 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeSy-Edge: Neuro-Symbolic Trustworthy Self-Healing in the Computing Continuum
Mar 22, 2026The computational demands of modern AI services are increasingly shifting execution beyond centralized clouds toward a computing continuum spanning edge and end devices. However, the scale, heterogeneity, and cross-layer dependencies of these environments make resilience difficult to maintain. Existing fault-management methods are often too static, fragmented, or heavy to support timely self-healing, especially under noisy logs and edge resource constraints. To address these limitations, this paper presents NeSy-Edge, a neuro-symbolic framework for trustworthy self-healing in the computing continuum. The framework follows an edge-first design, where a resource-constrained edge node performs local perception and reasoning, while a cloud model is invoked only at the final diagnosis stage. Specifically, NeSy-Edge converts raw runtime logs into structured event representations, builds a prior-constrained sparse symbolic causal graph, and integrates causal evidence with historical troubleshooting knowledge for root-cause analysis and recovery recommendation. We evaluate our work on representative Loghub datasets under multiple levels of semantic noise, considering parsing quality, causal reasoning, end-to-end diagnosis, and edge-side resource usage. The results show that NeSy-Edge remains robust even at the highest noise level, achieving up to 75% root-cause analysis accuracy and 65% end-to-end accuracy while operating within about 1500 MB of local memory.
Bio-inspired Agentic Self-healing Framework for Resilient Distributed Computing Continuum Systems
Jan 01, 2026Human biological systems sustain life through extraordinary resilience, continually detecting damage, orchestrating targeted responses, and restoring function through self-healing. Inspired by these capabilities, this paper introduces ReCiSt, a bio-inspired agentic self-healing framework designed to achieve resilience in Distributed Computing Continuum Systems (DCCS). Modern DCCS integrate heterogeneous computing resources, ranging from resource-constrained IoT devices to high-performance cloud infrastructures, and their inherent complexity, mobility, and dynamic operating conditions expose them to frequent faults that disrupt service continuity. These challenges underscore the need for scalable, adaptive, and self-regulated resilience strategies. ReCiSt reconstructs the biological phases of Hemostasis, Inflammation, Proliferation, and Remodeling into the computational layers Containment, Diagnosis, Meta-Cognitive, and Knowledge for DCCS. These four layers perform autonomous fault isolation, causal diagnosis, adaptive recovery, and long-term knowledge consolidation through Language Model (LM)-powered agents. These agents interpret heterogeneous logs, infer root causes, refine reasoning pathways, and reconfigure resources with minimal human intervention. The proposed ReCiSt framework is evaluated on public fault datasets using multiple LMs, and no baseline comparison is included due to the scarcity of similar approaches. Nevertheless, our results, evaluated under different LMs, confirm ReCiSt's self-healing capabilities within tens of seconds with minimum of 10% of agent CPU usage. Our results also demonstrated depth of analysis to over come uncertainties and amount of micro-agents invoked to achieve resilience.
Optimizing Multi-DNN Inference on Mobile Devices through Heterogeneous Processor Co-Execution
Mar 27, 2025Deep Neural Networks (DNNs) are increasingly deployed across diverse industries, driving demand for mobile device support. However, existing mobile inference frameworks often rely on a single processor per model, limiting hardware utilization and causing suboptimal performance and energy efficiency. Expanding DNN accessibility on mobile platforms requires adaptive, resource-efficient solutions to meet rising computational needs without compromising functionality. Parallel inference of multiple DNNs on heterogeneous processors remains challenging. Some works partition DNN operations into subgraphs for parallel execution across processors, but these often create excessive subgraphs based only on hardware compatibility, increasing scheduling complexity and memory overhead. To address this, we propose an Advanced Multi-DNN Model Scheduling (ADMS) strategy for optimizing multi-DNN inference on mobile heterogeneous processors. ADMS constructs an optimal subgraph partitioning strategy offline, balancing hardware operation support and scheduling granularity, and uses a processor-state-aware algorithm to dynamically adjust workloads based on real-time conditions. This ensures efficient workload distribution and maximizes processor utilization. Experiments show ADMS reduces multi-DNN inference latency by 4.04 times compared to vanilla frameworks.
