 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Scaling: Agents Are Heading to the Edge
May 18, 2026The bottleneck of useful agentic intelligence has shifted from compressing world knowledge into a single model to executing a coordinated system. This position paper argues that personal-agent architecture must move to the edge because the core properties of agentic intelligence tasks, particularly their structural coupling with high-fidelity local context and the need for zero-latency execution loops, do not sit well with cloud-centric designs. We develop this claim through three structural shifts. First, the Prefrontal Turn: the main marginal lever of capability has moved from pre-training scale to framework-level executive control. Such control must remain physically close to the environment of action if the agent is to preserve cognitive alignment. Second, the Data-Geography Paradox, the ``dark matter'' of agentic data (local file hierarchies, real-time sensor streams, and transient OS states) degrades, disappears, or loses meaning once prepared for cloud transmission, thereby cutting the agent off from ground-truth context. Third, the interaction-alignment loop, the only economically and ecologically sustainable source of agentic refinement data is the high-fidelity implicit preference signal produced through real-time local interaction. Third, the interaction-alignment loop, the only economically and ecologically sustainable source of agentic refinement data is the high-fidelity implicit preference signal produced through real-time local interaction. We conclude with falsifiable predictions for the next deployment cycle of personal agents.
Editing as Unlearning: Are Knowledge Editing Methods Strong Baselines for Large Language Model Unlearning?
May 26, 2025Large language Model (LLM) unlearning, i.e., selectively removing information from LLMs, is vital for responsible model deployment. Differently, LLM knowledge editing aims to modify LLM knowledge instead of removing it. Though editing and unlearning seem to be two distinct tasks, we find there is a tight connection between them. In this paper, we conceptualize unlearning as a special case of editing where information is modified to a refusal or "empty set" $\emptyset$ response, signifying its removal. This paper thus investigates if knowledge editing techniques are strong baselines for LLM unlearning. We evaluate state-of-the-art (SOTA) editing methods (e.g., ROME, MEMIT, GRACE, WISE, and AlphaEdit) against existing unlearning approaches on pretrained and finetuned knowledge. Results show certain editing methods, notably WISE and AlphaEdit, are effective unlearning baselines, especially for pretrained knowledge, and excel in generating human-aligned refusal answers. To better adapt editing methods for unlearning applications, we propose practical recipes including self-improvement and query merging. The former leverages the LLM's own in-context learning ability to craft a more human-aligned unlearning target, and the latter enables ROME and MEMIT to perform well in unlearning longer sample sequences. We advocate for the unlearning community to adopt SOTA editing methods as baselines and explore unlearning from an editing perspective for more holistic LLM memory control.
Photon: Federated LLM Pre-Training
Nov 05, 2024



Scaling large language models (LLMs) demands extensive data and computing resources, which are traditionally constrained to data centers by the high-bandwidth requirements of distributed training. Low-bandwidth methods like federated learning (FL) could enable collaborative training of larger models across weakly-connected GPUs if they can effectively be used for pre-training. To achieve this, we introduce Photon, the first complete system for federated end-to-end LLM training, leveraging cross-silo FL for global-scale training with minimal communication overheads. Using Photon, we train the first federated family of decoder-only LLMs from scratch. We show that: (1) Photon can train model sizes up to 7B in a federated fashion while reaching an even better perplexity than centralized pre-training; (2) Photon model training time decreases with available compute, achieving a similar compute-time trade-off to centralized; and (3) Photon outperforms the wall-time of baseline distributed training methods by 35% via communicating 64x-512xless. Our proposal is robust to data heterogeneity and converges twice as fast as previous methods like DiLoCo. This surprising data efficiency stems from a unique approach combining small client batch sizes with extremely high learning rates, enabled by federated averaging's robustness to hyperparameters. Photon thus represents the first economical system for global internet-wide LLM pre-training.
