 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexRank: Nested Low-Rank Knowledge Decomposition for Adaptive Model Deployment
Feb 02, 2026The growing scale of deep neural networks, encompassing large language models (LLMs) and vision transformers (ViTs), has made training from scratch prohibitively expensive and deployment increasingly costly. These models are often used as computational monoliths with fixed cost, a rigidity that does not leverage overparametrized architectures and largely hinders adaptive deployment across different cost budgets. We argue that importance-ordered nested components can be extracted from pretrained models, and selectively activated on the available computational budget. To this end, our proposed FlexRank method leverages low-rank weight decomposition with nested, importance-based consolidation to extract submodels of increasing capabilities. Our approach enables a "train-once, deploy-everywhere" paradigm that offers a graceful trade-off between cost and performance without training from scratch for each budget - advancing practical deployment of large models.
Who to Trust? Aggregating Client Knowledge in Logit-Based Federated Learning
Sep 18, 2025Federated learning (FL) usually shares model weights or gradients, which is costly for large models. Logit-based FL reduces this cost by sharing only logits computed on a public proxy dataset. However, aggregating information from heterogeneous clients is still challenging. This paper studies this problem, introduces and compares three logit aggregation methods: simple averaging, uncertainty-weighted averaging, and a learned meta-aggregator. Evaluated on MNIST and CIFAR-10, these methods reduce communication overhead, improve robustness under non-IID data, and achieve accuracy competitive with centralized training.
Simple Stepsize for Quasi-Newton Methods with Global Convergence Guarantees
Aug 27, 2025Quasi-Newton methods are widely used for solving convex optimization problems due to their ease of implementation, practical efficiency, and strong local convergence guarantees. However, their global convergence is typically established only under specific line search strategies and the assumption of strong convexity. In this work, we extend the theoretical understanding of Quasi-Newton methods by introducing a simple stepsize schedule that guarantees a global convergence rate of ${O}(1/k)$ for the convex functions. Furthermore, we show that when the inexactness of the Hessian approximation is controlled within a prescribed relative accuracy, the method attains an accelerated convergence rate of ${O}(1/k^2)$ -- matching the best-known rates of both Nesterov's accelerated gradient method and cubically regularized Newton methods. We validate our theoretical findings through empirical comparisons, demonstrating clear improvements over standard Quasi-Newton baselines. To further enhance robustness, we develop an adaptive variant that adjusts to the function's curvature while retaining the global convergence guarantees of the non-adaptive algorithm.
DES-LOC: Desynced Low Communication Adaptive Optimizers for Training Foundation Models
May 28, 2025Scaling foundation model training with Distributed Data Parallel (DDP) methods is bandwidth-limited. Existing infrequent communication methods like Local SGD were designed to synchronize only model parameters and cannot be trivially applied to adaptive optimizers due to additional optimizer states. Current approaches extending Local SGD either lack convergence guarantees or require synchronizing all optimizer states, tripling communication costs. We propose Desynced Low Communication Adaptive Optimizers (DES-LOC), a family of optimizers assigning independent synchronization periods to parameters and momenta, enabling lower communication costs while preserving convergence. Through extensive experiments on language models of up to 1.7B, we show that DES-LOC can communicate 170x less than DDP and 2x less than the previous state-of-the-art Local ADAM. Furthermore, unlike previous heuristic approaches, DES-LOC is suited for practical training scenarios prone to system failures. DES-LOC offers a scalable, bandwidth-efficient, and fault-tolerant solution for foundation model training.
Convergence of Clipped-SGD for Convex $(L_0,L_1)$-Smooth Optimization with Heavy-Tailed Noise
May 27, 2025

