 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Dimensional Autoscaling of Stream Processing Services on Edge Devices
Oct 08, 2025
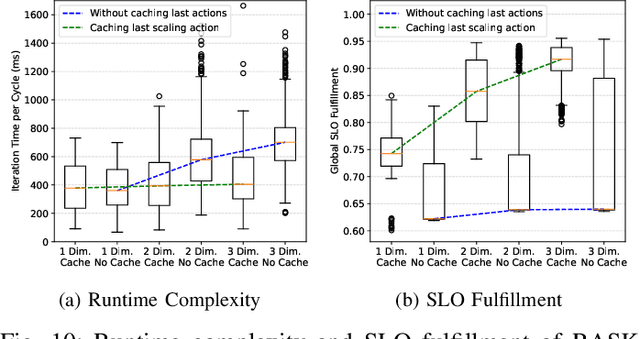
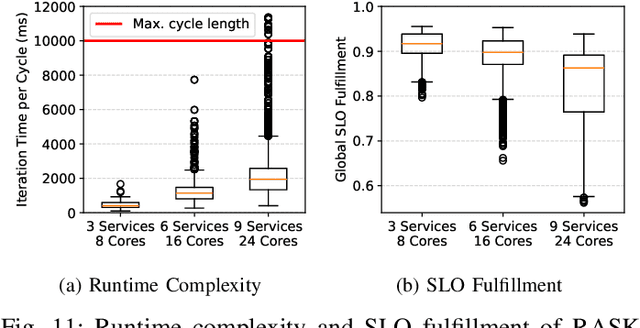

Edge devices have limited resources, which inevitably leads to situations where stream processing services cannot satisfy their needs. While existing autoscaling mechanisms focus entirely on resource scaling, Edge devices require alternative ways to sustain the Service Level Objectives (SLOs) of competing services. To address these issues, we introduce a Multi-dimensional Autoscaling Platform (MUDAP) that supports fine-grained vertical scaling across both service- and resource-level dimensions. MUDAP supports service-specific scaling tailored to available parameters, e.g., scale data quality or model size for a particular service. To optimize the execution across services, we present a scaling agent based on Regression Analysis of Structural Knowledge (RASK). The RASK agent efficiently explores the solution space and learns a continuous regression model of the processing environment for inferring optimal scaling actions. We compared our approach with two autoscalers, the Kubernetes VPA and a reinforcement learning agent, for scaling up to 9 services on a single Edge device. Our results showed that RASK can infer an accurate regression model in merely 20 iterations (i.e., observe 200s of processing). By increasingly adding elasticity dimensions, RASK sustained the highest request load with 28% less SLO violations, compared to baselines.
Leveraging Neural Graph Compilers in Machine Learning Research for Edge-Cloud Systems
Apr 28, 2025This work presents a comprehensive evaluation of neural network graph compilers across heterogeneous hardware platforms, addressing the critical gap between theoretical optimization techniques and practical deployment scenarios. We demonstrate how vendor-specific optimizations can invalidate relative performance comparisons between architectural archetypes, with performance advantages sometimes completely reversing after compilation. Our systematic analysis reveals that graph compilers exhibit performance patterns highly dependent on both neural architecture and batch sizes. Through fine-grained block-level experimentation, we establish that vendor-specific compilers can leverage repeated patterns in simple architectures, yielding disproportionate throughput gains as model depth increases. We introduce novel metrics to quantify a compiler's ability to mitigate performance friction as batch size increases. Our methodology bridges the gap between academic research and practical deployment by incorporating compiler effects throughout the research process, providing actionable insights for practitioners navigating complex optimization landscapes across heterogeneous hardware environments.