DEPT: Decoupled Embeddings for Pre-training Language Models
Oct 07, 2024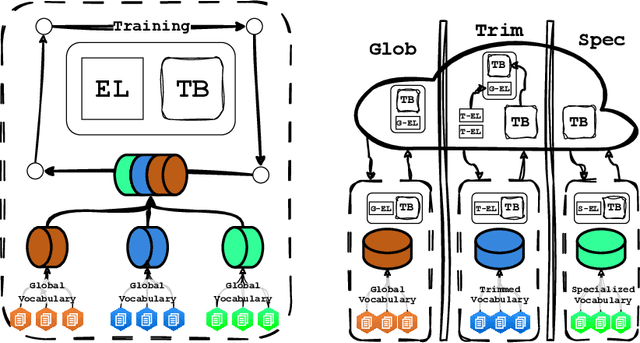
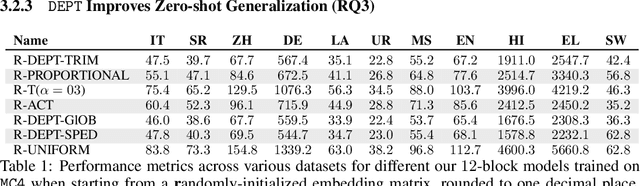


Language Model pre-training benefits from a broader data mixture to enhance performance across domains and languages. However, training on such heterogeneous text corpora is complex, requiring extensive and cost-intensive efforts. Since these data sources vary in lexical, syntactic, and semantic aspects, they cause negative interference or the "curse of multilinguality". We propose a novel pre-training framework to alleviate this curse. Our method, DEPT, decouples the embedding layers from the transformer body while simultaneously training the latter in multiple contexts. DEPT enables the model to train without being bound to a shared global vocabulary. DEPT: (1) can train robustly and effectively under significant data heterogeneity, (2) reduces the parameter count of the token embeddings by up to 80% and the communication costs by 675x for billion-scale models (3) enhances model generalization and plasticity in adapting to new languages and domains, and (4) allows training with custom optimized vocabulary per data source. We prove DEPT's potential by performing the first vocabulary-agnostic federated multilingual pre-training of a 1.3 billion-parameter model across high and low-resource languages, reducing its parameter count by 409 million.
Small Language Models: Survey, Measurements, and Insights
Sep 24, 2024


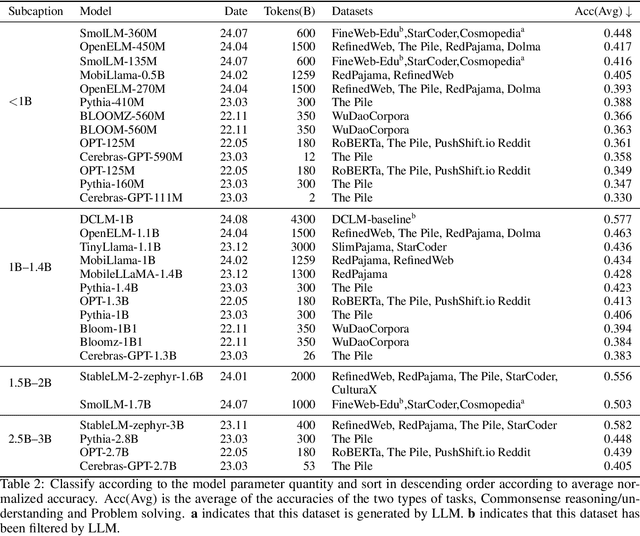
Small language models (SLMs), despite their widespread adoption in modern smart devices, have received significantly less academic attention compared to their large language model (LLM) counterparts, which are predominantly deployed in data centers and cloud environments. While researchers continue to improve the capabilities of LLMs in the pursuit of artificial general intelligence, SLM research aims to make machine intelligence more accessible, affordable, and efficient for everyday tasks. Focusing on transformer-based, decoder-only language models with 100M-5B parameters, we survey 59 state-of-the-art open-source SLMs, analyzing their technical innovations across three axes: architectures, training datasets, and training algorithms. In addition, we evaluate their capabilities in various domains, including commonsense reasoning, in-context learning, mathematics, and coding. To gain further insight into their on-device runtime costs, we benchmark their inference latency and memory footprints. Through in-depth analysis of our benchmarking data, we offer valuable insights to advance research in this field.
FedMoE: Personalized Federated Learning via Heterogeneous Mixture of Experts
Aug 21, 2024As Large Language Models (LLMs) push the boundaries of AI capabilities, their demand for data is growing. Much of this data is private and distributed across edge devices, making Federated Learning (FL) a de-facto alternative for fine-tuning (i.e., FedLLM). However, it faces significant challenges due to the inherent heterogeneity among clients, including varying data distributions and diverse task types. Towards a versatile FedLLM, we replace traditional dense model with a sparsely-activated Mixture-of-Experts (MoE) architecture, whose parallel feed-forward networks enable greater flexibility. To make it more practical in resource-constrained environments, we present FedMoE, the efficient personalized FL framework to address data heterogeneity, constructing an optimal sub-MoE for each client and bringing the knowledge back to global MoE. FedMoE is composed of two fine-tuning stages. In the first stage, FedMoE simplifies the problem by conducting a heuristic search based on observed activation patterns, which identifies a suboptimal submodel for each client. In the second stage, these submodels are distributed to clients for further training and returned for server aggregating through a novel modular aggregation strategy. Meanwhile, FedMoE progressively adjusts the submodels to optimal through global expert recommendation. Experimental results demonstrate the superiority of our method over previous personalized FL methods.