Optimizing Long-tailed Link Prediction in Graph Neural Networks through Structure Representation Enhancement
Jul 30, 2024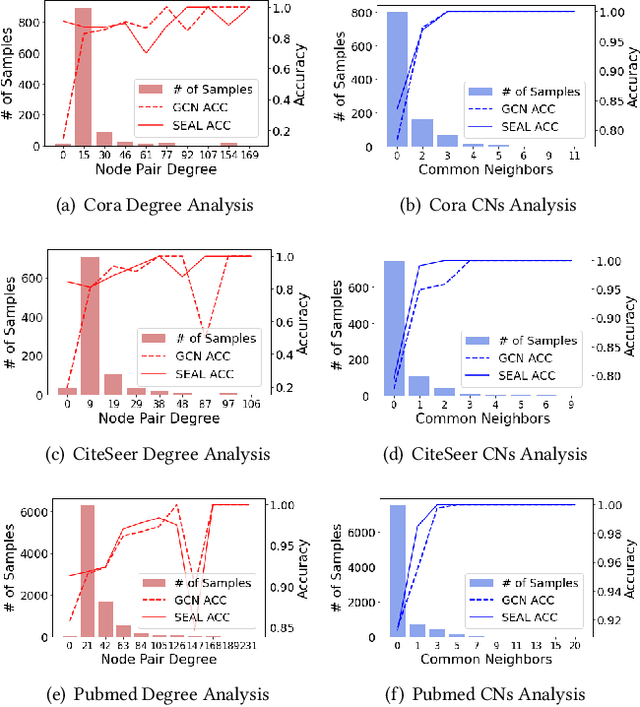
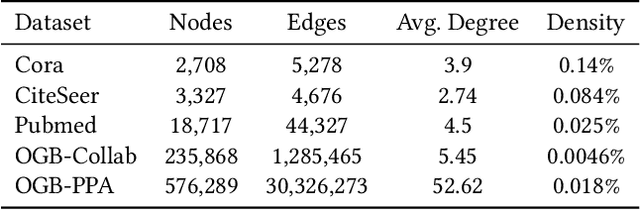
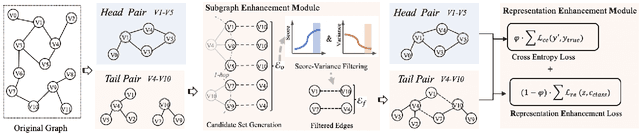
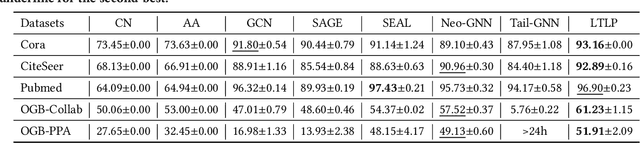
Link prediction, as a fundamental task for graph neural networks (GNNs), has boasted significant progress in varied domains. Its success is typically influenced by the expressive power of node representation, but recent developments reveal the inferior performance of low-degree nodes owing to their sparse neighbor connections, known as the degree-based long-tailed problem. Will the degree-based long-tailed distribution similarly constrain the efficacy of GNNs on link prediction? Unexpectedly, our study reveals that only a mild correlation exists between node degree and predictive accuracy, and more importantly, the number of common neighbors between node pairs exhibits a strong correlation with accuracy. Considering node pairs with less common neighbors, i.e., tail node pairs, make up a substantial fraction of the dataset but achieve worse performance, we propose that link prediction also faces the long-tailed problem. Therefore, link prediction of GNNs is greatly hindered by the tail node pairs. After knowing the weakness of link prediction, a natural question is how can we eliminate the negative effects of the skewed long-tailed distribution on common neighbors so as to improve the performance of link prediction? Towards this end, we introduce our long-tailed framework (LTLP), which is designed to enhance the performance of tail node pairs on link prediction by increasing common neighbors. Two key modules in LTLP respectively supplement high-quality edges for tail node pairs and enforce representational alignment between head and tail node pairs within the same category, thereby improving the performance of tail node pairs.
