 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDES-LOC: Desynced Low Communication Adaptive Optimizers for Training Foundation Models
May 28, 2025Scaling foundation model training with Distributed Data Parallel (DDP) methods is bandwidth-limited. Existing infrequent communication methods like Local SGD were designed to synchronize only model parameters and cannot be trivially applied to adaptive optimizers due to additional optimizer states. Current approaches extending Local SGD either lack convergence guarantees or require synchronizing all optimizer states, tripling communication costs. We propose Desynced Low Communication Adaptive Optimizers (DES-LOC), a family of optimizers assigning independent synchronization periods to parameters and momenta, enabling lower communication costs while preserving convergence. Through extensive experiments on language models of up to 1.7B, we show that DES-LOC can communicate 170x less than DDP and 2x less than the previous state-of-the-art Local ADAM. Furthermore, unlike previous heuristic approaches, DES-LOC is suited for practical training scenarios prone to system failures. DES-LOC offers a scalable, bandwidth-efficient, and fault-tolerant solution for foundation model training.
Compliance Cards: Computational Artifacts for Automated AI Regulation Compliance
Jun 20, 2024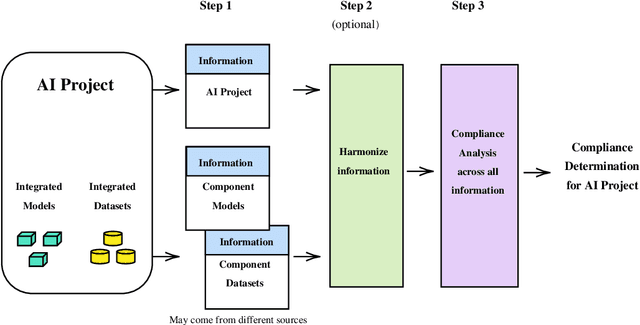

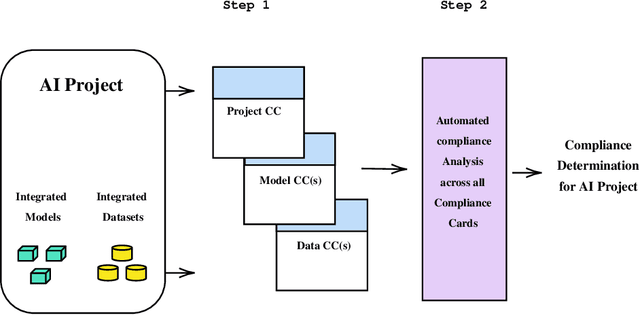
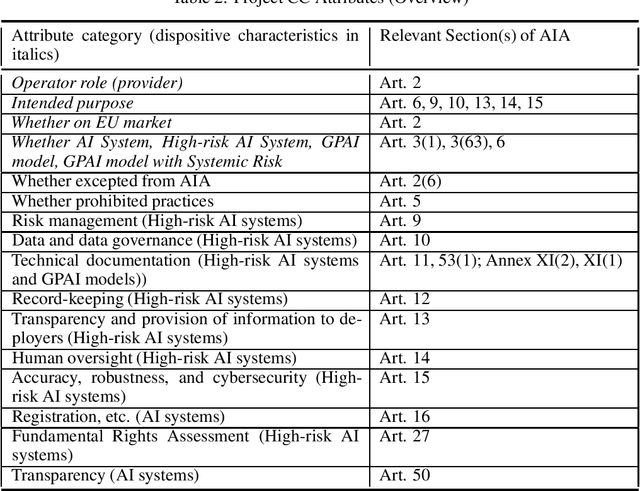
As the artificial intelligence (AI) supply chain grows more complex, AI systems and models are increasingly likely to incorporate externally-sourced ingredients such as datasets and other models. In such cases, determining whether or not an AI system or model complies with the EU AI Act will require gathering compliance-related metadata about both the AI system or model at-large as well as those externally-supplied ingredients. There must then be an analysis that looks across all of this metadata to render a prediction about the compliance of the overall AI system or model. Up until now, this process has not been automated. Thus, it has not been possible to make real-time compliance determinations in scenarios where doing so would be advantageous, such as the iterative workflows of today's AI developers, search and acquisition of AI ingredients on communities like Hugging Face, federated and continuous learning, and more. To address this shortcoming, we introduce a highly automated system for AI Act compliance analysis. This system has two key elements. First is an interlocking set of computational artifacts that capture compliance-related metadata about both: (1) the AI system or model at-large; (2) any constituent ingredients such as datasets and models. Second is an automated analysis algorithm that operates across those computational artifacts to render a run-time prediction about whether or not the overall AI system or model complies with the AI Act. Working together, these elements promise to enhance and accelerate AI Act compliance assessments.
Worldwide Federated Training of Language Models
May 23, 2024



The reliance of language model training on massive amounts of computation and vast datasets scraped from potentially low-quality, copyrighted, or sensitive data has come into question practically, legally, and ethically. Federated learning provides a plausible alternative by enabling previously untapped data to be voluntarily gathered from collaborating organizations. However, when scaled globally, federated learning requires collaboration across heterogeneous legal, security, and privacy regimes while accounting for the inherent locality of language data; this further exacerbates the established challenge of federated statistical heterogeneity. We propose a Worldwide Federated Language Model Training~(WorldLM) system based on federations of federations, where each federation has the autonomy to account for factors such as its industry, operating jurisdiction, or competitive environment. WorldLM enables such autonomy in the presence of statistical heterogeneity via partial model localization by allowing sub-federations to attentively aggregate key layers from their constituents. Furthermore, it can adaptively share information across federations via residual layer embeddings. Evaluations of language modeling on naturally heterogeneous datasets show that WorldLM outperforms standard federations by up to $1.91\times$, approaches the personalized performance of fully local models, and maintains these advantages under privacy-enhancing techniques.
The Future of Large Language Model Pre-training is Federated
May 17, 2024



Generative pre-trained large language models (LLMs) have demonstrated impressive performance over a wide range of tasks, thanks to the unprecedented amount of data they have been trained on. As established scaling laws indicate, LLMs' future performance improvement depends on the amount of computing and data sources we can leverage for pre-training. Federated learning (FL) has the potential to unleash the majority of the planet's data and computational resources, which are underutilized by the data-center-focused training methodology of current LLM practice. Our work presents a robust, flexible, reproducible FL approach that enables large-scale collaboration across institutions to train LLMs. This would mobilize more computational and data resources while matching or potentially exceeding centralized performance. We further show the effectiveness of the federated training scales with model size and present our approach for training a billion-scale federated LLM using limited resources. This will help data-rich actors to become the protagonists of LLMs pre-training instead of leaving the stage to compute-rich actors alone.
Fully Convolutional Generative Machine Learning Method for Accelerating Non-Equilibrium Greens Function Simulations
Sep 17, 2023This work describes a novel simulation approach that combines machine learning and device modelling simulations. The device simulations are based on the quantum mechanical non-equilibrium Greens function (NEGF) approach and the machine learning method is an extension to a convolutional generative network. We have named our new simulation approach ML-NEGF and we have implemented it in our in-house simulator called NESS (nano-electronics simulations software). The reported results demonstrate the improved convergence speed of the ML-NEGF method in comparison to the standard NEGF approach. The trained ML model effectively learns the underlying physics of nano-sheet transistor behaviour, resulting in faster convergence of the coupled Poisson-NEGF simulations. Quantitatively, our ML- NEGF approach achieves an average convergence acceleration of 60%, substantially reducing the computational time while maintaining the same accuracy.