ShortcutsBench: A Large-Scale Real-world Benchmark for API-based Agents
Jun 28, 2024Recent advancements in integrating large language models (LLMs) with application programming interfaces (APIs) have gained significant interest in both academia and industry. These API-based agents, leveraging the strong autonomy and planning capabilities of LLMs, can efficiently solve problems requiring multi-step actions. However, their ability to handle multi-dimensional difficulty levels, diverse task types, and real-world demands through APIs remains unknown. In this paper, we introduce \textsc{ShortcutsBench}, a large-scale benchmark for the comprehensive evaluation of API-based agents in solving tasks with varying levels of difficulty, diverse task types, and real-world demands. \textsc{ShortcutsBench} includes a wealth of real APIs from Apple Inc.'s operating systems, refined user queries from shortcuts, human-annotated high-quality action sequences from shortcut developers, and accurate parameter filling values about primitive parameter types, enum parameter types, outputs from previous actions, and parameters that need to request necessary information from the system or user. Our extensive evaluation of agents built with $5$ leading open-source (size >= 57B) and $4$ closed-source LLMs (e.g. Gemini-1.5-Pro and GPT-3.5) reveals significant limitations in handling complex queries related to API selection, parameter filling, and requesting necessary information from systems and users. These findings highlight the challenges that API-based agents face in effectively fulfilling real and complex user queries. All datasets, code, and experimental results will be available at \url{https://github.com/eachsheep/shortcutsbench}.
FedRDMA: Communication-Efficient Cross-Silo Federated LLM via Chunked RDMA Transmission
Mar 01, 2024Communication overhead is a significant bottleneck in federated learning (FL), which has been exaggerated with the increasing size of AI models. In this paper, we propose FedRDMA, a communication-efficient cross-silo FL system that integrates RDMA into the FL communication protocol. To overcome the limitations of RDMA in wide-area networks (WANs), FedRDMA divides the updated model into chunks and designs a series of optimization techniques to improve the efficiency and robustness of RDMA-based communication. We implement FedRDMA atop the industrial federated learning framework and evaluate it on a real-world cross-silo FL scenario. The experimental results show that \sys can achieve up to 3.8$\times$ speedup in communication efficiency compared to traditional TCP/IP-based FL systems.
Lightweight Protection for Privacy in Offloaded Speech Understanding
Jan 22, 2024Speech is a common input method for mobile embedded devices, but cloud-based speech recognition systems pose privacy risks. Disentanglement-based encoders, designed to safeguard user privacy by filtering sensitive information from speech signals, unfortunately require substantial memory and computational resources, which limits their use in less powerful devices. To overcome this, we introduce a novel system, XXX, optimized for such devices. XXX is built on the insight that speech understanding primarily relies on understanding the entire utterance's long-term dependencies, while privacy concerns are often linked to short-term details. Therefore, XXX focuses on selectively masking these short-term elements, preserving the quality of long-term speech understanding. The core of XXX is an innovative differential mask generator, grounded in interpretable learning, which fine-tunes the masking process. We tested XXX on the STM32H7 microcontroller, assessing its performance in various potential attack scenarios. The results show that XXX maintains speech understanding accuracy and privacy at levels comparable to existing encoders, but with a significant improvement in efficiency, achieving up to 53.3$\times$ faster processing and a 134.1$\times$ smaller memory footprint.
