 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoReAct: Egocentric Video-Driven 3D Human Reaction Generation
Dec 28, 2025Humans exhibit adaptive, context-sensitive responses to egocentric visual input. However, faithfully modeling such reactions from egocentric video remains challenging due to the dual requirements of strictly causal generation and precise 3D spatial alignment. To tackle this problem, we first construct the Human Reaction Dataset (HRD) to address data scarcity and misalignment by building a spatially aligned egocentric video-reaction dataset, as existing datasets (e.g., ViMo) suffer from significant spatial inconsistency between the egocentric video and reaction motion, e.g., dynamically moving motions are always paired with fixed-camera videos. Leveraging HRD, we present EgoReAct, the first autoregressive framework that generates 3D-aligned human reaction motions from egocentric video streams in real-time. We first compress the reaction motion into a compact yet expressive latent space via a Vector Quantised-Variational AutoEncoder and then train a Generative Pre-trained Transformer for reaction generation from the visual input. EgoReAct incorporates 3D dynamic features, i.e., metric depth, and head dynamics during the generation, which effectively enhance spatial grounding. Extensive experiments demonstrate that EgoReAct achieves remarkably higher realism, spatial consistency, and generation efficiency compared with prior methods, while maintaining strict causality during generation. We will release code, models, and data upon acceptance.
ARIES: Autonomous Reasoning with LLMs on Interactive Thought Graph Environments
Feb 28, 2025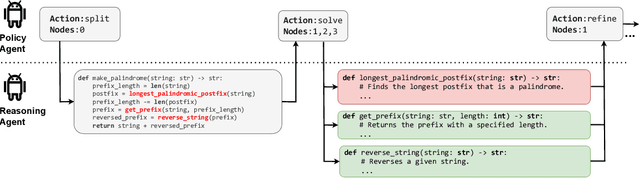



Recent research has shown that LLM performance on reasoning tasks can be enhanced by scaling test-time compute. One promising approach, particularly with decomposable problems, involves arranging intermediate solutions as a graph on which transformations are performed to explore the solution space. However, prior works rely on pre-determined, task-specific transformation schedules which are subject to a set of searched hyperparameters. In this work, we view thought graph transformations as actions in a Markov decision process, and implement policy agents to drive effective action policies for the underlying reasoning LLM agent. In particular, we investigate the ability for another LLM to act as a policy agent on thought graph environments and introduce ARIES, a multi-agent architecture for reasoning with LLMs. In ARIES, reasoning LLM agents solve decomposed subproblems, while policy LLM agents maintain visibility of the thought graph states, and dynamically adapt the problem-solving strategy. Through extensive experiments, we observe that using off-the-shelf LLMs as policy agents with no supervised fine-tuning (SFT) can yield up to $29\%$ higher accuracy on HumanEval relative to static transformation schedules, as well as reducing inference costs by $35\%$ and avoid any search requirements. We also conduct a thorough analysis of observed failure modes, highlighting that limitations on LLM sizes and the depth of problem decomposition can be seen as challenges to scaling LLM-guided reasoning.
MotionWavelet: Human Motion Prediction via Wavelet Manifold Learning
Nov 25, 2024Modeling temporal characteristics and the non-stationary dynamics of body movement plays a significant role in predicting human future motions. However, it is challenging to capture these features due to the subtle transitions involved in the complex human motions. This paper introduces MotionWavelet, a human motion prediction framework that utilizes Wavelet Transformation and studies human motion patterns in the spatial-frequency domain. In MotionWavelet, a Wavelet Diffusion Model (WDM) learns a Wavelet Manifold by applying Wavelet Transformation on the motion data therefore encoding the intricate spatial and temporal motion patterns. Once the Wavelet Manifold is built, WDM trains a diffusion model to generate human motions from Wavelet latent vectors. In addition to the WDM, MotionWavelet also presents a Wavelet Space Shaping Guidance mechanism to refine the denoising process to improve conformity with the manifold structure. WDM also develops Temporal Attention-Based Guidance to enhance prediction accuracy. Extensive experiments validate the effectiveness of MotionWavelet, demonstrating improved prediction accuracy and enhanced generalization across various benchmarks. Our code and models will be released upon acceptance.
Photon: Federated LLM Pre-Training
Nov 05, 2024



