 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Horse with no Labels: Self-Supervised Horse Pose Estimation from Unlabelled Images and Synthetic Prior
Aug 07, 2023Obtaining labelled data to train deep learning methods for estimating animal pose is challenging. Recently, synthetic data has been widely used for pose estimation tasks, but most methods still rely on supervised learning paradigms utilising synthetic images and labels. Can training be fully unsupervised? Is a tiny synthetic dataset sufficient? What are the minimum assumptions that we could make for estimating animal pose? Our proposal addresses these questions through a simple yet effective self-supervised method that only assumes the availability of unlabelled images and a small set of synthetic 2D poses. We completely remove the need for any 3D or 2D pose annotations (or complex 3D animal models), and surprisingly our approach can still learn accurate 3D and 2D poses simultaneously. We train our method with unlabelled images of horses mainly collected for YouTube videos and a prior consisting of 2D synthetic poses. The latter is three times smaller than the number of images needed for training. We test our method on a challenging set of horse images and evaluate the predicted 3D and 2D poses. We demonstrate that it is possible to learn accurate animal poses even with as few assumptions as unlabelled images and a small set of 2D poses generated from synthetic data. Given the minimum requirements and the abundance of unlabelled data, our method could be easily deployed to different animals.
Of Mice and Pose: 2D Mouse Pose Estimation from Unlabelled Data and Synthetic Prior
Jul 25, 2023Numerous fields, such as ecology, biology, and neuroscience, use animal recordings to track and measure animal behaviour. Over time, a significant volume of such data has been produced, but some computer vision techniques cannot explore it due to the lack of annotations. To address this, we propose an approach for estimating 2D mouse body pose from unlabelled images using a synthetically generated empirical pose prior. Our proposal is based on a recent self-supervised method for estimating 2D human pose that uses single images and a set of unpaired typical 2D poses within a GAN framework. We adapt this method to the limb structure of the mouse and generate the empirical prior of 2D poses from a synthetic 3D mouse model, thereby avoiding manual annotation. In experiments on a new mouse video dataset, we evaluate the performance of the approach by comparing pose predictions to a manually obtained ground truth. We also compare predictions with those from a supervised state-of-the-art method for animal pose estimation. The latter evaluation indicates promising results despite the lack of paired training data. Finally, qualitative results using a dataset of horse images show the potential of the setting to adapt to other animal species.
Self-supervised 3D Human Pose Estimation from a Single Image
Apr 05, 2023We propose a new self-supervised method for predicting 3D human body pose from a single image. The prediction network is trained from a dataset of unlabelled images depicting people in typical poses and a set of unpaired 2D poses. By minimising the need for annotated data, the method has the potential for rapid application to pose estimation of other articulated structures (e.g. animals). The self-supervision comes from an earlier idea exploiting consistency between predicted pose under 3D rotation. Our method is a substantial advance on state-of-the-art self-supervised methods in training a mapping directly from images, without limb articulation constraints or any 3D empirical pose prior. We compare performance with state-of-the-art self-supervised methods using benchmark datasets that provide images and ground-truth 3D pose (Human3.6M, MPI-INF-3DHP). Despite the reduced requirement for annotated data, we show that the method outperforms on Human3.6M and matches performance on MPI-INF-3DHP. Qualitative results on a dataset of human hands show the potential for rapidly learning to predict 3D pose for articulated structures other than the human body.
Understanding the Vulnerability of Skeleton-based Human Activity Recognition via Black-box Attack
Nov 21, 2022



Human Activity Recognition (HAR) has been employed in a wide range of applications, e.g. self-driving cars, where safety and lives are at stake. Recently, the robustness of existing skeleton-based HAR methods has been questioned due to their vulnerability to adversarial attacks, which causes concerns considering the scale of the implication. However, the proposed attacks require the full-knowledge of the attacked classifier, which is overly restrictive. In this paper, we show such threats indeed exist, even when the attacker only has access to the input/output of the model. To this end, we propose the very first black-box adversarial attack approach in skeleton-based HAR called BASAR. BASAR explores the interplay between the classification boundary and the natural motion manifold. To our best knowledge, this is the first time data manifold is introduced in adversarial attacks on time series. Via BASAR, we find on-manifold adversarial samples are extremely deceitful and rather common in skeletal motions, in contrast to the common belief that adversarial samples only exist off-manifold. Through exhaustive evaluation, we show that BASAR can deliver successful attacks across classifiers, datasets, and attack modes. By attack, BASAR helps identify the potential causes of the model vulnerability and provides insights on possible improvements. Finally, to mitigate the newly identified threat, we propose a new adversarial training approach by leveraging the sophisticated distributions of on/off-manifold adversarial samples, called mixed manifold-based adversarial training (MMAT). MMAT can successfully help defend against adversarial attacks without compromising classification accuracy.