FOOL: Addressing the Downlink Bottleneck in Satellite Computing with Neural Feature Compression
Mar 25, 2024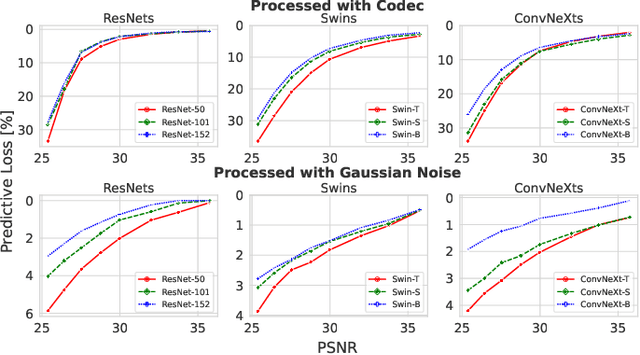
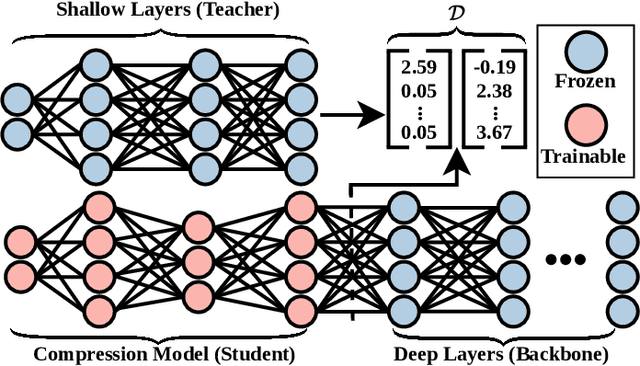
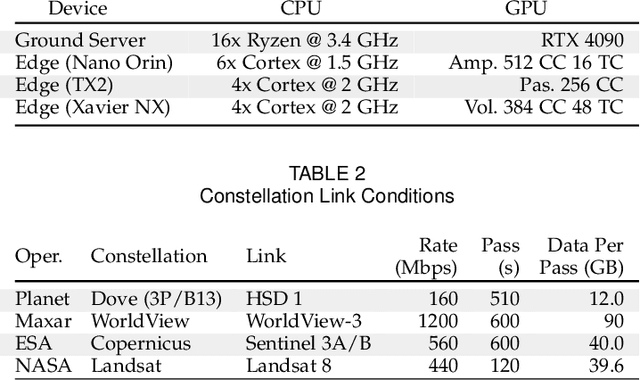
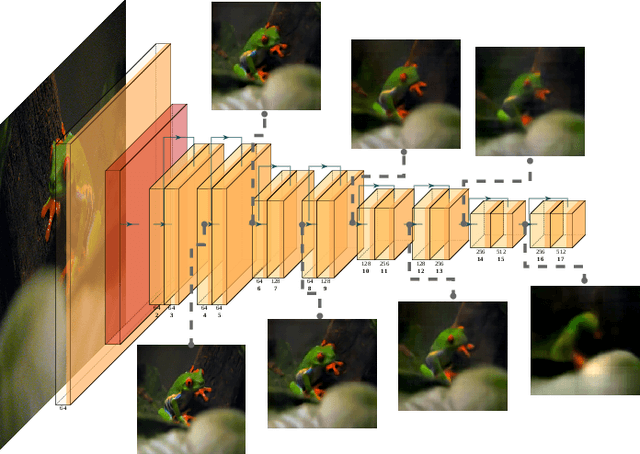
Nanosatellite constellations equipped with sensors capturing large geographic regions provide unprecedented opportunities for Earth observation. As constellation sizes increase, network contention poses a downlink bottleneck. Orbital Edge Computing (OEC) leverages limited onboard compute resources to reduce transfer costs by processing the raw captures at the source. However, current solutions have limited practicability due to reliance on crude filtering methods or over-prioritizing particular downstream tasks. This work presents FOOL, an OEC-native and task-agnostic feature compression method that preserves prediction performance. FOOL partitions high-resolution satellite imagery to maximize throughput. Further, it embeds context and leverages inter-tile dependencies to lower transfer costs with negligible overhead. While FOOL is a feature compressor, it can recover images with competitive scores on perceptual quality measures at lower bitrates. We extensively evaluate transfer cost reduction by including the peculiarity of intermittently available network connections in low earth orbit. Lastly, we test the feasibility of our system for standardized nanosatellite form factors. We demonstrate that FOOL permits downlinking over 100x the data volume without relying on prior information on the downstream tasks.