FOOL: Addressing the Downlink Bottleneck in Satellite Computing with Neural Feature Compression
Mar 25, 2024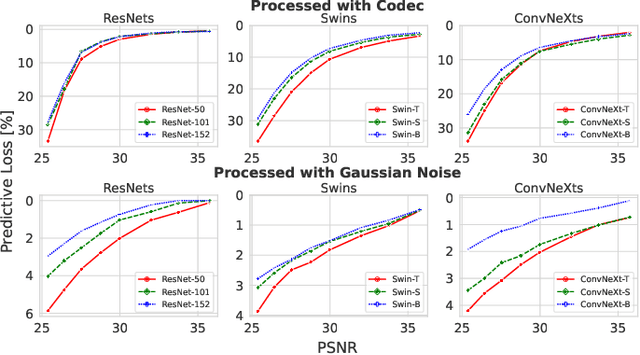
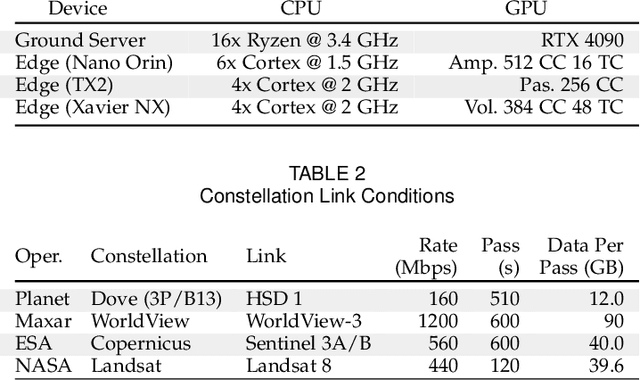
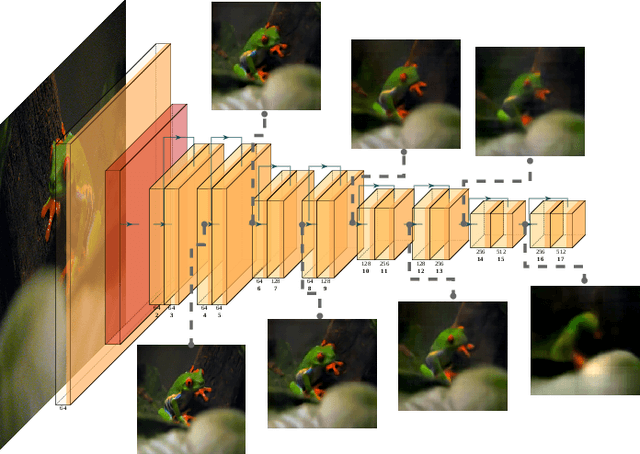
Nanosatellite constellations equipped with sensors capturing large geographic regions provide unprecedented opportunities for Earth observation. As constellation sizes increase, network contention poses a downlink bottleneck. Orbital Edge Computing (OEC) leverages limited onboard compute resources to reduce transfer costs by processing the raw captures at the source. However, current solutions have limited practicability due to reliance on crude filtering methods or over-prioritizing particular downstream tasks. This work presents FOOL, an OEC-native and task-agnostic feature compression method that preserves prediction performance. FOOL partitions high-resolution satellite imagery to maximize throughput. Further, it embeds context and leverages inter-tile dependencies to lower transfer costs with negligible overhead. While FOOL is a feature compressor, it can recover images with competitive scores on perceptual quality measures at lower bitrates. We extensively evaluate transfer cost reduction by including the peculiarity of intermittently available network connections in low earth orbit. Lastly, we test the feasibility of our system for standardized nanosatellite form factors. We demonstrate that FOOL permits downlinking over 100x the data volume without relying on prior information on the downstream tasks.