Anomaly detection using prediction error with Spatio-Temporal Convolutional LSTM
May 18, 2022



In this paper, we propose a novel method for video anomaly detection motivated by an existing architecture for sequence-to-sequence prediction and reconstruction using a spatio-temporal convolutional Long Short-Term Memory (convLSTM). As in previous work on anomaly detection, anomalies arise as spatially localised failures in reconstruction or prediction. In experiments with five benchmark datasets, we show that using prediction gives superior performance to using reconstruction. We also compare performance with different length input/output sequences. Overall, our results using prediction are comparable with the state of the art on the benchmark datasets.
Understanding the Robustness of Skeleton-based Action Recognition under Adversarial Attack
Mar 18, 2021
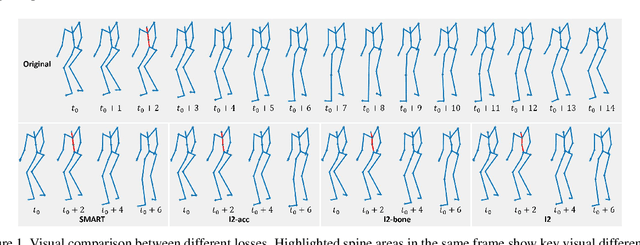
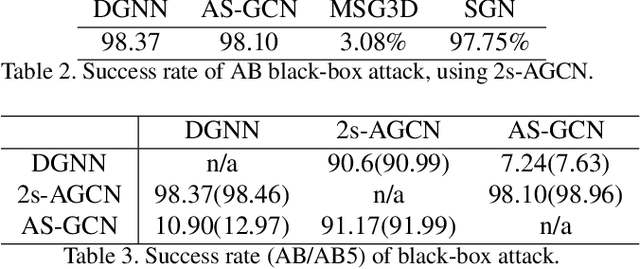
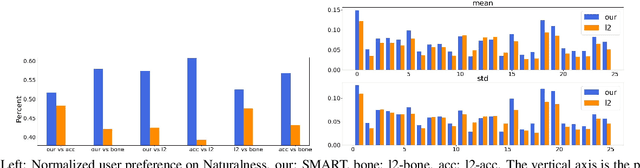
Action recognition has been heavily employed in many applications such as autonomous vehicles, surveillance, etc, where its robustness is a primary concern. In this paper, we examine the robustness of state-of-the-art action recognizers against adversarial attack, which has been rarely investigated so far. To this end, we propose a new method to attack action recognizers that rely on 3D skeletal motion. Our method involves an innovative perceptual loss that ensures the imperceptibility of the attack. Empirical studies demonstrate that our method is effective in both white-box and black-box scenarios. Its generalizability is evidenced on a variety of action recognizers and datasets. Its versatility is shown in different attacking strategies. Its deceitfulness is proven in extensive perceptual studies. Our method shows that adversarial attack on 3D skeletal motions, one type of time-series data, is significantly different from traditional adversarial attack problems. Its success raises serious concern on the robustness of action recognizers and provides insights on potential improvements.
SMART: Skeletal Motion Action Recognition aTtack
Nov 21, 2019
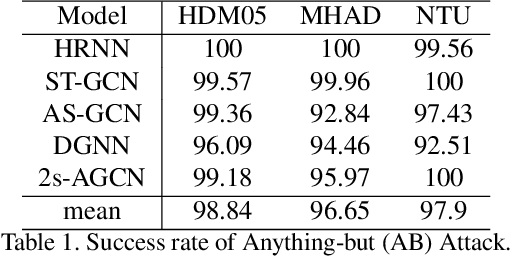
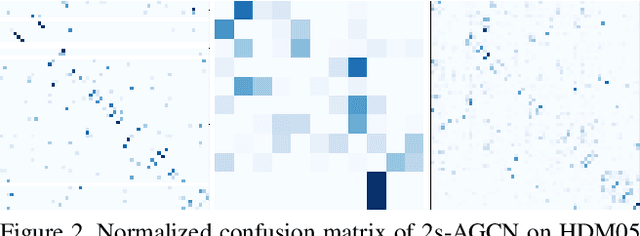
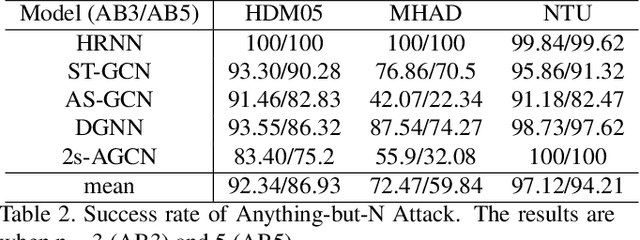
Adversarial attack has inspired great interest in computer vision, by showing that classification-based solutions are prone to imperceptible attack in many tasks. In this paper, we propose a method, SMART, to attack action recognizers which rely on 3D skeletal motions. Our method involves an innovative perceptual loss which ensures the imperceptibility of the attack. Empirical studies demonstrate that SMART is effective in both white-box and black-box scenarios. Its generalizability is evidenced on a variety of action recognizers and datasets. Its versatility is shown in different attacking strategies. Its deceitfulness is proven in extensive perceptual studies. Finally, SMART shows that adversarial attack on 3D skeletal motion, one type of time-series data, is significantly different from traditional adversarial attack problems.
