 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpowering All-in-Loop Health Management of Spacecraft Power System in the Mega-Constellation Era via Human-AI Collaboration
Jan 19, 2026It is foreseeable that the number of spacecraft will increase exponentially, ushering in an era dominated by satellite mega-constellations (SMC). This necessitates a focus on energy in space: spacecraft power systems (SPS), especially their health management (HM), given their role in power supply and high failure rates. Providing health management for dozens of SPS and for thousands of SPS represents two fundamentally different paradigms. Therefore, to adapt the health management in the SMC era, this work proposes a principle of aligning underlying capabilities (AUC principle) and develops SpaceHMchat, an open-source Human-AI collaboration (HAIC) framework for all-in-loop health management (AIL HM). SpaceHMchat serves across the entire loop of work condition recognition, anomaly detection, fault localization, and maintenance decision making, achieving goals such as conversational task completion, adaptive human-in-the-loop learning, personnel structure optimization, knowledge sharing, efficiency enhancement, as well as transparent reasoning and improved interpretability. Meanwhile, to validate this exploration, a hardware-realistic fault injection experimental platform is established, and its simulation model is built and open-sourced, both fully replicating the real SPS. The corresponding experimental results demonstrate that SpaceHMchat achieves excellent performance across 23 quantitative metrics, such as 100% conclusion accuracy in logical reasoning of work condition recognition, over 99% success rate in anomaly detection tool invocation, over 90% precision in fault localization, and knowledge base search time under 3 minutes in maintenance decision-making. Another contribution of this work is the release of the first-ever AIL HM dataset of SPS. This dataset contains four sub-datasets, involving 4 types of AIL HM sub-tasks, 17 types of faults, and over 700,000 timestamps.
Small Object Few-shot Segmentation for Vision-based Industrial Inspection
Jul 31, 2024



Vision-based industrial inspection (VII) aims to locate defects quickly and accurately. Supervised learning under a close-set setting and industrial anomaly detection, as two common paradigms in VII, face different problems in practical applications. The former is that various and sufficient defects are difficult to obtain, while the latter is that specific defects cannot be located. To solve these problems, in this paper, we focus on the few-shot semantic segmentation (FSS) method, which can locate unseen defects conditioned on a few annotations without retraining. Compared to common objects in natural images, the defects in VII are small. This brings two problems to current FSS methods: 1 distortion of target semantics and 2 many false positives for backgrounds. To alleviate these problems, we propose a small object few-shot segmentation (SOFS) model. The key idea for alleviating 1 is to avoid the resizing of the original image and correctly indicate the intensity of target semantics. SOFS achieves this idea via the non-resizing procedure and the prototype intensity downsampling of support annotations. To alleviate 2, we design an abnormal prior map in SOFS to guide the model to reduce false positives and propose a mixed normal Dice loss to preferentially prevent the model from predicting false positives. SOFS can achieve FSS and few-shot anomaly detection determined by support masks. Diverse experiments substantiate the superior performance of SOFS. Code is available at https://github.com/zhangzilongc/SOFS.
CA2: Class-Agnostic Adaptive Feature Adaptation for One-class Classification
Sep 04, 2023



One-class classification (OCC), i.e., identifying whether an example belongs to the same distribution as the training data, is essential for deploying machine learning models in the real world. Adapting the pre-trained features on the target dataset has proven to be a promising paradigm for improving OCC performance. Existing methods are constrained by assumptions about the number of classes. This contradicts the real scenario where the number of classes is unknown. In this work, we propose a simple class-agnostic adaptive feature adaptation method (CA2). We generalize the center-based method to unknown classes and optimize this objective based on the prior existing in the pre-trained network, i.e., pre-trained features that belong to the same class are adjacent. CA2 is validated to consistently improve OCC performance across a spectrum of training data classes, spanning from 1 to 1024, outperforming current state-of-the-art methods. Code is available at https://github.com/zhangzilongc/CA2.
