 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProceedings Seventh International Workshop on Formal Methods for Autonomous Systems
Nov 17, 2025This EPTCS volume contains the papers from the Seventh International Workshop on Formal Methods for Autonomous Systems (FMAS 2025), which was held between the 17th and 19th of November 2025. The goal of the FMAS workshop series is to bring together leading researchers who are using formal methods to tackle the unique challenges that autonomous systems present, so that they can publish and discuss their work with a growing community of researchers. FMAS 2025 was co-located with the 20th International Conference on integrated Formal Methods (iFM'25), hosted by Inria Paris, France at the Inria Paris Center. In total, FMAS 2025 received 16 submissions from researchers at institutions in: Canada, China, France, Germany, Ireland, Italy, Japan, the Netherlands, Portugal, Sweden, the United States of America, and the United Kingdom. Though we received fewer submissions than last year, we are encouraged to see the submissions being sent from a wide range of countries. Submissions come from both past and new FMAS authors, which shows us that the existing community appreciates the network that FMAS has built over the past 7 years, while new authors also show the FMAS community's great potential of growth.
MCPWorld: A Unified Benchmarking Testbed for API, GUI, and Hybrid Computer Use Agents
Jun 09, 2025(M)LLM-powered computer use agents (CUA) are emerging as a transformative technique to automate human-computer interaction. However, existing CUA benchmarks predominantly target GUI agents, whose evaluation methods are susceptible to UI changes and ignore function interactions exposed by application APIs, e.g., Model Context Protocol (MCP). To this end, we propose MCPWorld, the first automatic CUA testbed for API, GUI, and API-GUI hybrid agents. A key principle of MCPWorld is the use of "white-box apps", i.e., those with source code availability and can be revised/re-compiled as needed (e.g., adding MCP support), with two notable advantages: (1) It greatly broadens the design space of CUA, such as what and how the app features to be exposed/extracted as CUA-callable APIs. (2) It allows MCPWorld to programmatically verify task completion by directly monitoring application behavior through techniques like dynamic code instrumentation, offering robust, accurate CUA evaluation decoupled from specific agent implementations or UI states. Currently, MCPWorld includes 201 well curated and annotated user tasks, covering diversified use cases and difficulty levels. MCPWorld is also fully containerized with GPU acceleration support for flexible adoption on different OS/hardware environments. Our preliminary experiments, using a representative LLM-powered CUA framework, achieve 75.12% task completion accuracy, simultaneously providing initial evidence on the practical effectiveness of agent automation leveraging MCP. Overall, we anticipate MCPWorld to facilitate and standardize the benchmarking of next-generation computer use agents that can leverage rich external tools. Our code and dataset are publicly available at https://github.com/SAAgent/MCPWorld.
UIShift: Enhancing VLM-based GUI Agents through Self-supervised Reinforcement Learning
May 18, 2025



Training effective Vision Language Models (VLMs) for GUI agents typically relies on supervised fine-tuning (SFT) over large-scale annotated datasets, where the collection process is labor-intensive and error-prone. In this work, we propose a self-supervised inverse dynamics task to enable VLMs to learn from GUI transition pairs by inferring the action that caused that transition. This training task offers two advantages: (1) It enables VLMs to ignore variations unrelated to user actions (e.g., background refreshes, ads) and to focus on true affordances such as buttons and input fields within complex GUIs. (2) The training data can be easily obtained from existing GUI trajectories without requiring human annotation, and it can be easily scaled through automatic offline exploration. Using this training task, we propose UI-shift, a framework for enhancing VLM-based GUI agents through self-supervised reinforcement learning (RL). With only 2K training samples sourced from existing datasets, two VLMs -- Qwen2.5-VL-3B and Qwen2.5-VL-7B -- trained with UI-Shift achieve competitive or superior performance on grounding tasks (ScreenSpot-series benchmarks) and GUI automation tasks (AndroidControl), compared to SFT baselines and GUI-specific models that explicitly elicit reasoning abilities during RL. Our findings suggest a potential direction for enhancing VLMs for GUI agents by leveraging more self-supervised training data in the future.
Uncertain Machine Ethics Planning
May 07, 2025Machine Ethics decisions should consider the implications of uncertainty over decisions. Decisions should be made over sequences of actions to reach preferable outcomes long term. The evaluation of outcomes, however, may invoke one or more moral theories, which might have conflicting judgements. Each theory will require differing representations of the ethical situation. For example, Utilitarianism measures numerical values, Deontology analyses duties, and Virtue Ethics emphasises moral character. While balancing potentially conflicting moral considerations, decisions may need to be made, for example, to achieve morally neutral goals with minimal costs. In this paper, we formalise the problem as a Multi-Moral Markov Decision Process and a Multi-Moral Stochastic Shortest Path Problem. We develop a heuristic algorithm based on Multi-Objective AO*, utilising Sven-Ove Hansson's Hypothetical Retrospection procedure for ethical reasoning under uncertainty. Our approach is validated by a case study from Machine Ethics literature: the problem of whether to steal insulin for someone who needs it.
Does Chain-of-Thought Reasoning Help Mobile GUI Agent? An Empirical Study
Mar 21, 2025