A Survey of Resource-efficient LLM and Multimodal Foundation Models
Jan 16, 2024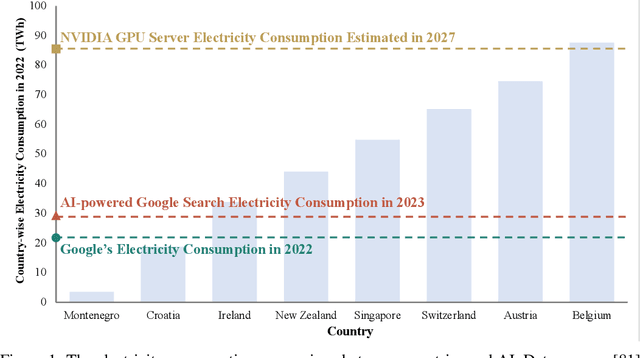
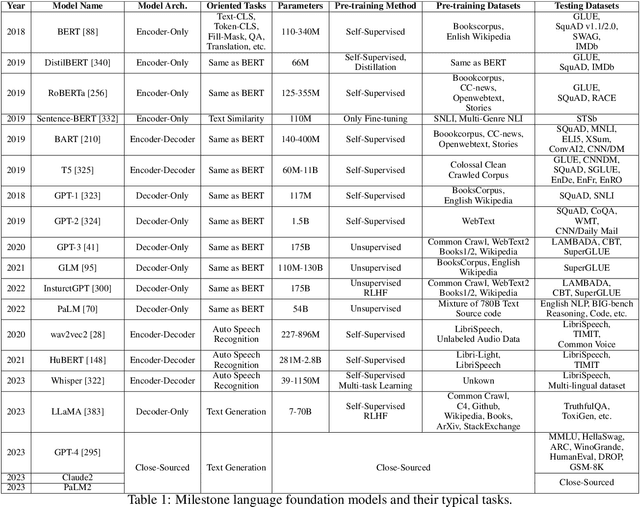
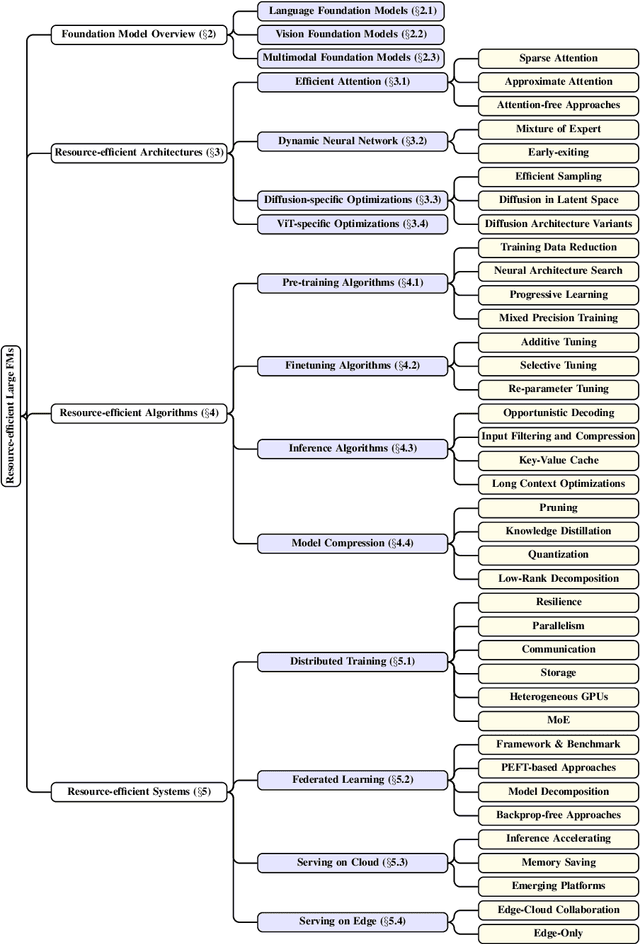
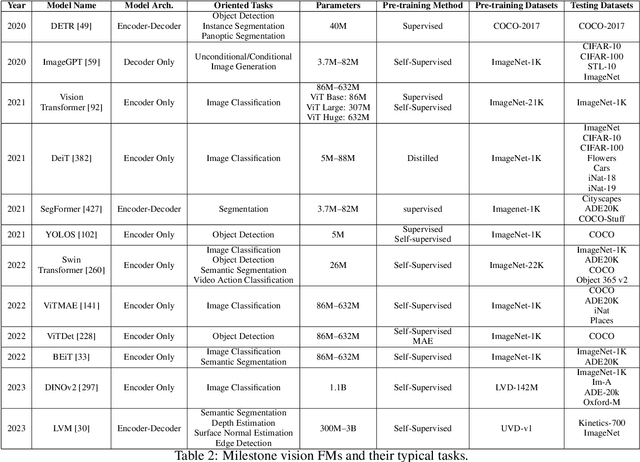
Large foundation models, including large language models (LLMs), vision transformers (ViTs), diffusion, and LLM-based multimodal models, are revolutionizing the entire machine learning lifecycle, from training to deployment. However, the substantial advancements in versatility and performance these models offer come at a significant cost in terms of hardware resources. To support the growth of these large models in a scalable and environmentally sustainable way, there has been a considerable focus on developing resource-efficient strategies. This survey delves into the critical importance of such research, examining both algorithmic and systemic aspects. It offers a comprehensive analysis and valuable insights gleaned from existing literature, encompassing a broad array of topics from cutting-edge model architectures and training/serving algorithms to practical system designs and implementations. The goal of this survey is to provide an overarching understanding of how current approaches are tackling the resource challenges posed by large foundation models and to potentially inspire future breakthroughs in this field.