 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGroupNL: Low-Resource and Robust CNN Design over Cloud and Device
Jun 14, 2025It has become mainstream to deploy Convolutional Neural Network (CNN) models on ubiquitous Internet of Things (IoT) devices with the help of the cloud to provide users with a variety of high-quality services. Most existing methods have two limitations: (i) low robustness in handling corrupted image data collected by IoT devices; and (ii) high consumption of computational and transmission resources. To this end, we propose the Grouped NonLinear transformation generation method (GroupNL), which generates diversified feature maps by utilizing data-agnostic Nonlinear Transformation Functions (NLFs) to improve the robustness of the CNN model. Specifically, partial convolution filters are designated as seed filters in a convolutional layer, and a small set of feature maps, i.e., seed feature maps, are first generated based on vanilla convolution operation. Then, we split seed feature maps into several groups, each with a set of different NLFs, to generate corresponding diverse feature maps with in-place nonlinear processing. Moreover, GroupNL effectively reduces the parameter transmission between multiple nodes during model training by setting the hyperparameters of NLFs to random initialization and not updating them during model training, and reduces the computing resources by using NLFs to generate feature maps instead of most feature maps generated based on sliding windows. Experimental results on CIFAR-10, GTSRB, CIFAR-10-C, Icons50, and ImageNet-1K datasets in NVIDIA RTX GPU platforms show that the proposed GroupNL outperforms other state-of-the-art methods in model robust and training acceleration. Specifically, on the Icons-50 dataset, the accuracy of GroupNL-ResNet-18 achieves approximately 2.86% higher than the vanilla ResNet-18. GroupNL improves training speed by about 53% compared to vanilla CNN when trained on a cluster of 8 NVIDIA RTX 4090 GPUs on the ImageNet-1K dataset.
MrM: Black-Box Membership Inference Attacks against Multimodal RAG Systems
Jun 09, 2025



Multimodal retrieval-augmented generation (RAG) systems enhance large vision-language models by integrating cross-modal knowledge, enabling their increasing adoption across real-world multimodal tasks. These knowledge databases may contain sensitive information that requires privacy protection. However, multimodal RAG systems inherently grant external users indirect access to such data, making them potentially vulnerable to privacy attacks, particularly membership inference attacks (MIAs). % Existing MIA methods targeting RAG systems predominantly focus on the textual modality, while the visual modality remains relatively underexplored. To bridge this gap, we propose MrM, the first black-box MIA framework targeted at multimodal RAG systems. It utilizes a multi-object data perturbation framework constrained by counterfactual attacks, which can concurrently induce the RAG systems to retrieve the target data and generate information that leaks the membership information. Our method first employs an object-aware data perturbation method to constrain the perturbation to key semantics and ensure successful retrieval. Building on this, we design a counterfact-informed mask selection strategy to prioritize the most informative masked regions, aiming to eliminate the interference of model self-knowledge and amplify attack efficacy. Finally, we perform statistical membership inference by modeling query trials to extract features that reflect the reconstruction of masked semantics from response patterns. Experiments on two visual datasets and eight mainstream commercial visual-language models (e.g., GPT-4o, Gemini-2) demonstrate that MrM achieves consistently strong performance across both sample-level and set-level evaluations, and remains robust under adaptive defenses.
MCPWorld: A Unified Benchmarking Testbed for API, GUI, and Hybrid Computer Use Agents
Jun 09, 2025(M)LLM-powered computer use agents (CUA) are emerging as a transformative technique to automate human-computer interaction. However, existing CUA benchmarks predominantly target GUI agents, whose evaluation methods are susceptible to UI changes and ignore function interactions exposed by application APIs, e.g., Model Context Protocol (MCP). To this end, we propose MCPWorld, the first automatic CUA testbed for API, GUI, and API-GUI hybrid agents. A key principle of MCPWorld is the use of "white-box apps", i.e., those with source code availability and can be revised/re-compiled as needed (e.g., adding MCP support), with two notable advantages: (1) It greatly broadens the design space of CUA, such as what and how the app features to be exposed/extracted as CUA-callable APIs. (2) It allows MCPWorld to programmatically verify task completion by directly monitoring application behavior through techniques like dynamic code instrumentation, offering robust, accurate CUA evaluation decoupled from specific agent implementations or UI states. Currently, MCPWorld includes 201 well curated and annotated user tasks, covering diversified use cases and difficulty levels. MCPWorld is also fully containerized with GPU acceleration support for flexible adoption on different OS/hardware environments. Our preliminary experiments, using a representative LLM-powered CUA framework, achieve 75.12% task completion accuracy, simultaneously providing initial evidence on the practical effectiveness of agent automation leveraging MCP. Overall, we anticipate MCPWorld to facilitate and standardize the benchmarking of next-generation computer use agents that can leverage rich external tools. Our code and dataset are publicly available at https://github.com/SAAgent/MCPWorld.
