 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Prediction of Lymph Node Metastasis in Rectal Cancer MRI Using Variational Autoencoders
Jul 15, 2025Effective treatment for rectal cancer relies on accurate lymph node metastasis (LNM) staging. However, radiological criteria based on lymph node (LN) size, shape and texture morphology have limited diagnostic accuracy. In this work, we investigate applying a Variational Autoencoder (VAE) as a feature encoder model to replace the large pre-trained Convolutional Neural Network (CNN) used in existing approaches. The motivation for using a VAE is that the generative model aims to reconstruct the images, so it directly encodes visual features and meaningful patterns across the data. This leads to a disentangled and structured latent space which can be more interpretable than a CNN. Models are deployed on an in-house MRI dataset with 168 patients who did not undergo neo-adjuvant treatment. The post-operative pathological N stage was used as the ground truth to evaluate model predictions. Our proposed model 'VAE-MLP' achieved state-of-the-art performance on the MRI dataset, with cross-validated metrics of AUC 0.86 +/- 0.05, Sensitivity 0.79 +/- 0.06, and Specificity 0.85 +/- 0.05. Code is available at: https://github.com/benkeel/Lymph_Node_Classification_MIUA.
* Published in Medical Image Understanding and Analysis (MIUA) 2025
Developing the Temporal Graph Convolutional Neural Network Model to Predict Hip Replacement using Electronic Health Records
Sep 10, 2024



Background: Hip replacement procedures improve patient lives by relieving pain and restoring mobility. Predicting hip replacement in advance could reduce pain by enabling timely interventions, prioritising individuals for surgery or rehabilitation, and utilising physiotherapy to potentially delay the need for joint replacement. This study predicts hip replacement a year in advance to enhance quality of life and health service efficiency. Methods: Adapting previous work using Temporal Graph Convolutional Neural Network (TG-CNN) models, we construct temporal graphs from primary care medical event codes, sourced from ResearchOne EHRs of 40-75-year-old patients, to predict hip replacement risk. We match hip replacement cases to controls by age, sex, and Index of Multiple Deprivation. The model, trained on 9,187 cases and 9,187 controls, predicts hip replacement one year in advance. We validate the model on two unseen datasets, recalibrating for class imbalance. Additionally, we conduct an ablation study and compare against four baseline models. Results: Our best model predicts hip replacement risk one year in advance with an AUROC of 0.724 (95% CI: 0.715-0.733) and an AUPRC of 0.185 (95% CI: 0.160-0.209), achieving a calibration slope of 1.107 (95% CI: 1.074-1.139) after recalibration. Conclusions: The TG-CNN model effectively predicts hip replacement risk by identifying patterns in patient trajectories, potentially improving understanding and management of hip-related conditions.
Variational Autoencoders for Feature Exploration and Malignancy Prediction of Lung Lesions
Nov 27, 2023



Lung cancer is responsible for 21% of cancer deaths in the UK and five-year survival rates are heavily influenced by the stage the cancer was identified at. Recent studies have demonstrated the capability of AI methods for accurate and early diagnosis of lung cancer from routine scans. However, this evidence has not translated into clinical practice with one barrier being a lack of interpretable models. This study investigates the application Variational Autoencoders (VAEs), a type of generative AI model, to lung cancer lesions. Proposed models were trained on lesions extracted from 3D CT scans in the LIDC-IDRI public dataset. Latent vector representations of 2D slices produced by the VAEs were explored through clustering to justify their quality and used in an MLP classifier model for lung cancer diagnosis, the best model achieved state-of-the-art metrics of AUC 0.98 and 93.1% accuracy. Cluster analysis shows the VAE latent space separates the dataset of malignant and benign lesions based on meaningful feature components including tumour size, shape, patient and malignancy class. We also include a comparative analysis of the standard Gaussian VAE (GVAE) and the more recent Dirichlet VAE (DirVAE), which replaces the prior with a Dirichlet distribution to encourage a more explainable latent space with disentangled feature representation. Finally, we demonstrate the potential for latent space traversals corresponding to clinically meaningful feature changes.