A Survey of Resource-efficient LLM and Multimodal Foundation Models
Jan 16, 2024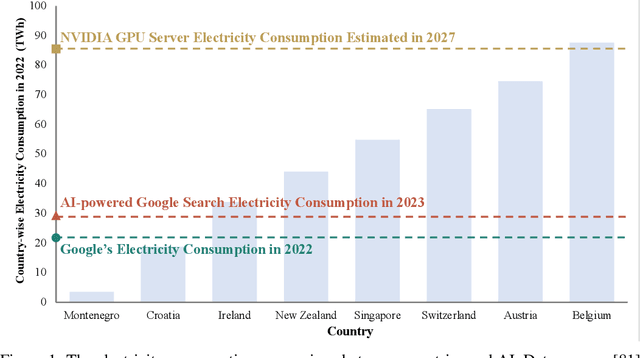
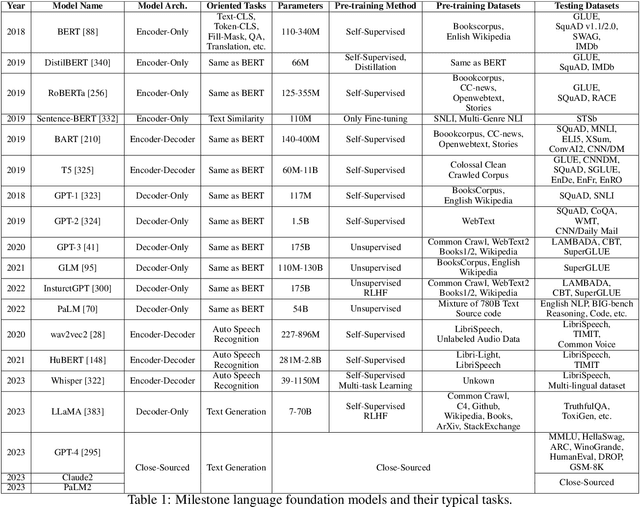
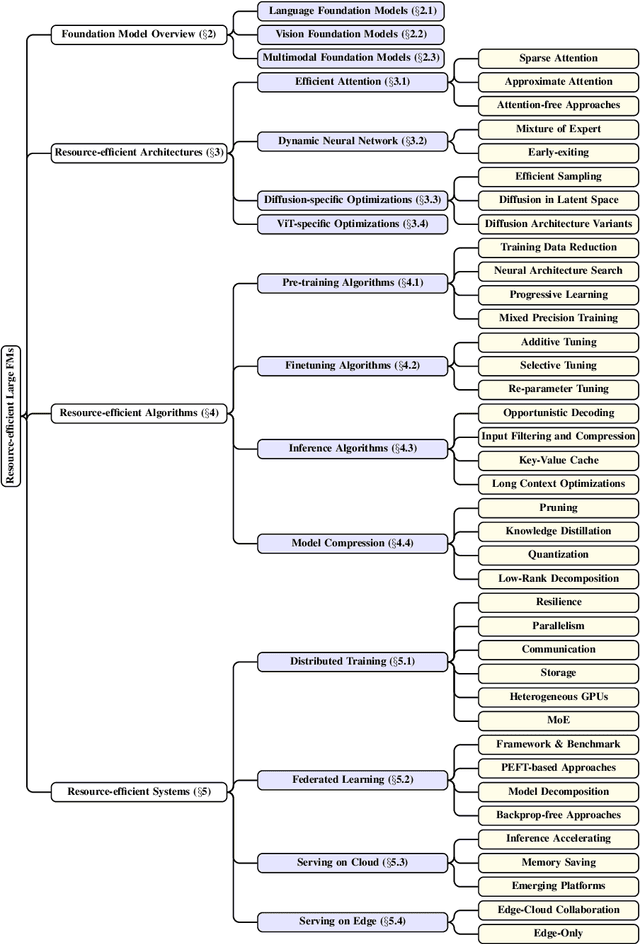
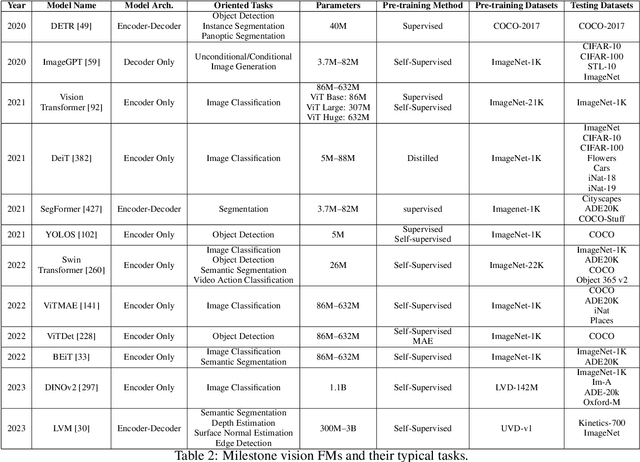
Large foundation models, including large language models (LLMs), vision transformers (ViTs), diffusion, and LLM-based multimodal models, are revolutionizing the entire machine learning lifecycle, from training to deployment. However, the substantial advancements in versatility and performance these models offer come at a significant cost in terms of hardware resources. To support the growth of these large models in a scalable and environmentally sustainable way, there has been a considerable focus on developing resource-efficient strategies. This survey delves into the critical importance of such research, examining both algorithmic and systemic aspects. It offers a comprehensive analysis and valuable insights gleaned from existing literature, encompassing a broad array of topics from cutting-edge model architectures and training/serving algorithms to practical system designs and implementations. The goal of this survey is to provide an overarching understanding of how current approaches are tackling the resource challenges posed by large foundation models and to potentially inspire future breakthroughs in this field.
