 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOf Mice and Pose: 2D Mouse Pose Estimation from Unlabelled Data and Synthetic Prior
Jul 25, 2023Numerous fields, such as ecology, biology, and neuroscience, use animal recordings to track and measure animal behaviour. Over time, a significant volume of such data has been produced, but some computer vision techniques cannot explore it due to the lack of annotations. To address this, we propose an approach for estimating 2D mouse body pose from unlabelled images using a synthetically generated empirical pose prior. Our proposal is based on a recent self-supervised method for estimating 2D human pose that uses single images and a set of unpaired typical 2D poses within a GAN framework. We adapt this method to the limb structure of the mouse and generate the empirical prior of 2D poses from a synthetic 3D mouse model, thereby avoiding manual annotation. In experiments on a new mouse video dataset, we evaluate the performance of the approach by comparing pose predictions to a manually obtained ground truth. We also compare predictions with those from a supervised state-of-the-art method for animal pose estimation. The latter evaluation indicates promising results despite the lack of paired training data. Finally, qualitative results using a dataset of horse images show the potential of the setting to adapt to other animal species.
Contactless hand tremor amplitude measurement using smartphones: development and pilot evaluation
Apr 28, 2023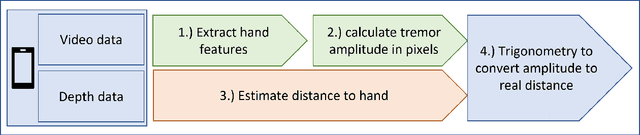
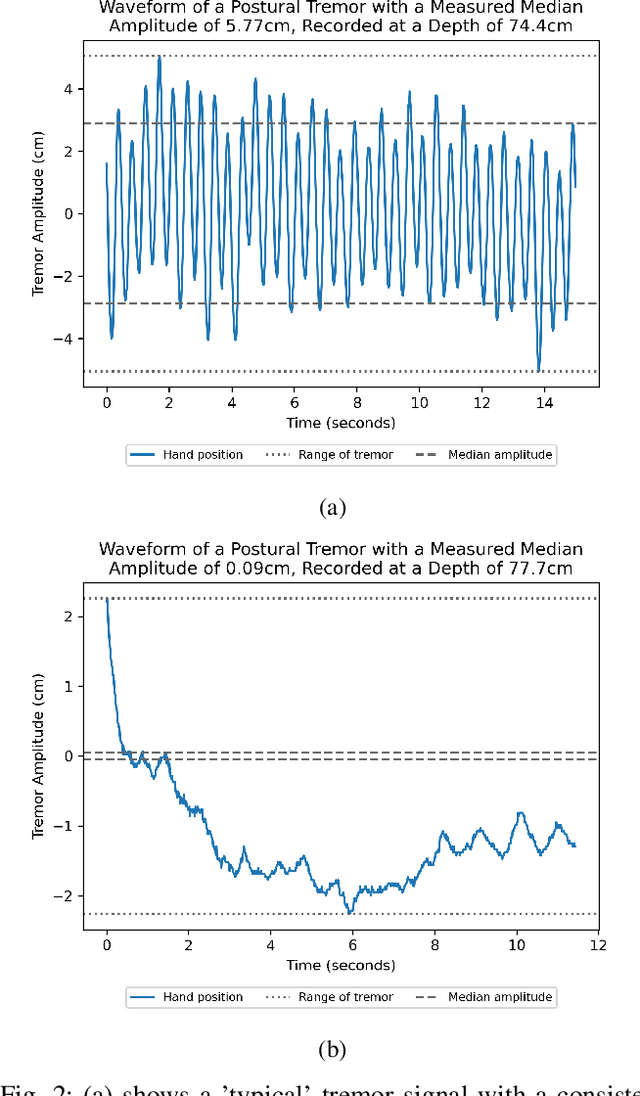