HeteRAG: A Heterogeneous Retrieval-augmented Generation Framework with Decoupled Knowledge Representations
Apr 12, 2025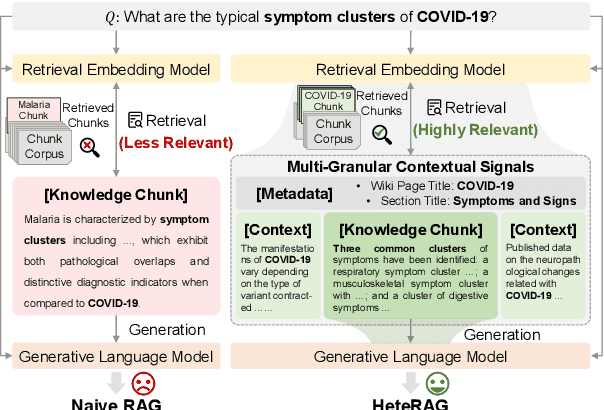

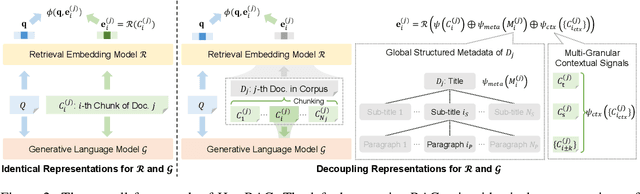

Retrieval-augmented generation (RAG) methods can enhance the performance of LLMs by incorporating retrieved knowledge chunks into the generation process. In general, the retrieval and generation steps usually have different requirements for these knowledge chunks. The retrieval step benefits from comprehensive information to improve retrieval accuracy, whereas excessively long chunks may introduce redundant contextual information, thereby diminishing both the effectiveness and efficiency of the generation process. However, existing RAG methods typically employ identical representations of knowledge chunks for both retrieval and generation, resulting in suboptimal performance. In this paper, we propose a heterogeneous RAG framework (\myname) that decouples the representations of knowledge chunks for retrieval and generation, thereby enhancing the LLMs in both effectiveness and efficiency. Specifically, we utilize short chunks to represent knowledge to adapt the generation step and utilize the corresponding chunk with its contextual information from multi-granular views to enhance retrieval accuracy. We further introduce an adaptive prompt tuning method for the retrieval model to adapt the heterogeneous retrieval augmented generation process. Extensive experiments demonstrate that \myname achieves significant improvements compared to baselines.
RLER-TTE: An Efficient and Effective Framework for En Route Travel Time Estimation with Reinforcement Learning
Jan 26, 2025



En Route Travel Time Estimation (ER-TTE) aims to learn driving patterns from traveled routes to achieve rapid and accurate real-time predictions. However, existing methods ignore the complexity and dynamism of real-world traffic systems, resulting in significant gaps in efficiency and accuracy in real-time scenarios. Addressing this issue is a critical yet challenging task. This paper proposes a novel framework that redefines the implementation path of ER-TTE to achieve highly efficient and effective predictions. Firstly, we introduce a novel pipeline consisting of a Decision Maker and a Predictor to rectify the inefficient prediction strategies of current methods. The Decision Maker performs efficient real-time decisions to determine whether the high-complexity prediction model in the Predictor needs to be invoked, and the Predictor recalculates the travel time or infers from historical prediction results based on these decisions. Next, to tackle the dynamic and uncertain real-time scenarios, we model the online decision-making problem as a Markov decision process and design an intelligent agent based on reinforcement learning for autonomous decision-making. Moreover, to fully exploit the spatio-temporal correlation between online data and offline data, we meticulously design feature representation and encoding techniques based on the attention mechanism. Finally, to improve the flawed training and evaluation strategies of existing methods, we propose an end-to-end training and evaluation approach, incorporating curriculum learning strategies to manage spatio-temporal data for more advanced training algorithms. Extensive evaluations on three real-world datasets confirm that our method significantly outperforms state-of-the-art solutions in both accuracy and efficiency.
