 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing the Authenticity of Rendered Portraits with Identity-Consistent Transfer Learning
Oct 06, 2023
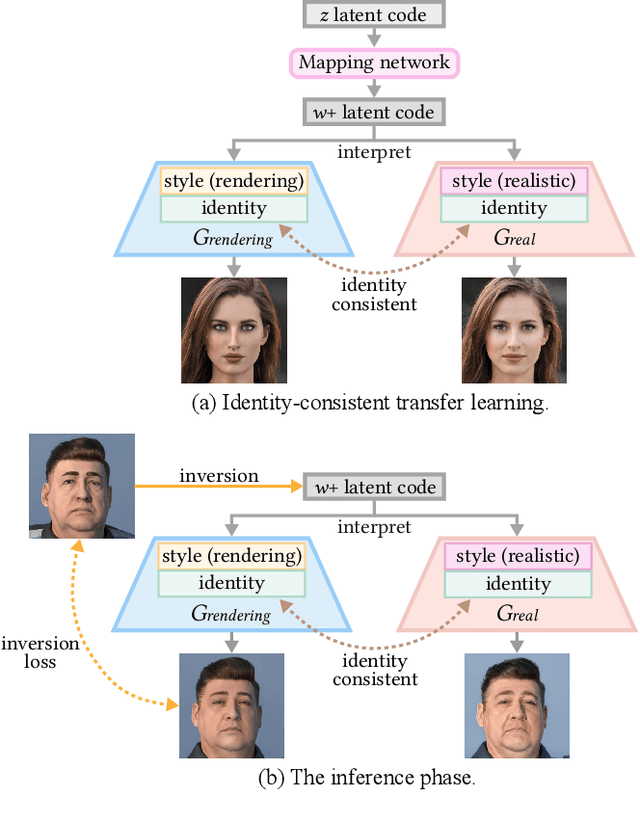

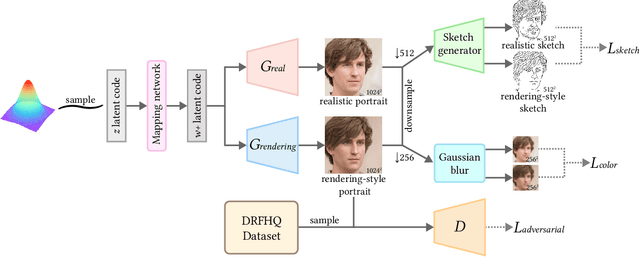
Despite rapid advances in computer graphics, creating high-quality photo-realistic virtual portraits is prohibitively expensive. Furthermore, the well-know ''uncanny valley'' effect in rendered portraits has a significant impact on the user experience, especially when the depiction closely resembles a human likeness, where any minor artifacts can evoke feelings of eeriness and repulsiveness. In this paper, we present a novel photo-realistic portrait generation framework that can effectively mitigate the ''uncanny valley'' effect and improve the overall authenticity of rendered portraits. Our key idea is to employ transfer learning to learn an identity-consistent mapping from the latent space of rendered portraits to that of real portraits. During the inference stage, the input portrait of an avatar can be directly transferred to a realistic portrait by changing its appearance style while maintaining the facial identity. To this end, we collect a new dataset, Daz-Rendered-Faces-HQ (DRFHQ), that is specifically designed for rendering-style portraits. We leverage this dataset to fine-tune the StyleGAN2 generator, using our carefully crafted framework, which helps to preserve the geometric and color features relevant to facial identity. We evaluate our framework using portraits with diverse gender, age, and race variations. Qualitative and quantitative evaluations and ablation studies show the advantages of our method compared to state-of-the-art approaches.
Low-Rank Matrix Recovery from Noisy via an MDL Framework-based Atomic Norm
Sep 17, 2020



The recovery of the underlying low-rank structure of clean data corrupted with sparse noise/outliers is attracting increasing interest. However, in many low-level vision problems, the exact target rank of the underlying structure, the particular locations and values of the sparse outliers are not known. Thus, the conventional methods can not separate the low-rank and sparse components completely, especially gross outliers or deficient observations. Therefore, in this study, we employ the Minimum Description Length (MDL) principle and atomic norm for low-rank matrix recovery to overcome these limitations. First, we employ the atomic norm to find all the candidate atoms of low-rank and sparse terms, and then we minimize the description length of the model in order to select the appropriate atoms of low-rank and the sparse matrix, respectively. Our experimental analyses show that the proposed approach can obtain a higher success rate than the state-of-the-art methods even when the number of observations is limited or the corruption ratio is high. Experimental results about synthetic data and real sensing applications (high dynamic range imaging, background modeling, removing shadows and specularities) demonstrate the effectiveness, robustness and efficiency of the proposed method.
Class Regularization: Improve Few-shot Image Classification by Reducing Meta Shift
Dec 18, 2019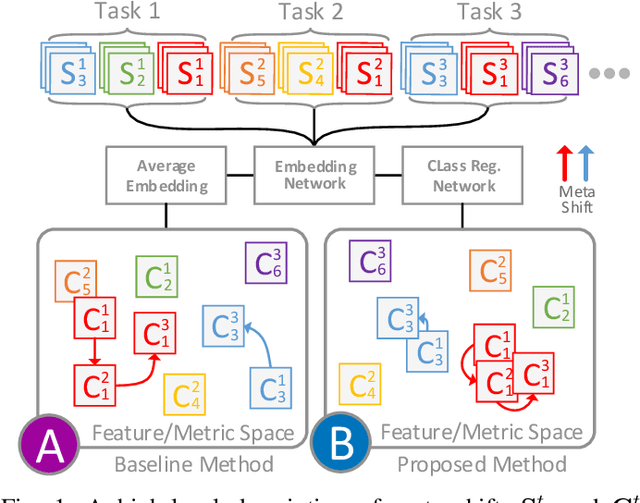
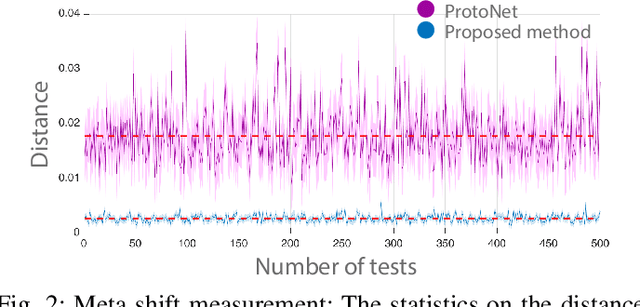