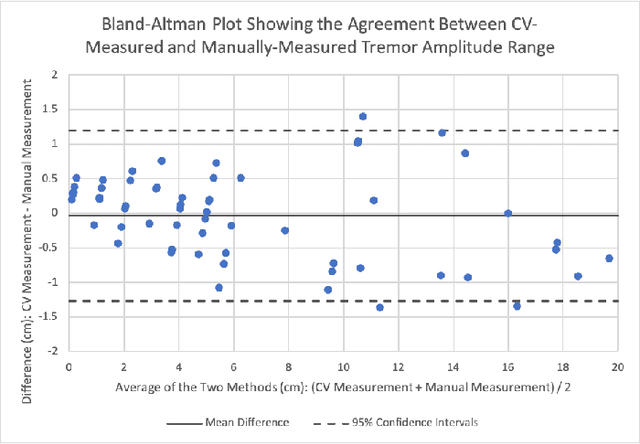
Background: Physiological tremor is defined as an involuntary and rhythmic shaking. Tremor of the hand is a key symptom of multiple neurological diseases, and its frequency and amplitude differs according to both disease type and disease progression. In routine clinical practice, tremor frequency and amplitude are assessed by expert rating using a 0 to 4 integer scale. Such ratings are subjective and have poor inter-rater reliability. There is thus a clinical need for a practical and accurate method for objectively assessing hand tremor. Objective: to develop a proof of principle method to measure hand tremor amplitude from smartphone videos. Methods: We created a computer vision pipeline that automatically extracts salient points on the hand and produces a 1-D time series of movement due to tremor, in pixels. Using the smartphones' depth measurement, we convert this measure into real distance units. We assessed the accuracy of the method using 60 videos of simulated tremor of different amplitudes from two healthy adults. Videos were taken at distances of 50, 75 and 100 cm between hand and camera. The participants had skin tone II and VI on the Fitzpatrick scale. We compared our method to a gold-standard measurement from a slide rule. Bland-Altman methods agreement analysis indicated a bias of 0.04 cm and 95% limits of agreement from -1.27 to 1.20 cm. Furthermore, we qualitatively observed that the method was robust to differences in skin tone and limited occlusion, such as a band-aid affixed to the participant's hand. Clinical relevance: We have demonstrated how tremor amplitude can be measured from smartphone videos. In conjunction with tremor frequency, this approach could be used to help diagnose and monitor neurological diseases
A Comprehensive Review on Deep Supervision: Theories and Applications
Jul 06, 2022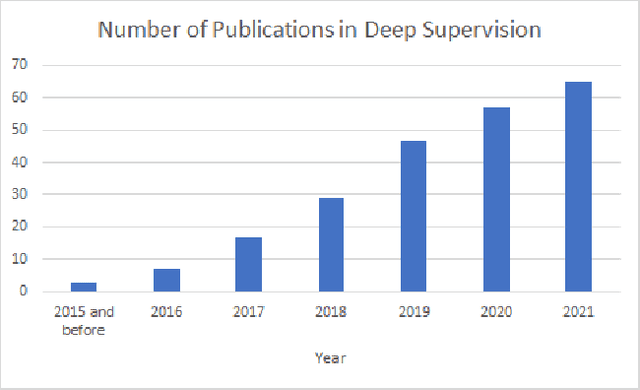
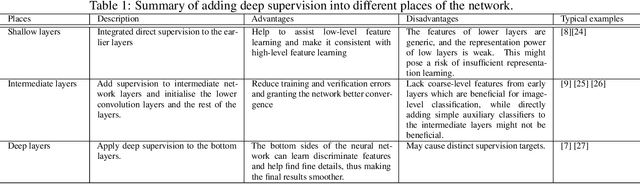
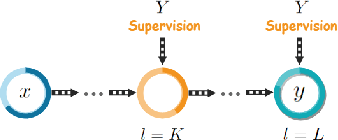

Deep supervision, or known as 'intermediate supervision' or 'auxiliary supervision', is to add supervision at hidden layers of a neural network. This technique has been increasingly applied in deep neural network learning systems for various computer vision applications recently. There is a consensus that deep supervision helps improve neural network performance by alleviating the gradient vanishing problem, as one of the many strengths of deep supervision. Besides, in different computer vision applications, deep supervision can be applied in different ways. How to make the most use of deep supervision to improve network performance in different applications has not been thoroughly investigated. In this paper, we provide a comprehensive in-depth review of deep supervision in both theories and applications. We propose a new classification of different deep supervision networks, and discuss advantages and limitations of current deep supervision networks in computer vision applications.
Parallel Multi-Scale Networks with Deep Supervision for Hand Keypoint Detection
Dec 19, 2021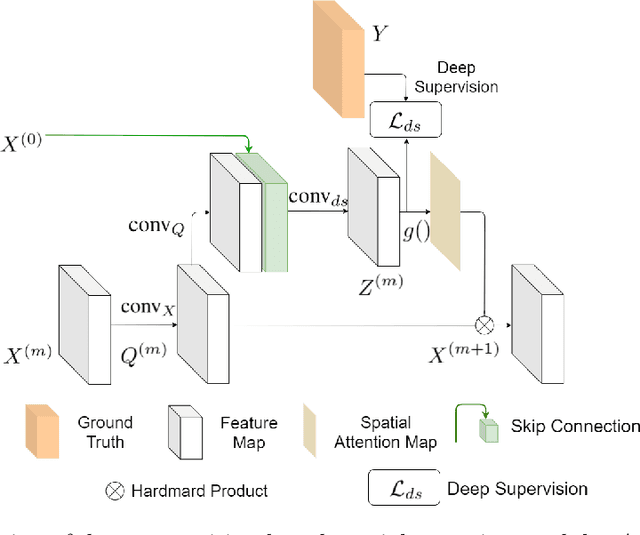