Not All Negatives Are Worth Attending to: Meta-Bootstrapping Negative Sampling Framework for Link Prediction
Dec 12, 2023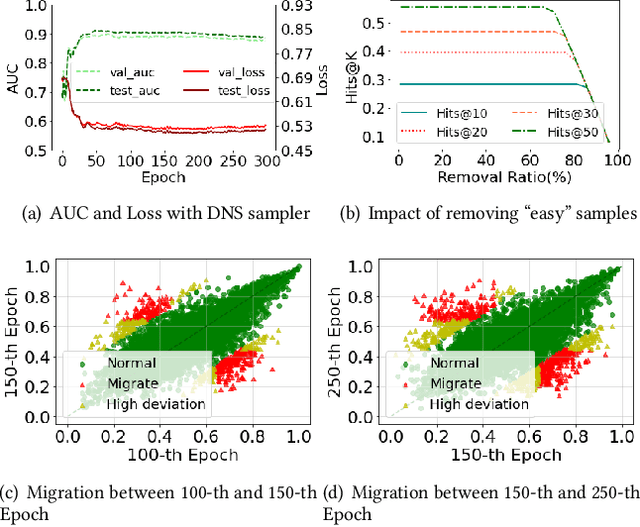
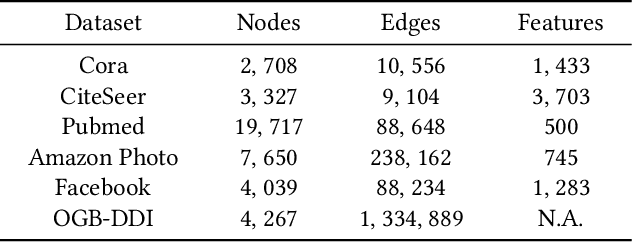
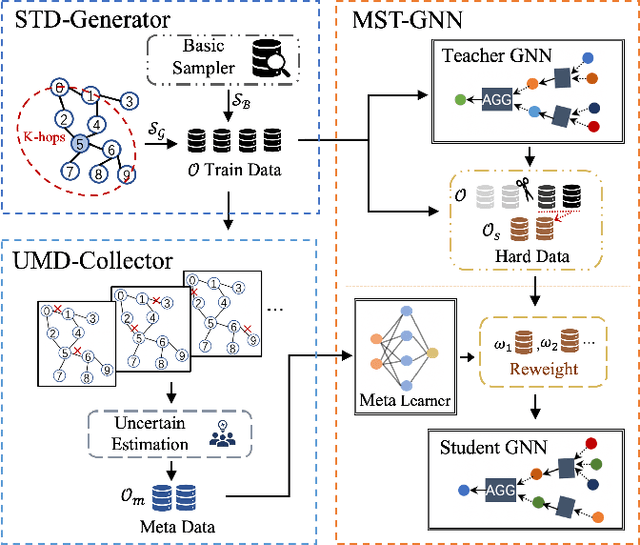
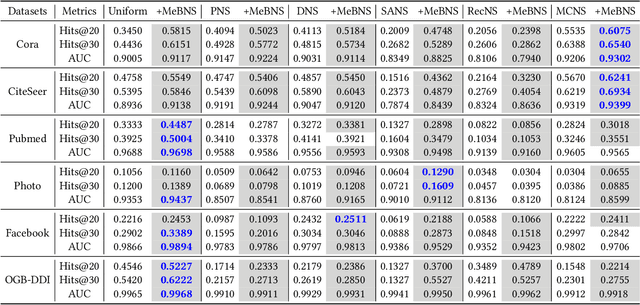
The rapid development of graph neural networks (GNNs) encourages the rising of link prediction, achieving promising performance with various applications. Unfortunately, through a comprehensive analysis, we surprisingly find that current link predictors with dynamic negative samplers (DNSs) suffer from the migration phenomenon between "easy" and "hard" samples, which goes against the preference of DNS of choosing "hard" negatives, thus severely hindering capability. Towards this end, we propose the MeBNS framework, serving as a general plugin that can potentially improve current negative sampling based link predictors. In particular, we elaborately devise a Meta-learning Supported Teacher-student GNN (MST-GNN) that is not only built upon teacher-student architecture for alleviating the migration between "easy" and "hard" samples but also equipped with a meta learning based sample re-weighting module for helping the student GNN distinguish "hard" samples in a fine-grained manner. To effectively guide the learning of MST-GNN, we prepare a Structure enhanced Training Data Generator (STD-Generator) and an Uncertainty based Meta Data Collector (UMD-Collector) for supporting the teacher and student GNN, respectively. Extensive experiments show that the MeBNS achieves remarkable performance across six link prediction benchmark datasets.