PhoneLM:an Efficient and Capable Small Language Model Family through Principled Pre-training
Nov 07, 2024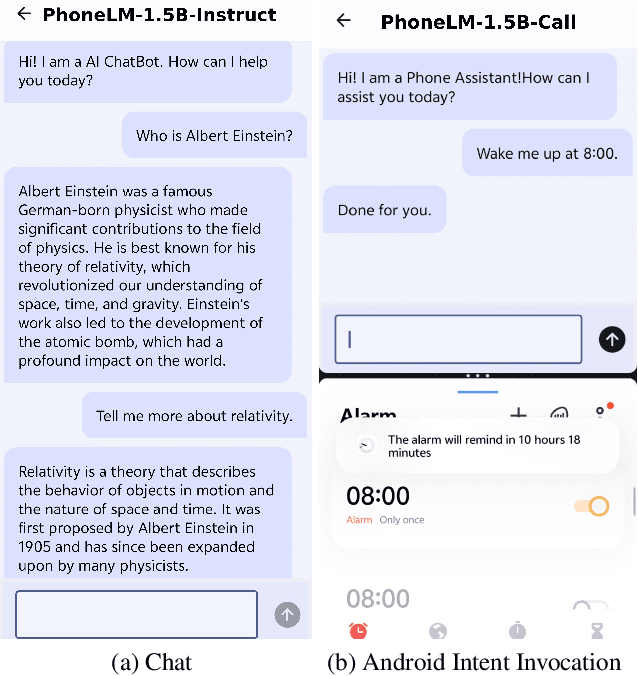
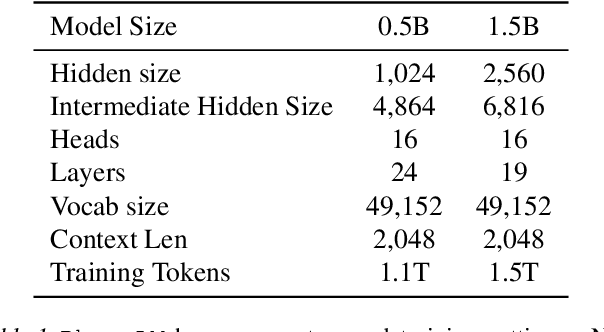
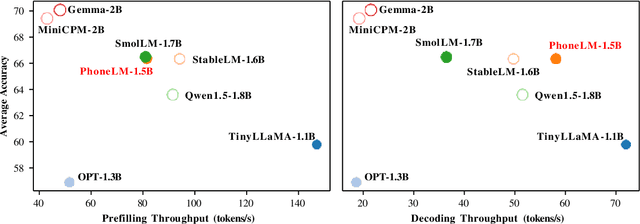

The interest in developing small language models (SLM) for on-device deployment is fast growing. However, the existing SLM design hardly considers the device hardware characteristics. Instead, this work presents a simple yet effective principle for SLM design: architecture searching for (near-)optimal runtime efficiency before pre-training. Guided by this principle, we develop PhoneLM SLM family (currently with 0.5B and 1.5B versions), that acheive the state-of-the-art capability-efficiency tradeoff among those with similar parameter size. We fully open-source the code, weights, and training datasets of PhoneLM for reproducibility and transparency, including both base and instructed versions. We also release a finetuned version of PhoneLM capable of accurate Android Intent invocation, and an end-to-end Android demo. All materials are available at https://github.com/UbiquitousLearning/PhoneLM.