Contactless hand tremor amplitude measurement using smartphones: development and pilot evaluation
Apr 28, 2023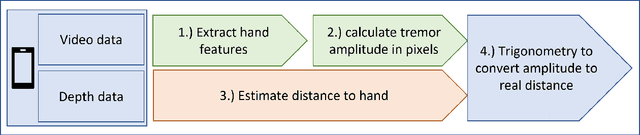
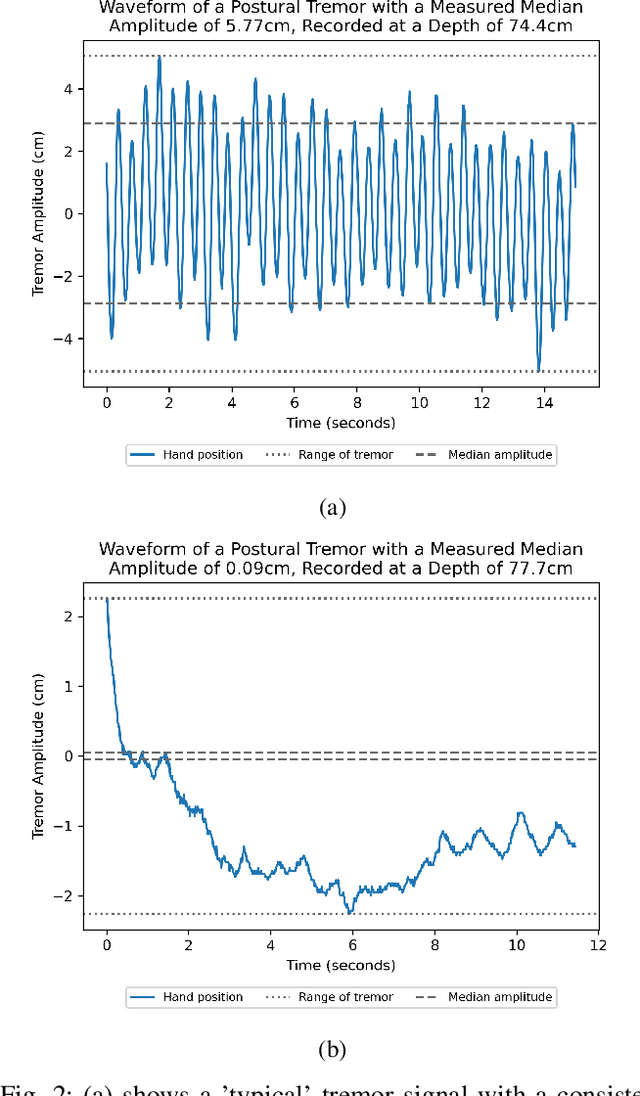

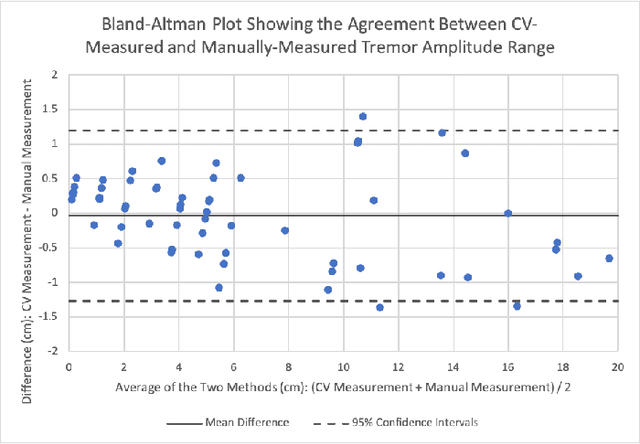
Background: Physiological tremor is defined as an involuntary and rhythmic shaking. Tremor of the hand is a key symptom of multiple neurological diseases, and its frequency and amplitude differs according to both disease type and disease progression. In routine clinical practice, tremor frequency and amplitude are assessed by expert rating using a 0 to 4 integer scale. Such ratings are subjective and have poor inter-rater reliability. There is thus a clinical need for a practical and accurate method for objectively assessing hand tremor. Objective: to develop a proof of principle method to measure hand tremor amplitude from smartphone videos. Methods: We created a computer vision pipeline that automatically extracts salient points on the hand and produces a 1-D time series of movement due to tremor, in pixels. Using the smartphones' depth measurement, we convert this measure into real distance units. We assessed the accuracy of the method using 60 videos of simulated tremor of different amplitudes from two healthy adults. Videos were taken at distances of 50, 75 and 100 cm between hand and camera. The participants had skin tone II and VI on the Fitzpatrick scale. We compared our method to a gold-standard measurement from a slide rule. Bland-Altman methods agreement analysis indicated a bias of 0.04 cm and 95% limits of agreement from -1.27 to 1.20 cm. Furthermore, we qualitatively observed that the method was robust to differences in skin tone and limited occlusion, such as a band-aid affixed to the participant's hand. Clinical relevance: We have demonstrated how tremor amplitude can be measured from smartphone videos. In conjunction with tremor frequency, this approach could be used to help diagnose and monitor neurological diseases