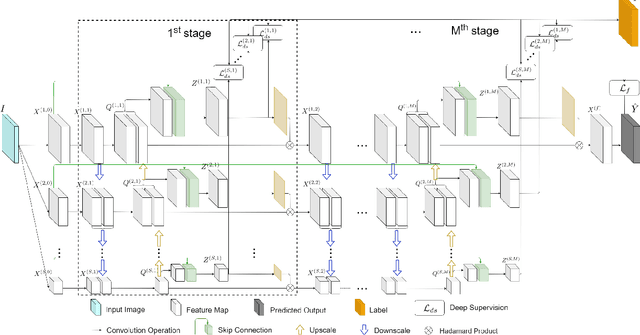
Keypoint detection plays an important role in a wide range of applications. However, predicting keypoints of small objects such as human hands is a challenging problem. Recent works fuse feature maps of deep Convolutional Neural Networks (CNNs), either via multi-level feature integration or multi-resolution aggregation. Despite achieving some success, the feature fusion approaches increase the complexity and the opacity of CNNs. To address this issue, we propose a novel CNN model named Multi-Scale Deep Supervision Network (P-MSDSNet) that learns feature maps at different scales with deep supervisions to produce attention maps for adaptive feature propagation from layers to layers. P-MSDSNet has a multi-stage architecture which makes it scalable while its deep supervision with spatial attention improves transparency to the feature learning at each stage. We show that P-MSDSNet outperforms the state-of-the-art approaches on benchmark datasets while requiring fewer number of parameters. We also show the application of P-MSDSNet to quantify finger tapping hand movements in a neuroscience study.
Hand gesture detection in tests performed by older adults
Oct 29, 2021

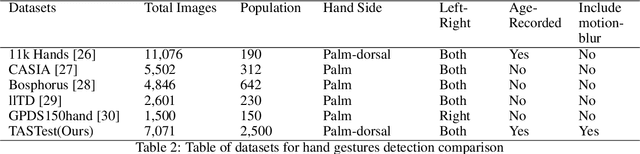
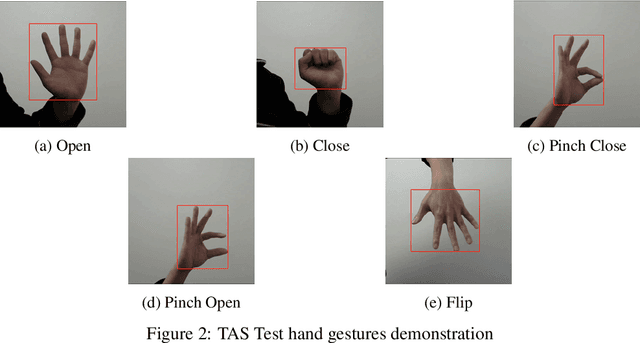
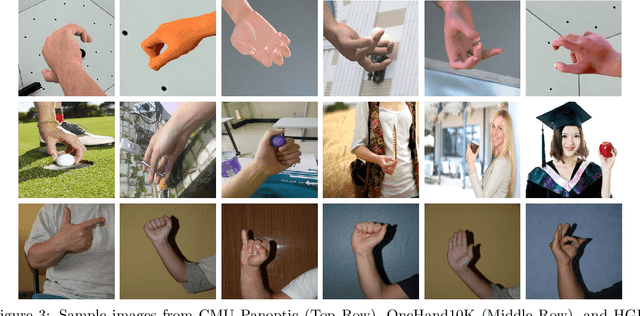
Our team are developing a new online test that analyses hand movement features associated with ageing that can be completed remotely from the research centre. To obtain hand movement features, participants will be asked to perform a variety of hand gestures using their own computer cameras. However, it is challenging to collect high quality hand movement video data, especially for older participants, many of whom have no IT background. During the data collection process, one of the key steps is to detect whether the participants are following the test instructions correctly and also to detect similar gestures from different devices. Furthermore, we need this process to be automated and accurate as we expect many thousands of participants to complete the test. We have implemented a hand gesture detector to detect the gestures in the hand movement tests and our detection mAP is 0.782 which is better than the state-of-the-art. In this research, we have processed 20,000 images collected from hand movement tests and labelled 6,450 images to detect different hand gestures in the hand movement tests. This paper has the following three contributions. Firstly, we compared and analysed the performance of different network structures for hand gesture detection. Secondly, we have made many attempts to improve the accuracy of the model and have succeeded in improving the classification accuracy for similar gestures by implementing attention layers. Thirdly, we have created two datasets and included 20 percent of blurred images in the dataset to investigate how different network structures were impacted by noisy data, our experiments have also shown our network has better performance on the noisy dataset.
Applications of Artificial Intelligence to aid detection of dementia: a narrative review on current capabilities and future directions
Apr 29, 2021



With populations ageing, the number of people with dementia worldwide is expected to triple to 152 million by 2050. Seventy percent of cases are due to Alzheimer's disease (AD) pathology and there is a 10-20 year 'pre-clinical' period before significant cognitive decline occurs. We urgently need, cost effective, objective methods to detect AD, and other dementias, at an early stage. Risk factor modification could prevent 40% of cases and drug trials would have greater chances of success if participants are recruited at an earlier stage. Currently, detection of dementia is largely by pen and paper cognitive tests but these are time consuming and insensitive to pre-clinical phases. Specialist brain scans and body fluid biomarkers can detect the earliest stages of dementia but are too invasive or expensive for widespread use. With the advancement of technology, Artificial Intelligence (AI) shows promising results in assisting with detection of early-stage dementia. Existing AI-aided methods and potential future research directions are reviewed and discussed.