FedMoE: Personalized Federated Learning via Heterogeneous Mixture of Experts
Aug 21, 2024As Large Language Models (LLMs) push the boundaries of AI capabilities, their demand for data is growing. Much of this data is private and distributed across edge devices, making Federated Learning (FL) a de-facto alternative for fine-tuning (i.e., FedLLM). However, it faces significant challenges due to the inherent heterogeneity among clients, including varying data distributions and diverse task types. Towards a versatile FedLLM, we replace traditional dense model with a sparsely-activated Mixture-of-Experts (MoE) architecture, whose parallel feed-forward networks enable greater flexibility. To make it more practical in resource-constrained environments, we present FedMoE, the efficient personalized FL framework to address data heterogeneity, constructing an optimal sub-MoE for each client and bringing the knowledge back to global MoE. FedMoE is composed of two fine-tuning stages. In the first stage, FedMoE simplifies the problem by conducting a heuristic search based on observed activation patterns, which identifies a suboptimal submodel for each client. In the second stage, these submodels are distributed to clients for further training and returned for server aggregating through a novel modular aggregation strategy. Meanwhile, FedMoE progressively adjusts the submodels to optimal through global expert recommendation. Experimental results demonstrate the superiority of our method over previous personalized FL methods.
Urban Traffic Accident Risk Prediction Revisited: Regionality, Proximity, Similarity and Sparsity
Jul 29, 2024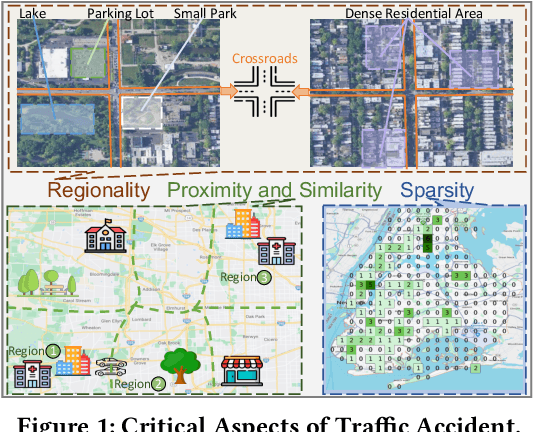
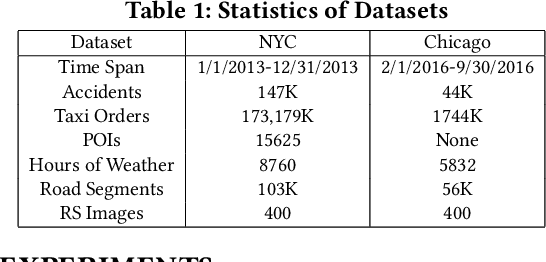
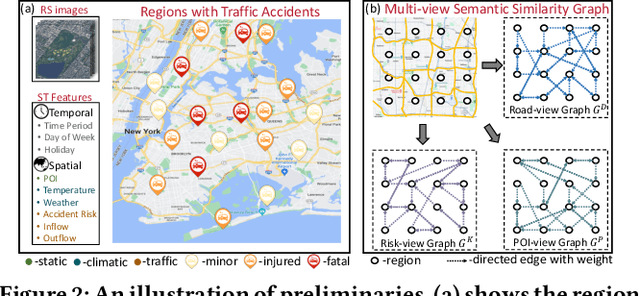
Traffic accidents pose a significant risk to human health and property safety. Therefore, to prevent traffic accidents, predicting their risks has garnered growing interest. We argue that a desired prediction solution should demonstrate resilience to the complexity of traffic accidents. In particular, it should adequately consider the regional background, accurately capture both spatial proximity and semantic similarity, and effectively address the sparsity of traffic accidents. However, these factors are often overlooked or difficult to incorporate. In this paper, we propose a novel multi-granularity hierarchical spatio-temporal network. Initially, we innovate by incorporating remote sensing data, facilitating the creation of hierarchical multi-granularity structure and the comprehension of regional background. We construct multiple high-level risk prediction tasks to enhance model's ability to cope with sparsity. Subsequently, to capture both spatial proximity and semantic similarity, region feature and multi-view graph undergo encoding processes to distill effective representations. Additionally, we propose message passing and adaptive temporal attention module that bridges different granularities and dynamically captures time correlations inherent in traffic accident patterns. At last, a multivariate hierarchical loss function is devised considering the complexity of the prediction purpose. Extensive experiments on two real datasets verify the superiority of our model against the state-of-the-art methods.