A Comprehensive Benchmark of Deep Learning Libraries on Mobile Devices
Feb 14, 2022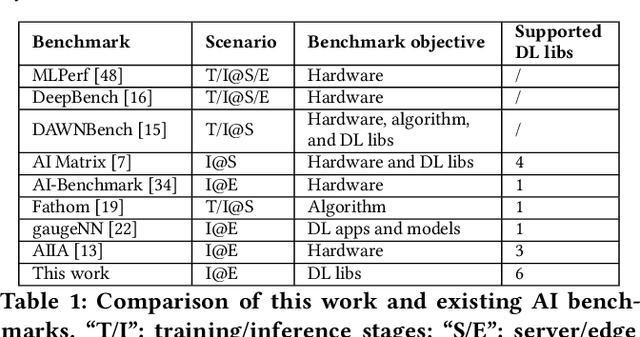
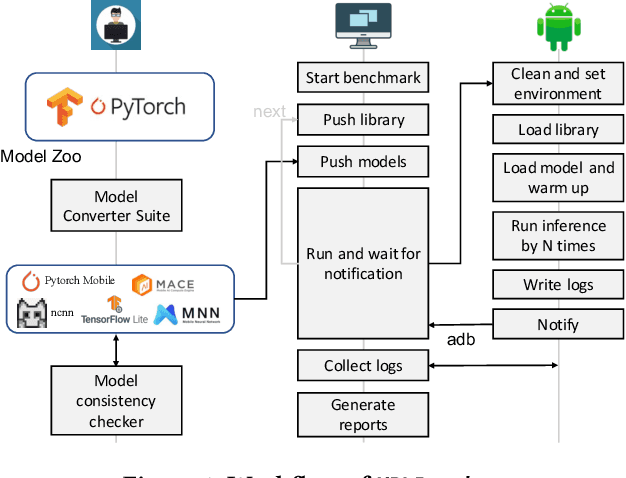
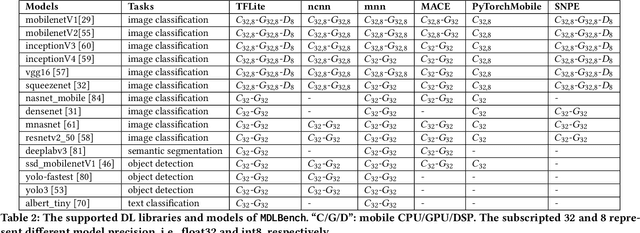
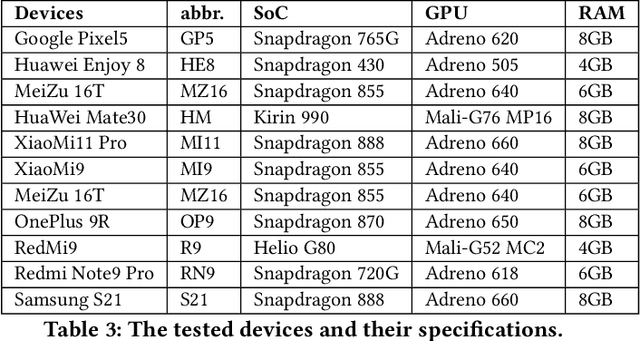
Deploying deep learning (DL) on mobile devices has been a notable trend in recent years. To support fast inference of on-device DL, DL libraries play a critical role as algorithms and hardware do. Unfortunately, no prior work ever dives deep into the ecosystem of modern DL libs and provides quantitative results on their performance. In this paper, we first build a comprehensive benchmark that includes 6 representative DL libs and 15 diversified DL models. We then perform extensive experiments on 10 mobile devices, which help reveal a complete landscape of the current mobile DL libs ecosystem. For example, we find that the best-performing DL lib is severely fragmented across different models and hardware, and the gap between those DL libs can be rather huge. In fact, the impacts of DL libs can overwhelm the optimizations from algorithms or hardware, e.g., model quantization and GPU/DSP-based heterogeneous computing. Finally, atop the observations, we summarize practical implications to different roles in the DL lib ecosystem.