Scaling large language models (LLMs) demands extensive data and computing resources, which are traditionally constrained to data centers by the high-bandwidth requirements of distributed training. Low-bandwidth methods like federated learning (FL) could enable collaborative training of larger models across weakly-connected GPUs if they can effectively be used for pre-training. To achieve this, we introduce Photon, the first complete system for federated end-to-end LLM training, leveraging cross-silo FL for global-scale training with minimal communication overheads. Using Photon, we train the first federated family of decoder-only LLMs from scratch. We show that: (1) Photon can train model sizes up to 7B in a federated fashion while reaching an even better perplexity than centralized pre-training; (2) Photon model training time decreases with available compute, achieving a similar compute-time trade-off to centralized; and (3) Photon outperforms the wall-time of baseline distributed training methods by 35% via communicating 64x-512xless. Our proposal is robust to data heterogeneity and converges twice as fast as previous methods like DiLoCo. This surprising data efficiency stems from a unique approach combining small client batch sizes with extremely high learning rates, enabled by federated averaging's robustness to hyperparameters. Photon thus represents the first economical system for global internet-wide LLM pre-training.
Scaling Laws for Mixed quantization in Large Language Models
Oct 09, 2024



Post-training quantization of Large Language Models (LLMs) has proven effective in reducing the computational requirements for running inference on these models. In this study, we focus on a straightforward question: When aiming for a specific accuracy or perplexity target for low-precision quantization, how many high-precision numbers or calculations are required to preserve as we scale LLMs to larger sizes? We first introduce a critical metric named the quantization ratio, which compares the number of parameters quantized to low-precision arithmetic against the total parameter count. Through extensive and carefully controlled experiments across different model families, arithmetic types, and quantization granularities (e.g. layer-wise, matmul-wise), we identify two central phenomenons. 1) The larger the models, the better they can preserve performance with an increased quantization ratio, as measured by perplexity in pre-training tasks or accuracy in downstream tasks. 2) The finer the granularity of mixed-precision quantization (e.g., matmul-wise), the more the model can increase the quantization ratio. We believe these observed phenomena offer valuable insights for future AI hardware design and the development of advanced Efficient AI algorithms.
Hedge Fund Portfolio Construction Using PolyModel Theory and iTransformer
Aug 06, 2024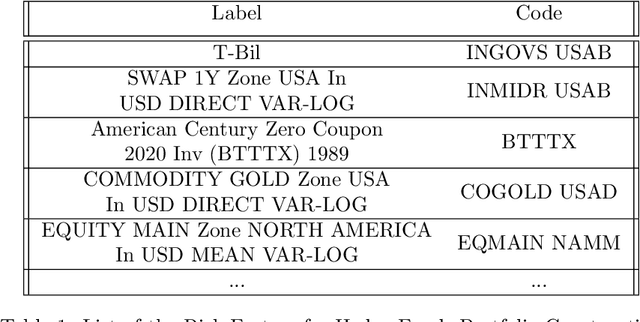
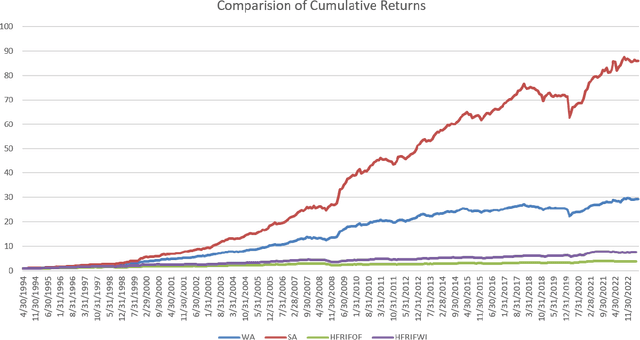
When constructing portfolios, a key problem is that a lot of financial time series data are sparse, making it challenging to apply machine learning methods. Polymodel theory can solve this issue and demonstrate superiority in portfolio construction from various aspects. To implement the PolyModel theory for constructing a hedge fund portfolio, we begin by identifying an asset pool, utilizing over 10,000 hedge funds for the past 29 years' data. PolyModel theory also involves choosing a wide-ranging set of risk factors, which includes various financial indices, currencies, and commodity prices. This comprehensive selection mirrors the complexities of the real-world environment. Leveraging on the PolyModel theory, we create quantitative measures such as Long-term Alpha, Long-term Ratio, and SVaR. We also use more classical measures like the Sharpe ratio or Morningstar's MRAR. To enhance the performance of the constructed portfolio, we also employ the latest deep learning techniques (iTransformer) to capture the upward trend, while efficiently controlling the downside, using all the features. The iTransformer model is specifically designed to address the challenges in high-dimensional time series forecasting and could largely improve our strategies. More precisely, our strategies achieve better Sharpe ratio and annualized return. The above process enables us to create multiple portfolio strategies aiming for high returns and low risks when compared to various benchmarks.
DICE: End-to-end Deformation Capture of Hand-Face Interactions from a Single Image
Jun 26, 2024