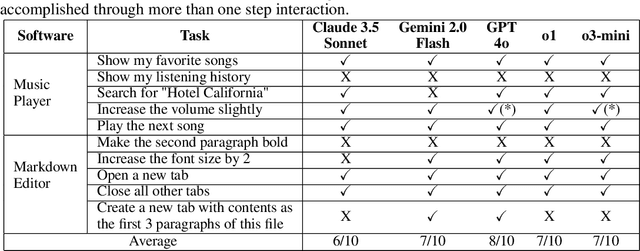
Reasoning capabilities have significantly improved the performance of vision-language models (VLMs) in domains such as mathematical problem-solving, coding, and visual question-answering. However, their impact on real-world applications remains unclear. This paper presents the first empirical study on the effectiveness of reasoning-enabled VLMs in mobile GUI agents, a domain that requires interpreting complex screen layouts, understanding user instructions, and executing multi-turn interactions. We evaluate two pairs of commercial models--Gemini 2.0 Flash and Claude 3.7 Sonnet--comparing their base and reasoning-enhanced versions across two static benchmarks (ScreenSpot and AndroidControl) and one interactive environment (AndroidWorld). We surprisingly find the Claude 3.7 Sonnet reasoning model achieves state-of-the-art performance on AndroidWorld. However, reasoning VLMs generally offer marginal improvements over non-reasoning models on static benchmarks and even degrade performance in some agent setups. Notably, reasoning and non-reasoning VLMs fail on different sets of tasks, suggesting that reasoning does have an impact, but its benefits and drawbacks counterbalance each other. We attribute these inconsistencies to the limitations of benchmarks and VLMs. Based on the findings, we provide insights for further enhancing mobile GUI agents in terms of benchmarks, VLMs, and their adaptability in dynamically invoking reasoning VLMs. The experimental data are publicly available at https://github.com/LlamaTouch/VLM-Reasoning-Traces.
Every Software as an Agent: Blueprint and Case Study
Feb 07, 2025


The rise of (multimodal) large language models (LLMs) has shed light on software agent -- where software can understand and follow user instructions in natural language. However, existing approaches such as API-based and GUI-based agents are far from satisfactory at accuracy and efficiency aspects. Instead, we advocate to endow LLMs with access to the software internals (source code and runtime context) and the permission to dynamically inject generated code into software for execution. In such a whitebox setting, one may better leverage the software context and the coding ability of LLMs. We then present an overall design architecture and case studies on two popular web-based desktop applications. We also give in-depth discussion of the challenges and future directions. We deem that such a new paradigm has the potential to fundamentally overturn the existing software agent design, and finally creating a digital world in which software can comprehend, operate, collaborate, and even think to meet complex user needs.
DroidCall: A Dataset for LLM-powered Android Intent Invocation
Nov 30, 2024