Paperfetcher: A tool to automate handsearch for systematic reviews
Oct 27, 2021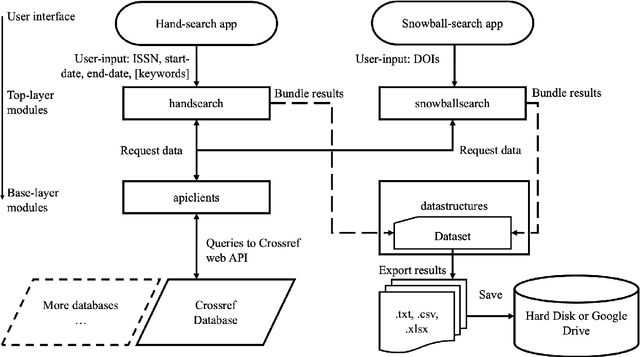
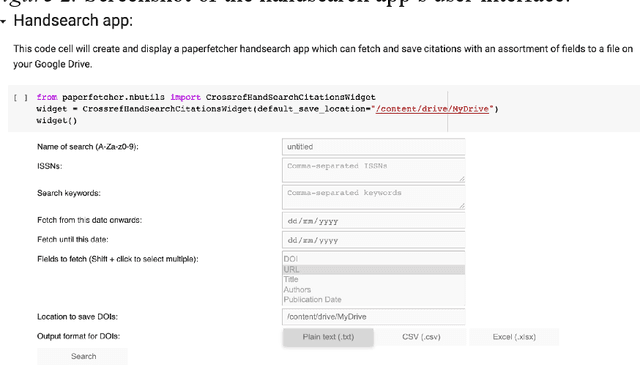
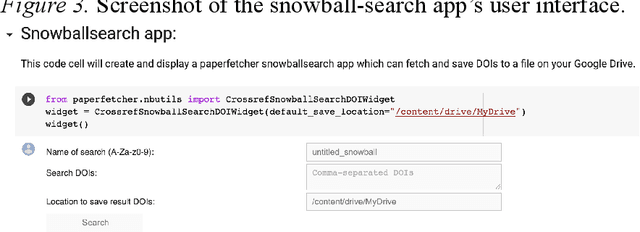
This paper presents a browser-based software tool, Paperfetcher, to automate the handsearch portion of systematic reviews. Paperfetcher has two parts: an extensible back-end framework written in Python, which does all the heavy lifting, and a set of easy-to-use front-end apps for researchers. The front-end apps can be run online, with no setup, on a cloud platform. Privacy-conscious users can run the app on their computers after a few steps of installation, and advanced users can modify the source code and extend the back-end interface for their own specific needs. Paperfetcher's website has user guidelines and a step-by-step setup video to coach researchers to use the software. With Paperfetcher's assistance, researchers can retrieve articles from designated journals and a given timeframe with just a few clicks. Researchers can also restrict their search to papers matching a set of keywords. In addition, Paperfetcher automates snowball-search, which retrieves all references from selected articles. Paperfetcher helps save a considerable amount of time and energy in the literature search portion of systematic reviews.