Reconstructing 3D hand-face interactions with deformations from a single image is a challenging yet crucial task with broad applications in AR, VR, and gaming. The challenges stem from self-occlusions during single-view hand-face interactions, diverse spatial relationships between hands and face, complex deformations, and the ambiguity of the single-view setting. The first and only method for hand-face interaction recovery, Decaf, introduces a global fitting optimization guided by contact and deformation estimation networks trained on studio-collected data with 3D annotations. However, Decaf suffers from a time-consuming optimization process and limited generalization capability due to its reliance on 3D annotations of hand-face interaction data. To address these issues, we present DICE, the first end-to-end method for Deformation-aware hand-face Interaction reCovEry from a single image. DICE estimates the poses of hands and faces, contacts, and deformations simultaneously using a Transformer-based architecture. It features disentangling the regression of local deformation fields and global mesh vertex locations into two network branches, enhancing deformation and contact estimation for precise and robust hand-face mesh recovery. To improve generalizability, we propose a weakly-supervised training approach that augments the training set using in-the-wild images without 3D ground-truth annotations, employing the depths of 2D keypoints estimated by off-the-shelf models and adversarial priors of poses for supervision. Our experiments demonstrate that DICE achieves state-of-the-art performance on a standard benchmark and in-the-wild data in terms of accuracy and physical plausibility. Additionally, our method operates at an interactive rate (20 fps) on an Nvidia 4090 GPU, whereas Decaf requires more than 15 seconds for a single image. Our code will be publicly available upon publication.
AutoCV: Empowering Reasoning with Automated Process Labeling via Confidence Variation
May 29, 2024



In this work, we propose a novel method named \textbf{Auto}mated Process Labeling via \textbf{C}onfidence \textbf{V}ariation (\textbf{\textsc{AutoCV}}) to enhance the reasoning capabilities of large language models (LLMs) by automatically annotating the reasoning steps. Our approach begins by training a verification model on the correctness of final answers, enabling it to generate automatic process annotations. This verification model assigns a confidence score to each reasoning step, indicating the probability of arriving at the correct final answer from that point onward. We detect relative changes in the verification's confidence scores across reasoning steps to automatically annotate the reasoning process. This alleviates the need for numerous manual annotations or the high computational costs associated with model-induced annotation approaches. We experimentally validate that the confidence variations learned by the verification model trained on the final answer correctness can effectively identify errors in the reasoning steps. Subsequently, we demonstrate that the process annotations generated by \textsc{AutoCV} can improve the accuracy of the verification model in selecting the correct answer from multiple outputs generated by LLMs. Notably, we achieve substantial improvements across five datasets in mathematics and commonsense reasoning. The source code of \textsc{AutoCV} is available at \url{https://github.com/rookie-joe/AUTOCV}.
The Future of Large Language Model Pre-training is Federated
May 17, 2024