Variational Multi-Modal Hypergraph Attention Network for Multi-Modal Relation Extraction
Apr 18, 2024
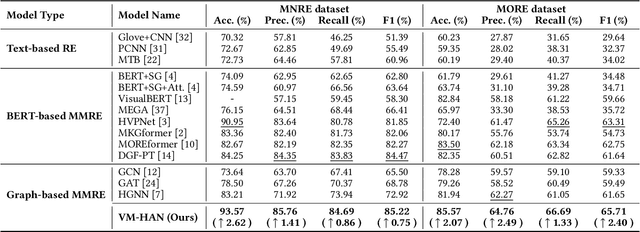
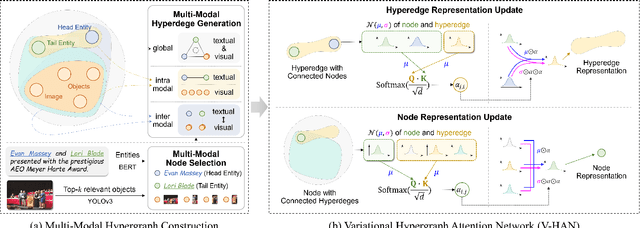
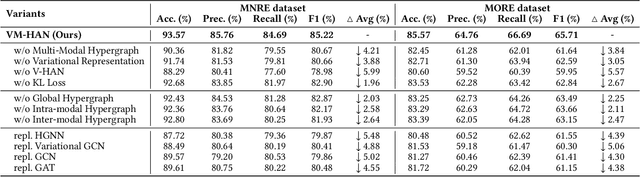
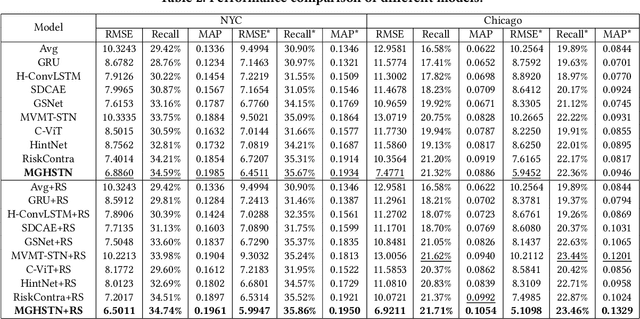
Multi-modal relation extraction (MMRE) is a challenging task that aims to identify relations between entities in text leveraging image information. Existing methods are limited by their neglect of the multiple entity pairs in one sentence sharing very similar contextual information (ie, the same text and image), resulting in increased difficulty in the MMRE task. To address this limitation, we propose the Variational Multi-Modal Hypergraph Attention Network (VM-HAN) for multi-modal relation extraction. Specifically, we first construct a multi-modal hypergraph for each sentence with the corresponding image, to establish different high-order intra-/inter-modal correlations for different entity pairs in each sentence. We further design the Variational Hypergraph Attention Networks (V-HAN) to obtain representational diversity among different entity pairs using Gaussian distribution and learn a better hypergraph structure via variational attention. VM-HAN achieves state-of-the-art performance on the multi-modal relation extraction task, outperforming existing methods in terms of accuracy and efficiency.
