denoising is a classical problem in low level computer vision. Model-based optimization methods and deep learning approaches have been the two main strategies for solving the problem. Model-based optimization methods are flexible for handling different inverse problems but are usually time-consuming. In contrast, deep learning methods have fast testing speed but the performance of these CNNs is still inferior. To address this issue, here we propose a novel deep residual learning model that combines the dilated residual convolution and multi-scale convolution groups. Due to the complex patterns and structures of inside an image, the multiscale convolution group is utilized to learn those patterns and enlarge the receptive field. Specifically, the residual connection and batch normalization are utilized to speed up the training process and maintain the denoising performance. In order to decrease the gridding artifacts, we integrate the hybrid dilated convolution design into our model. To this end, this paper aims to train a lightweight and effective denoiser based on multiscale convolution group. Experimental results have demonstrated that the enhanced denoiser can not only achieve promising denoising results, but also become a strong competitor in practical application.