Generative pre-trained large language models (LLMs) have demonstrated impressive performance over a wide range of tasks, thanks to the unprecedented amount of data they have been trained on. As established scaling laws indicate, LLMs' future performance improvement depends on the amount of computing and data sources we can leverage for pre-training. Federated learning (FL) has the potential to unleash the majority of the planet's data and computational resources, which are underutilized by the data-center-focused training methodology of current LLM practice. Our work presents a robust, flexible, reproducible FL approach that enables large-scale collaboration across institutions to train LLMs. This would mobilize more computational and data resources while matching or potentially exceeding centralized performance. We further show the effectiveness of the federated training scales with model size and present our approach for training a billion-scale federated LLM using limited resources. This will help data-rich actors to become the protagonists of LLMs pre-training instead of leaving the stage to compute-rich actors alone.
EMDM: Efficient Motion Diffusion Model for Fast, High-Quality Motion Generation
Dec 04, 2023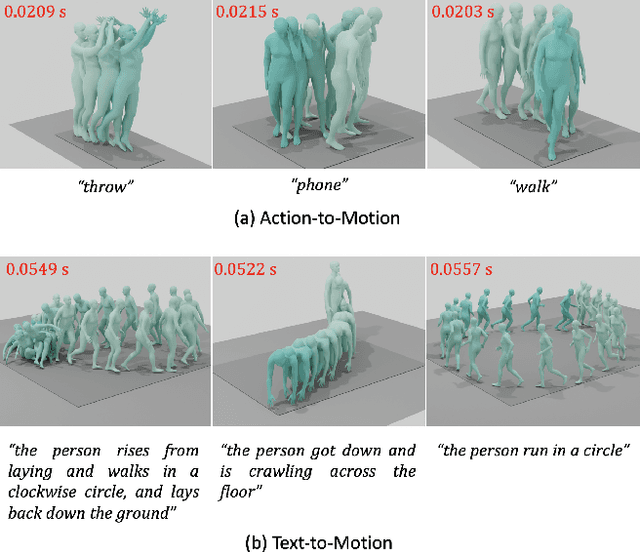

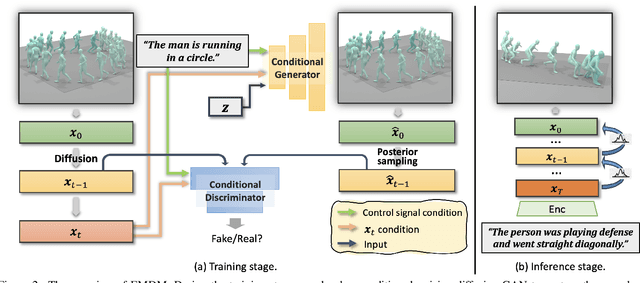
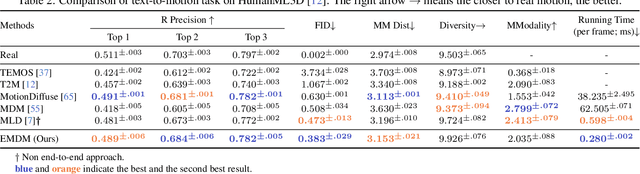
We introduce Efficient Motion Diffusion Model (EMDM) for fast and high-quality human motion generation. Although previous motion diffusion models have shown impressive results, they struggle to achieve fast generation while maintaining high-quality human motions. Motion latent diffusion has been proposed for efficient motion generation. However, effectively learning a latent space can be non-trivial in such a two-stage manner. Meanwhile, accelerating motion sampling by increasing the step size, e.g., DDIM, typically leads to a decline in motion quality due to the inapproximation of complex data distributions when naively increasing the step size. In this paper, we propose EMDM that allows for much fewer sample steps for fast motion generation by modeling the complex denoising distribution during multiple sampling steps. Specifically, we develop a Conditional Denoising Diffusion GAN to capture multimodal data distributions conditioned on both control signals, i.e., textual description and denoising time step. By modeling the complex data distribution, a larger sampling step size and fewer steps are achieved during motion synthesis, significantly accelerating the generation process. To effectively capture the human dynamics and reduce undesired artifacts, we employ motion geometric loss during network training, which improves the motion quality and training efficiency. As a result, EMDM achieves a remarkable speed-up at the generation stage while maintaining high-quality motion generation in terms of fidelity and diversity.