Analysis of an adaptive lead weighted ResNet for multiclass classification of 12-lead ECGs
Dec 01, 2021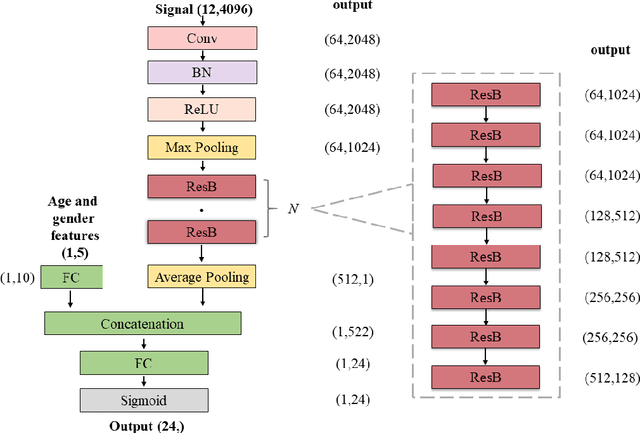

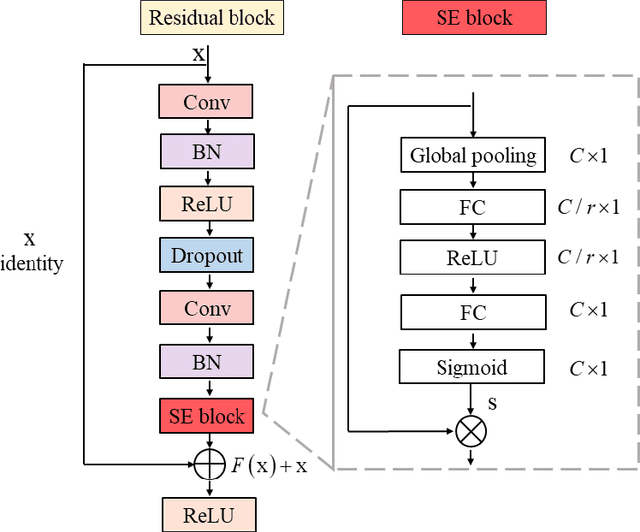
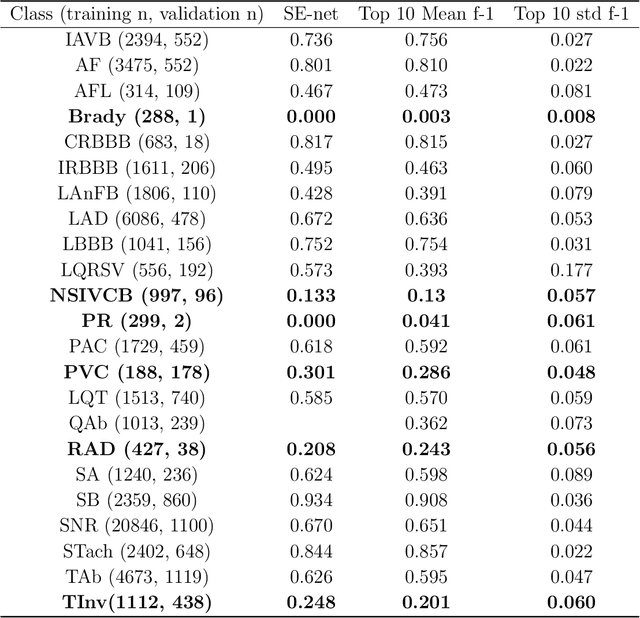
Background: Twelve lead ECGs are a core diagnostic tool for cardiovascular diseases. Here, we describe and analyse an ensemble deep neural network architecture to classify 24 cardiac abnormalities from 12-lead ECGs. Method: We proposed a squeeze and excite ResNet to automatically learn deep features from 12-lead ECGs, in order to identify 24 cardiac conditions. The deep features were augmented with age and gender features in the final fully connected layers. Output thresholds for each class were set using a constrained grid search. To determine why the model made incorrect predictions, two expert clinicians independently interpreted a random set of 100 misclassified ECGs concerning Left Axis Deviation. Results: Using the bespoke weighted accuracy metric, we achieved a 5-fold cross validation score of 0.684, and sensitivity and specificity of 0.758 and 0.969, respectively. We scored 0.520 on the full test data, and ranked 2nd out of 41 in the official challenge rankings. On a random set of misclassified ECGs, agreement between two clinicians and training labels was poor (clinician 1: kappa = -0.057, clinician 2: kappa = -0.159). In contrast, agreement between the clinicians was very high (kappa = 0.92). Discussion: The proposed prediction model performed well on the validation and hidden test data in comparison to models trained on the same data. We also discovered considerable inconsistency in training labels, which is likely to hinder development of more accurate models.