Personalizing Human Video Pose Estimation
Jun 15, 2016
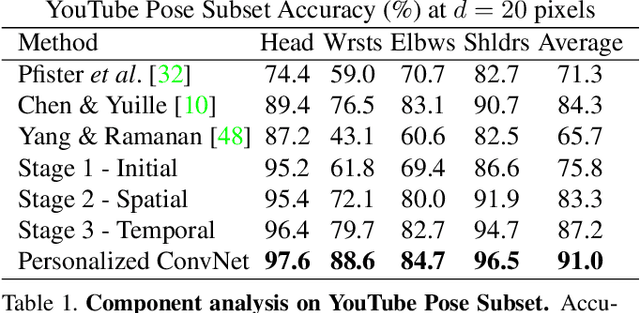

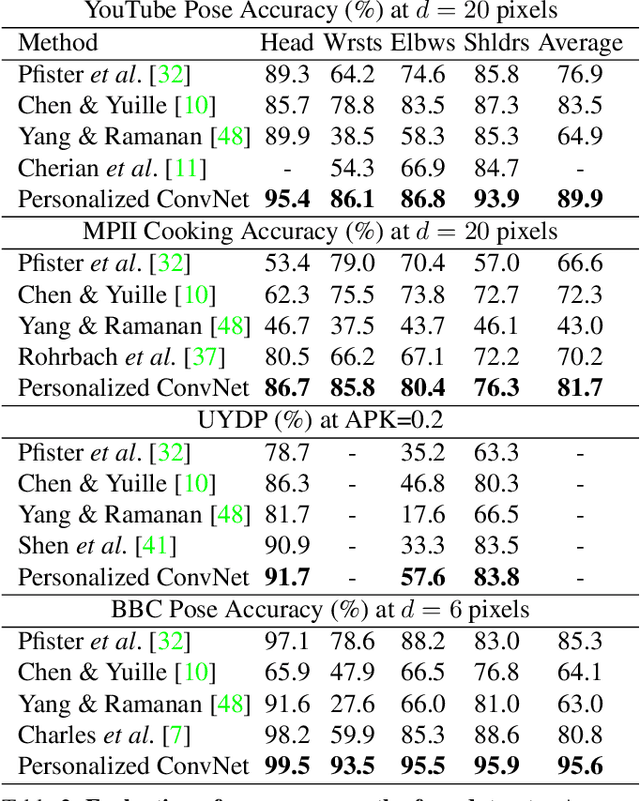
We propose a personalized ConvNet pose estimator that automatically adapts itself to the uniqueness of a person's appearance to improve pose estimation in long videos. We make the following contributions: (i) we show that given a few high-precision pose annotations, e.g. from a generic ConvNet pose estimator, additional annotations can be generated throughout the video using a combination of image-based matching for temporally distant frames, and dense optical flow for temporally local frames; (ii) we develop an occlusion aware self-evaluation model that is able to automatically select the high-quality and reject the erroneous additional annotations; and (iii) we demonstrate that these high-quality annotations can be used to fine-tune a ConvNet pose estimator and thereby personalize it to lock on to key discriminative features of the person's appearance. The outcome is a substantial improvement in the pose estimates for the target video using the personalized ConvNet compared to the original generic ConvNet. Our method outperforms the state of the art (including top ConvNet methods) by a large margin on two standard benchmarks, as well as on a new challenging YouTube video dataset. Furthermore, we show that training from the automatically generated annotations can be used to improve the performance of a generic ConvNet on other benchmarks.