FOOL: Addressing the Downlink Bottleneck in Satellite Computing with Neural Feature Compression
Mar 25, 2024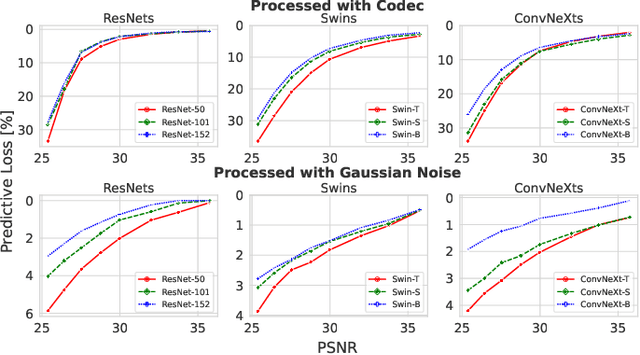
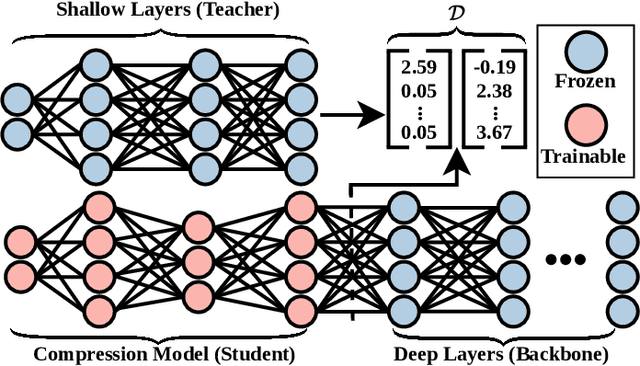
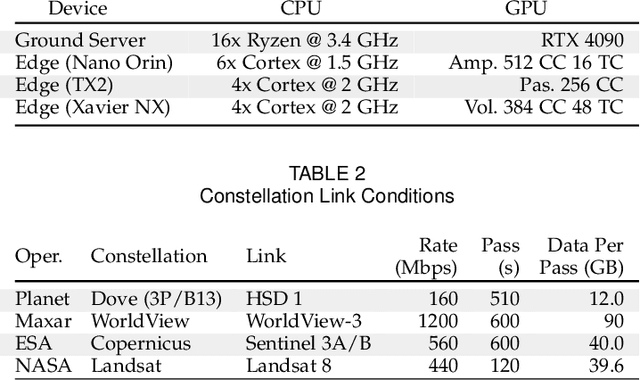
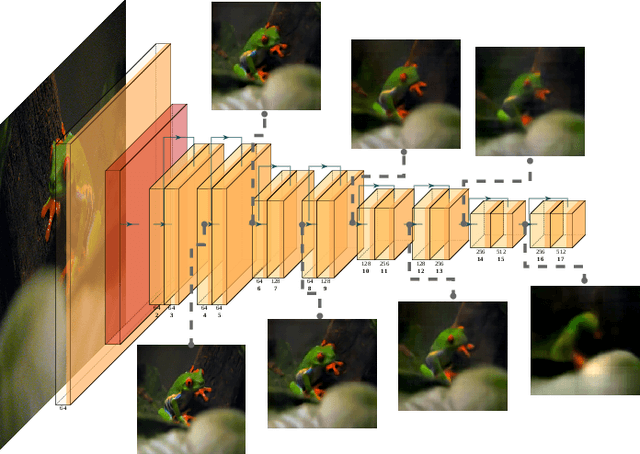
Nanosatellite constellations equipped with sensors capturing large geographic regions provide unprecedented opportunities for Earth observation. As constellation sizes increase, network contention poses a downlink bottleneck. Orbital Edge Computing (OEC) leverages limited onboard compute resources to reduce transfer costs by processing the raw captures at the source. However, current solutions have limited practicability due to reliance on crude filtering methods or over-prioritizing particular downstream tasks. This work presents FOOL, an OEC-native and task-agnostic feature compression method that preserves prediction performance. FOOL partitions high-resolution satellite imagery to maximize throughput. Further, it embeds context and leverages inter-tile dependencies to lower transfer costs with negligible overhead. While FOOL is a feature compressor, it can recover images with competitive scores on perceptual quality measures at lower bitrates. We extensively evaluate transfer cost reduction by including the peculiarity of intermittently available network connections in low earth orbit. Lastly, we test the feasibility of our system for standardized nanosatellite form factors. We demonstrate that FOOL permits downlinking over 100x the data volume without relying on prior information on the downstream tasks.