Unsupervised Deep Transfer Learning for Intelligent Fault Diagnosis: An Open Source and Comparative Study
Dec 28, 2019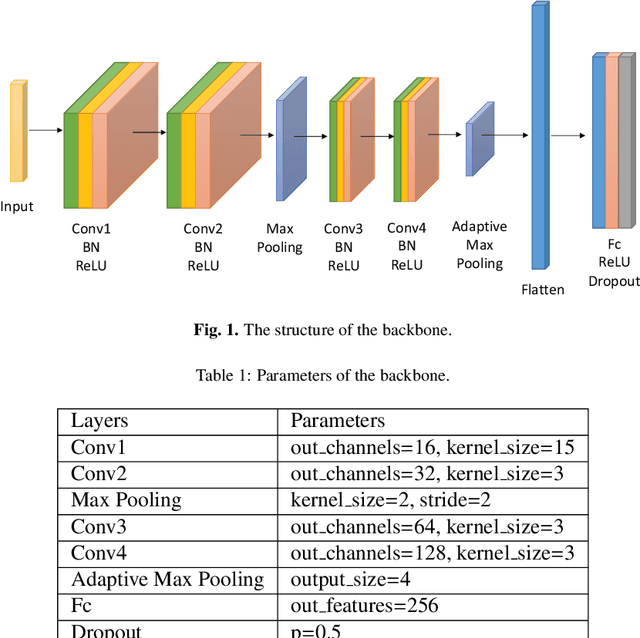
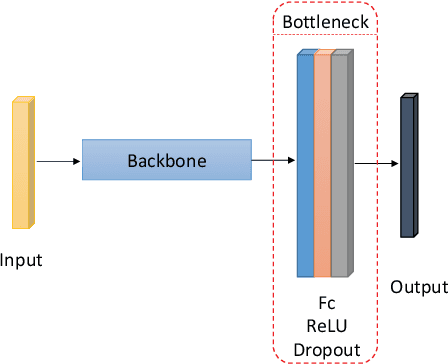
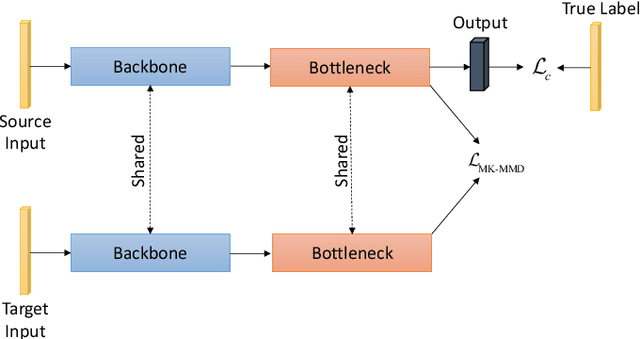
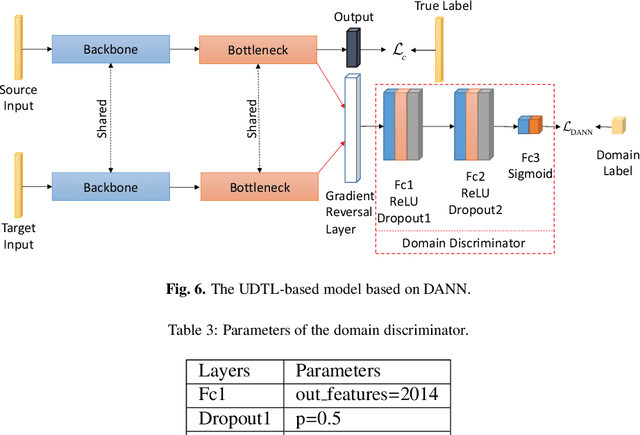
Recent progress on intelligent fault diagnosis has greatly depended on the deep learning and plenty of labeled data. However, the machine often operates with various working conditions or the target task has different distributions with the collected data used for training (we called the domain shift problem). This leads to the deep transfer learning based (DTL-based) intelligent fault diagnosis which attempts to remit this domain shift problem. Besides, the newly collected testing data are usually unlabeled, which results in the subclass DTL-based methods called unsupervised deep transfer learning based (UDTL-based) intelligent fault diagnosis. Although it has achieved huge development in the field of fault diagnosis, a standard and open source code framework and a comparative study for UDTL-based intelligent fault diagnosis are not yet established. In this paper, commonly used UDTL-based algorithms in intelligent fault diagnosis are integrated into a unified testing framework and the framework is tested on five datasets. Extensive experiments are performed to provide a systematically comparative analysis and the benchmark accuracy for more comparable and meaningful further studies. To emphasize the importance and reproducibility of UDTL-based intelligent fault diagnosis, the testing framework with source codes will be released to the research community to facilitate future research. Finally, comparative analysis of results also reveals some open and essential issues in DTL for intelligent fault diagnosis which are rarely studied including transferability of features, influence of backbones, negative transfer, and physical priors. In summary, the released framework and comparative study can serve as an extended interface and the benchmark results to carry out new studies on UDTL-based intelligent fault diagnosis. The code framework is available at https://github.com/ZhaoZhibin/UDTL.