The growing capabilities of large language models in natural language understanding significantly strengthen existing agentic systems. To power performant on-device mobile agents for better data privacy, we introduce DroidCall, the first training and testing dataset for accurate Android intent invocation. With a highly flexible and reusable data generation pipeline, we constructed 10k samples in DroidCall. Given a task instruction in natural language, small language models such as Qwen2.5-3B and Gemma2-2B fine-tuned with DroidCall can approach or even surpass the capabilities of GPT-4o for accurate Android intent invocation. We also provide an end-to-end Android app equipped with these fine-tuned models to demonstrate the Android intent invocation process. The code and dataset are available at https://github.com/UbiquitousLearning/DroidCall.
Proceedings Sixth International Workshop on Formal Methods for Autonomous Systems
Nov 20, 2024This EPTCS volume contains the papers from the Sixth International Workshop on Formal Methods for Autonomous Systems (FMAS 2024), which was held between the 11th and 13th of November 2024. FMAS 2024 was co-located with 19th International Conference on integrated Formal Methods (iFM'24), hosted by the University of Manchester in the United Kingdom, in the University of Manchester's Core Technology Facility.
PhoneLM:an Efficient and Capable Small Language Model Family through Principled Pre-training
Nov 07, 2024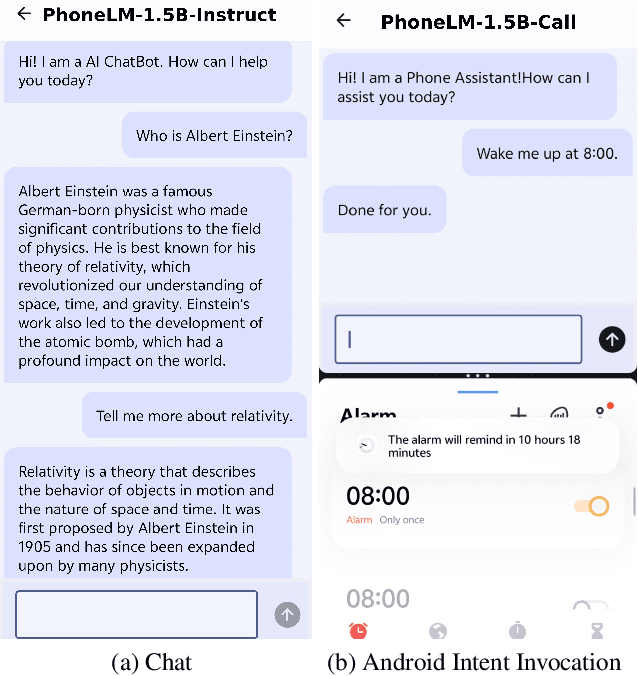
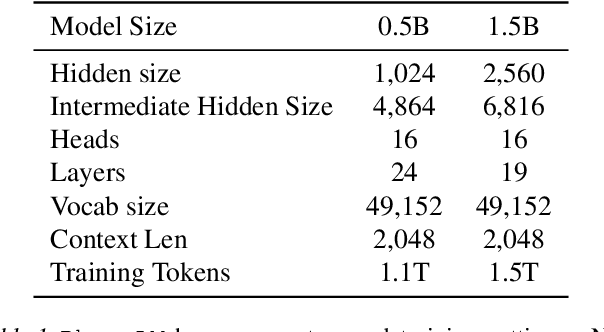
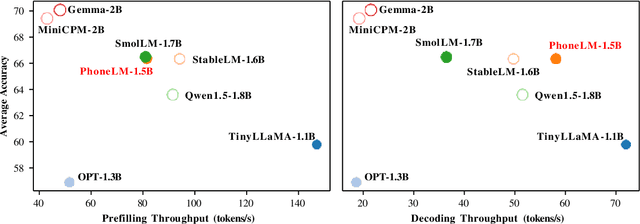

The interest in developing small language models (SLM) for on-device deployment is fast growing. However, the existing SLM design hardly considers the device hardware characteristics. Instead, this work presents a simple yet effective principle for SLM design: architecture searching for (near-)optimal runtime efficiency before pre-training. Guided by this principle, we develop PhoneLM SLM family (currently with 0.5B and 1.5B versions), that acheive the state-of-the-art capability-efficiency tradeoff among those with similar parameter size. We fully open-source the code, weights, and training datasets of PhoneLM for reproducibility and transparency, including both base and instructed versions. We also release a finetuned version of PhoneLM capable of accurate Android Intent invocation, and an end-to-end Android demo. All materials are available at https://github.com/UbiquitousLearning/PhoneLM.
Small Language Models: Survey, Measurements, and Insights
Sep 24, 2024


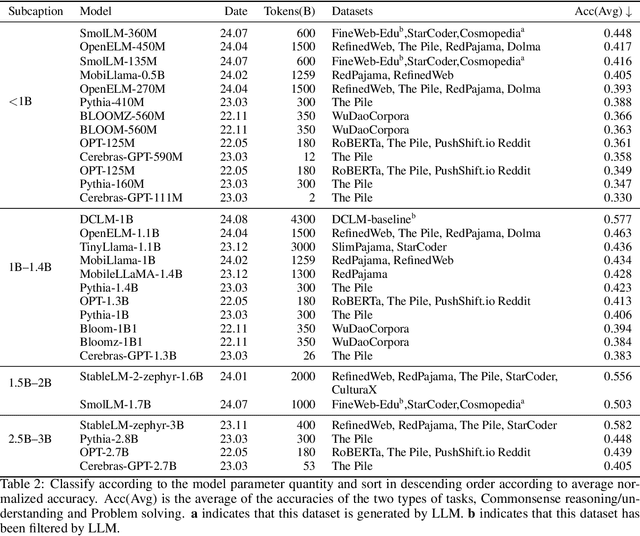
Small language models (SLMs), despite their widespread adoption in modern smart devices, have received significantly less academic attention compared to their large language model (LLM) counterparts, which are predominantly deployed in data centers and cloud environments. While researchers continue to improve the capabilities of LLMs in the pursuit of artificial general intelligence, SLM research aims to make machine intelligence more accessible, affordable, and efficient for everyday tasks. Focusing on transformer-based, decoder-only language models with 100M-5B parameters, we survey 59 state-of-the-art open-source SLMs, analyzing their technical innovations across three axes: architectures, training datasets, and training algorithms. In addition, we evaluate their capabilities in various domains, including commonsense reasoning, in-context learning, mathematics, and coding. To gain further insight into their on-device runtime costs, we benchmark their inference latency and memory footprints. Through in-depth analysis of our benchmarking data, we offer valuable insights to advance research in this field.