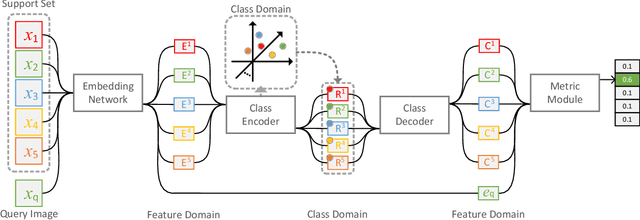
Few-shot image classification requires the classifier to robustly cope with unseen classes even if there are only a few samples for each class. Recent advances benefit from the meta-learning process where episodic tasks are formed to train a model that can adapt to class change. However, these tasks are independent to each other and existing works mainly rely on limited samples of individual support set in a single meta task. This strategy leads to severe meta shift issues across multiple tasks, meaning the learned prototypes or class descriptors are not stable as each task only involves their own support set. To avoid this problem, we propose a concise Class Regularization Network which aggregates the embedding features of all samples in the entire training set and further regularizes the generated class descriptor. The key is to train a class encoder and decoder structure that can encode the embedding sample features into a class domain with trained class basis, and generate a more stable and general class descriptor from the decoder. We evaluate our work by extensive comparisons with previous methods on two benchmark datasets (MiniImageNet and CUB). The results show that our method achieves state-of-the-art performance over previous work.
SMART: Skeletal Motion Action Recognition aTtack
Nov 21, 2019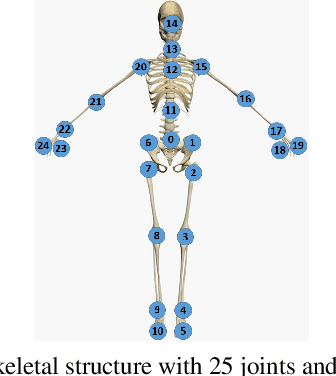
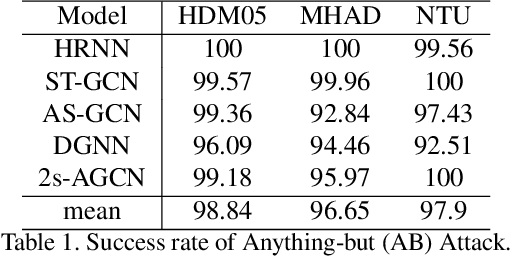
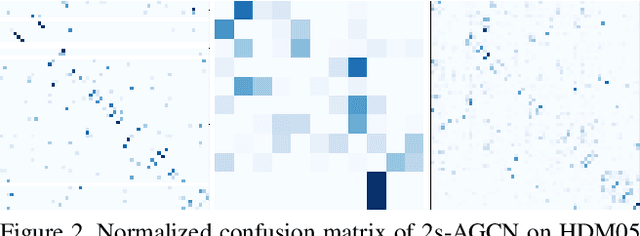
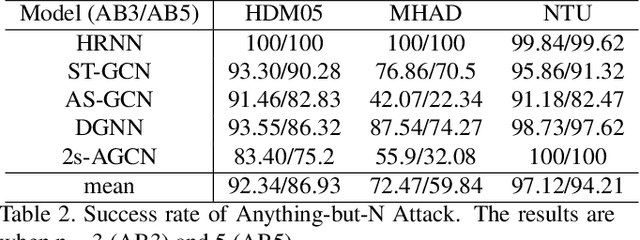
Adversarial attack has inspired great interest in computer vision, by showing that classification-based solutions are prone to imperceptible attack in many tasks. In this paper, we propose a method, SMART, to attack action recognizers which rely on 3D skeletal motions. Our method involves an innovative perceptual loss which ensures the imperceptibility of the attack. Empirical studies demonstrate that SMART is effective in both white-box and black-box scenarios. Its generalizability is evidenced on a variety of action recognizers and datasets. Its versatility is shown in different attacking strategies. Its deceitfulness is proven in extensive perceptual studies. Finally, SMART shows that adversarial attack on 3D skeletal motion, one type of time-series data, is significantly different from traditional adversarial attack problems.