Industrial Anomaly Detection with Domain Shift: A Real-world Dataset and Masked Multi-scale Reconstruction
Apr 05, 2023



Industrial anomaly detection (IAD) is crucial for automating industrial quality inspection. The diversity of the datasets is the foundation for developing comprehensive IAD algorithms. Existing IAD datasets focus on the diversity of data categories, overlooking the diversity of domains within the same data category. In this paper, to bridge this gap, we propose the Aero-engine Blade Anomaly Detection (AeBAD) dataset, consisting of two sub-datasets: the single-blade dataset and the video anomaly detection dataset of blades. Compared to existing datasets, AeBAD has the following two characteristics: 1.) The target samples are not aligned and at different scales. 2.) There is a domain shift between the distribution of normal samples in the test set and the training set, where the domain shifts are mainly caused by the changes in illumination and view. Based on this dataset, we observe that current state-of-the-art (SOTA) IAD methods exhibit limitations when the domain of normal samples in the test set undergoes a shift. To address this issue, we propose a novel method called masked multi-scale reconstruction (MMR), which enhances the model's capacity to deduce causality among patches in normal samples by a masked reconstruction task. MMR achieves superior performance compared to SOTA methods on the AeBAD dataset. Furthermore, MMR achieves competitive performance with SOTA methods to detect the anomalies of different types on the MVTec AD dataset. Code and dataset are available at https://github.com/zhangzilongc/MMR.
Analysis of an adaptive lead weighted ResNet for multiclass classification of 12-lead ECGs
Dec 01, 2021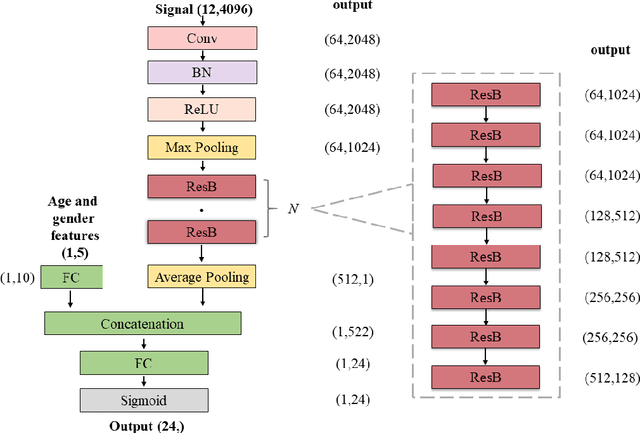

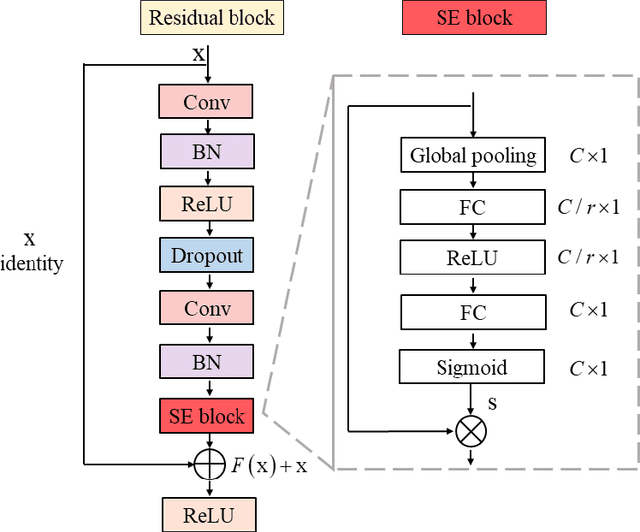
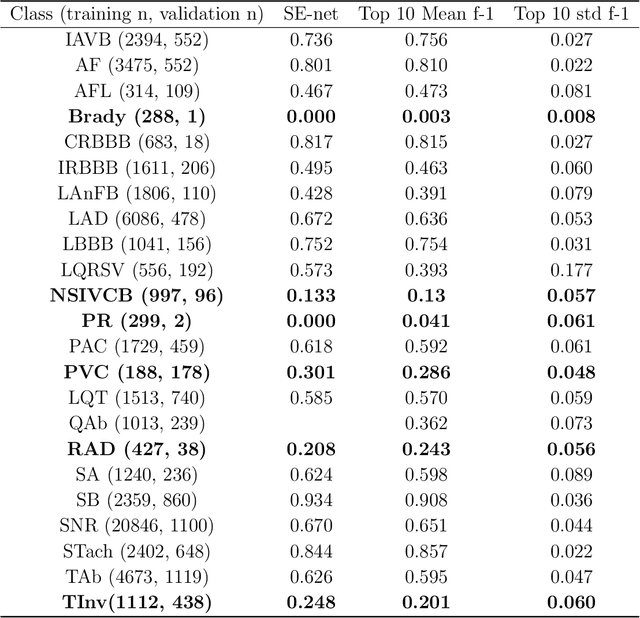
Background: Twelve lead ECGs are a core diagnostic tool for cardiovascular diseases. Here, we describe and analyse an ensemble deep neural network architecture to classify 24 cardiac abnormalities from 12-lead ECGs. Method: We proposed a squeeze and excite ResNet to automatically learn deep features from 12-lead ECGs, in order to identify 24 cardiac conditions. The deep features were augmented with age and gender features in the final fully connected layers. Output thresholds for each class were set using a constrained grid search. To determine why the model made incorrect predictions, two expert clinicians independently interpreted a random set of 100 misclassified ECGs concerning Left Axis Deviation. Results: Using the bespoke weighted accuracy metric, we achieved