Architectural Vision for Quantum Computing in the Edge-Cloud Continuum
May 09, 2023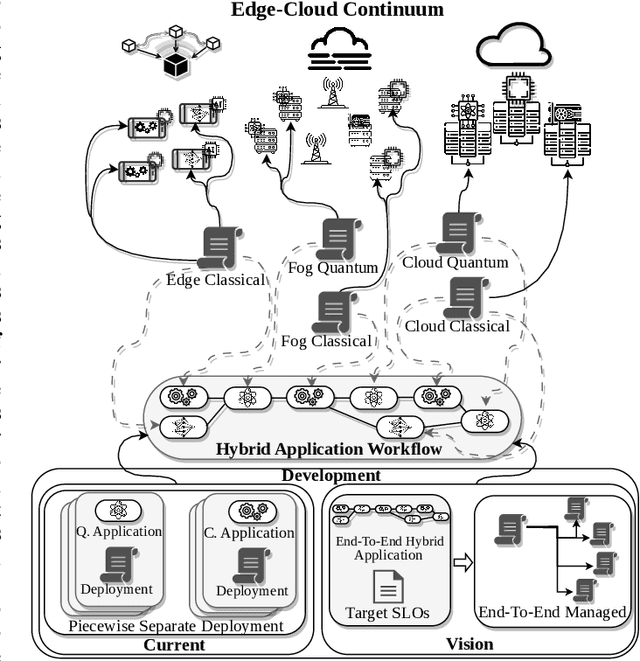
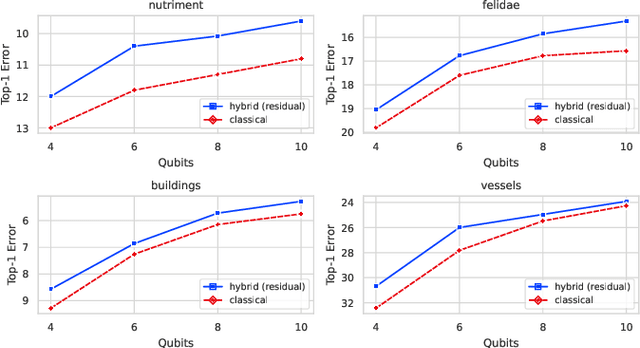
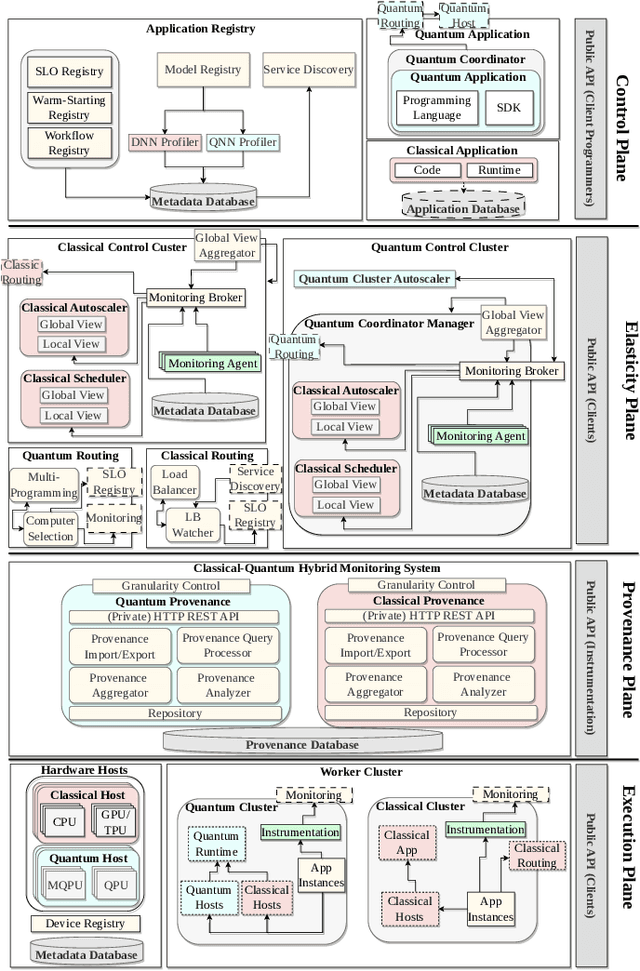
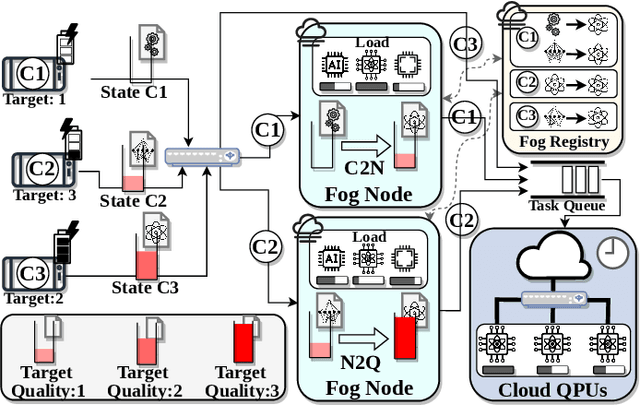
Quantum processing units (QPUs) are currently exclusively available from cloud vendors. However, with recent advancements, hosting QPUs is soon possible everywhere. Existing work has yet to draw from research in edge computing to explore systems exploiting mobile QPUs, or how hybrid applications can benefit from distributed heterogeneous resources. Hence, this work presents an architecture for Quantum Computing in the edge-cloud continuum. We discuss the necessity, challenges, and solution approaches for extending existing work on classical edge computing to integrate QPUs. We describe how warm-starting allows defining workflows that exploit the hierarchical resources spread across the continuum. Then, we introduce a distributed inference engine with hybrid classical-quantum neural networks (QNNs) to aid system designers in accommodating applications with complex requirements that incur the highest degree of heterogeneity. We propose solutions focusing on classical layer partitioning and quantum circuit cutting to demonstrate the potential of utilizing classical and quantum computation across the continuum. To evaluate the importance and feasibility of our vision, we provide a proof of concept that exemplifies how extending a classical partition method to integrate quantum circuits can improve the solution quality. Specifically, we implement a split neural network with optional hybrid QNN predictors. Our results show that extending classical methods with QNNs is viable and promising for future work.