a 5-fold cross validation score of 0.684, and sensitivity and specificity of 0.758 and 0.969, respectively. We scored 0.520 on the full test data, and ranked 2nd out of 41 in the official challenge rankings. On a random set of misclassified ECGs, agreement between two clinicians and training labels was poor (clinician 1: kappa = -0.057, clinician 2: kappa = -0.159). In contrast, agreement between the clinicians was very high (kappa = 0.92). Discussion: The proposed prediction model performed well on the validation and hidden test data in comparison to models trained on the same data. We also discovered considerable inconsistency in training labels, which is likely to hinder development of more accurate models.
Deep Learning Algorithms for Rotating Machinery Intelligent Diagnosis: An Open Source Benchmark Study
Mar 06, 2020


With the development of artificial intelligence and deep learning (DL) techniques, rotating machinery intelligent diagnosis has gone through tremendous progress with verified success and the classification accuracies of many DL-based intelligent diagnosis algorithms are tending to 100\%. However, different datasets, configurations, and hyper-parameters are often recommended to be used in performance verification for different types of models, and few open source codes are made public for evaluation and comparisons. Therefore, unfair comparisons and ineffective improvement may exist in rotating machinery intelligent diagnosis, which limits the advancement of this field. To address these issues, we perform an extensive evaluation of four kinds of models with various datasets to provide a benchmark study within the same framework. In this paper, we first gather most of the publicly available datasets and give the complete benchmark study of DL-based intelligent algorithms under two data split strategies, five input formats, three normalization methods, and four augmentation methods. Second, we integrate the whole evaluation codes into a code library and release this code library to the public for better development of this field. Third, we use the specific-designed cases to point out the existing issues, including class imbalance, generalization ability, interpretability, few-shot learning, and model selection. By these works, we release a unified code framework for comparing and testing models fairly and quickly, emphasize the importance of open source codes, provide the baseline accuracy (a lower bound) to avoid useless improvement, and discuss potential future directions in this field. The code library is available at \url{https://github.com/ZhaoZhibin/DL-based-Intelligent-Diagnosis-Benchmark}.