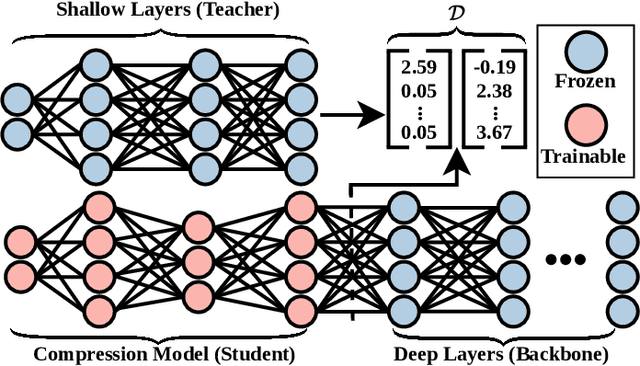
FrankenSplit: Saliency Guided Neural Feature Compression with Shallow Variational Bottleneck Injection
Feb 21, 2023Lightweight neural networks exchange fast inference for predictive strength. Conversely, large deep neural networks have low prediction error but incur prolonged inference times and high energy consumption on resource-constrained devices. This trade-off is unacceptable for latency-sensitive and performance-critical applications. Offloading inference tasks to a server is unsatisfactory due to the inevitable network congestion by high-dimensional data competing for limited bandwidth and leaving valuable client-side resources idle. This work demonstrates why existing methods cannot adequately address the need for high-performance inference in mobile edge computing. Then, we show how to overcome current limitations by introducing a novel training method to reduce bandwidth consumption in Machine-to-Machine communication and a generalizable design heuristic for resource-conscious compression models. We extensively evaluate our proposed method against a wide range of baselines for latency and compressive strength in an environment with asymmetric resource distribution between edge devices and servers. Despite our edge-oriented lightweight encoder, our method achieves considerably better compression rates.