Unsupervised Deep Transfer Learning for Intelligent Fault Diagnosis: An Open Source and Comparative Study
Dec 28, 2019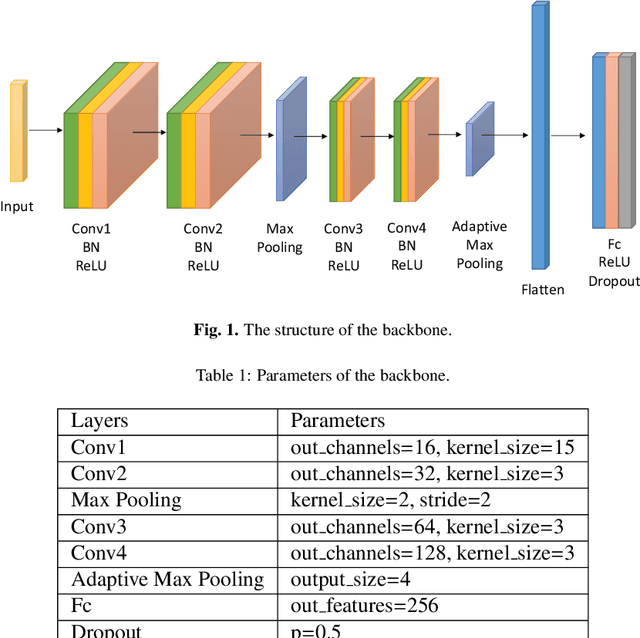
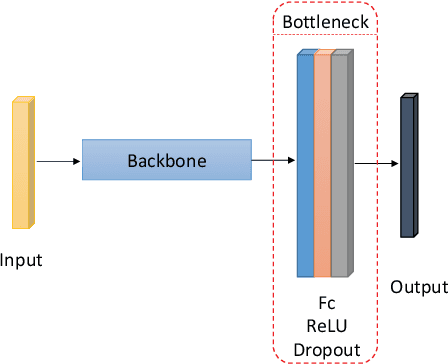
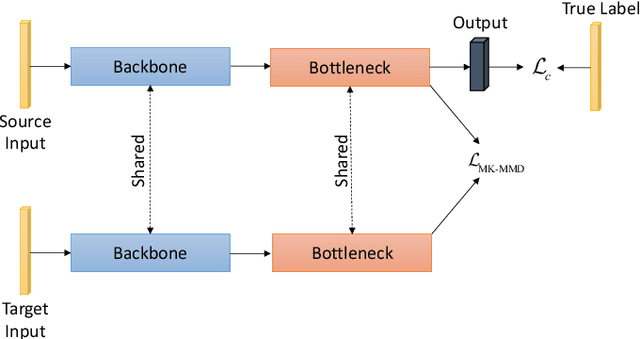
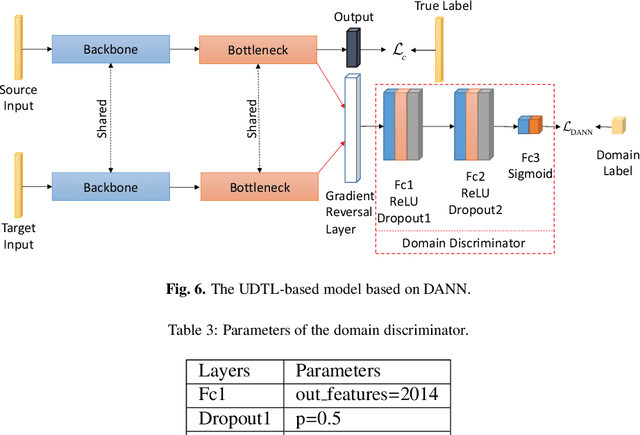
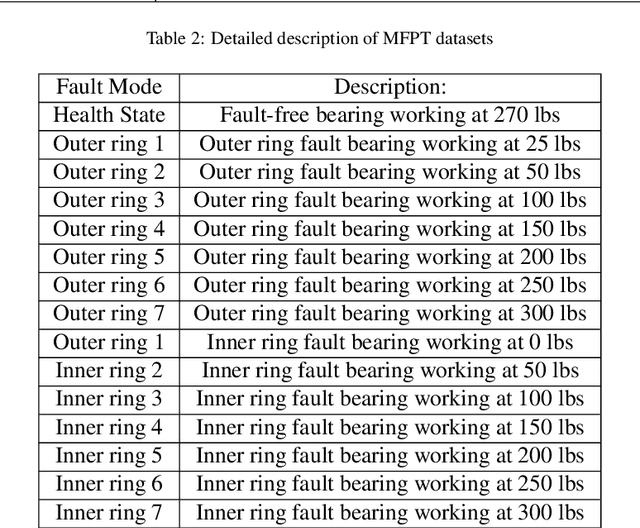
Recent progress on intelligent fault diagnosis has greatly depended on the deep learning and plenty of labeled data. However, the machine often operates with various working conditions or the target task has different distributions with the collected data used for training (we called the domain shift problem). This leads to the deep transfer learning based (DTL-based) intelligent fault diagnosis which attempts to remit this domain shift problem. Besides, the newly collected testing data are usually unlabeled, which results in the subclass DTL-based methods called unsupervised deep transfer learning based (UDTL-based) intelligent fault diagnosis. Although it has achieved huge development in the field of fault diagnosis, a standard and open source code framework and a comparative study for UDTL-based intelligent fault diagnosis are not yet established. In this paper, commonly used UDTL-based algorithms in intelligent fault diagnosis are integrated into a unified testing framework and the framework is tested on five datasets. Extensive experiments are performed to provide a systematically comparative analysis and the benchmark accuracy for more comparable and meaningful further studies. To emphasize the importance and reproducibility of UDTL-based intelligent fault diagnosis, the testing framework with source codes will be released to the research community to facilitate future research. Finally, comparative analysis of results also reveals some open and essential issues in DTL for intelligent fault diagnosis which are rarely studied including transferability of features, influence of backbones, negative transfer, and physical priors. In summary, the released framework and comparative study can serve as an extended interface and the benchmark results to carry out new studies on UDTL-based intelligent fault diagnosis. The code framework is available at https://github.com/ZhaoZhibin/UDTL.
WaveletKernelNet: An Interpretable Deep Neural Network for Industrial Intelligent Diagnosis
Nov 23, 2019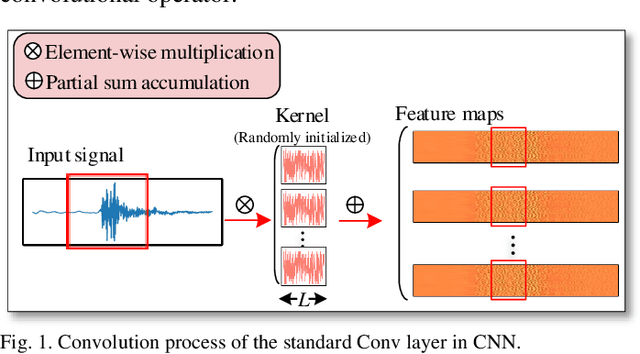

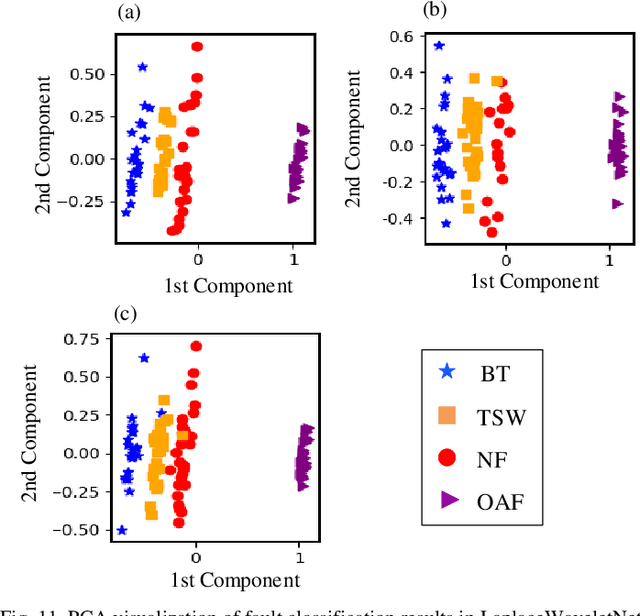
Convolutional neural network (CNN), with ability of feature learning and nonlinear mapping, has demonstrated its effectiveness in prognostics and health management (PHM). However, explanation on the physical meaning of a CNN architecture has rarely been studied. In this paper, a novel wavelet driven deep neural network termed as WaveletKernelNet (WKN) is presented, where a continuous wavelet convolutional (CWConv) layer is designed to replace the first convolutional layer of the standard CNN. This enables the first CWConv layer to discover more meaningful filters. Furthermore, only the scale parameter and translation parameter are directly learned from raw data at this CWConv layer. This provides a very effective way to obtain a customized filter bank, specifically tuned for extracting defect-related impact component embedded in the vibration signal. In addition, three experimental verification using data from laboratory environment are carried out to verify effectiveness of the proposed method for mechanical fault diagnosis. The results show the importance of the designed CWConv layer and the output of CWConv layer is interpretable. Besides, it is found that WKN has fewer parameters, higher fault classification accuracy and faster convergence speed than standard CNN.