Gradient clipping is a widely used technique in Machine Learning and Deep Learning (DL), known for its effectiveness in mitigating the impact of heavy-tailed noise, which frequently arises in the training of large language models. Additionally, first-order methods with clipping, such as Clip-SGD, exhibit stronger convergence guarantees than SGD under the $(L_0,L_1)$-smoothness assumption, a property observed in many DL tasks. However, the high-probability convergence of Clip-SGD under both assumptions -- heavy-tailed noise and $(L_0,L_1)$-smoothness -- has not been fully addressed in the literature. In this paper, we bridge this critical gap by establishing the first high-probability convergence bounds for Clip-SGD applied to convex $(L_0,L_1)$-smooth optimization with heavy-tailed noise. Our analysis extends prior results by recovering known bounds for the deterministic case and the stochastic setting with $L_1 = 0$ as special cases. Notably, our rates avoid exponentially large factors and do not rely on restrictive sub-Gaussian noise assumptions, significantly broadening the applicability of gradient clipping.
Fishing For Cheap And Efficient Pruners At Initialization
Feb 17, 2025Pruning offers a promising solution to mitigate the associated costs and environmental impact of deploying large deep neural networks (DNNs). Traditional approaches rely on computationally expensive trained models or time-consuming iterative prune-retrain cycles, undermining their utility in resource-constrained settings. To address this issue, we build upon the established principles of saliency (LeCun et al., 1989) and connection sensitivity (Lee et al., 2018) to tackle the challenging problem of one-shot pruning neural networks (NNs) before training (PBT) at initialization. We introduce Fisher-Taylor Sensitivity (FTS), a computationally cheap and efficient pruning criterion based on the empirical Fisher Information Matrix (FIM) diagonal, offering a viable alternative for integrating first- and second-order information to identify a model's structurally important parameters. Although the FIM-Hessian equivalency only holds for convergent models that maximize the likelihood, recent studies (Karakida et al., 2019) suggest that, even at initialization, the FIM captures essential geometric information of parameters in overparameterized NNs, providing the basis for our method. Finally, we demonstrate empirically that layer collapse, a critical limitation of data-dependent pruning methodologies, is easily overcome by pruning within a single training epoch after initialization. We perform experiments on ResNet18 and VGG19 with CIFAR-10 and CIFAR-100, widely used benchmarks in pruning research. Our method achieves competitive performance against state-of-the-art techniques for one-shot PBT, even under extreme sparsity conditions. Our code is made available to the public.
Revisiting LocalSGD and SCAFFOLD: Improved Rates and Missing Analysis
Jan 08, 2025

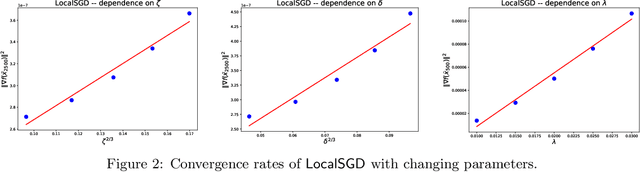

LocalSGD and SCAFFOLD are widely used methods in distributed stochastic optimization, with numerous applications in machine learning, large-scale data processing, and federated learning. However, rigorously establishing their theoretical advantages over simpler methods, such as minibatch SGD (MbSGD), has proven challenging, as existing analyses often rely on strong assumptions, unrealistic premises, or overly restrictive scenarios. In this work, we revisit the convergence properties of LocalSGD and SCAFFOLD under a variety of existing or weaker conditions, including gradient similarity, Hessian similarity, weak convexity, and Lipschitz continuity of the Hessian. Our analysis shows that (i) LocalSGD achieves faster convergence compared to MbSGD for weakly convex functions without requiring stronger gradient similarity assumptions; (ii) LocalSGD benefits significantly from higher-order similarity and smoothness; and (iii) SCAFFOLD demonstrates faster convergence than MbSGD for a broader class of non-quadratic functions. These theoretical insights provide a clearer understanding of the conditions under which LocalSGD and SCAFFOLD outperform MbSGD.
Generalizing in Net-Zero Microgrids: A Study with Federated PPO and TRPO
Dec 30, 2024This work addresses the challenge of optimal energy management in microgrids through a collaborative and privacy-preserving framework. We propose the FedTRPO methodology, which integrates Federated Learning (FL) and Trust Region Policy Optimization (TRPO) to manage distributed energy resources (DERs) efficiently. Using a customized version of the CityLearn environment and synthetically generated data, we simulate designed net-zero energy scenarios for microgrids composed of multiple buildings. Our approach emphasizes reducing energy costs and carbon emissions while ensuring privacy. Experimental results demonstrate that FedTRPO is comparable with state-of-the-art federated RL methodologies without hyperparameter tunning. The proposed framework highlights the feasibility of collaborative learning for achieving optimal control policies in energy systems, advancing the goals of sustainable and efficient smart grids.
Methods with Local Steps and Random Reshuffling for Generally Smooth Non-Convex Federated Optimization
Dec 03, 2024Non-convex Machine Learning problems typically do not adhere to the standard smoothness assumption. Based on empirical findings, Zhang et al. (2020b) proposed a more realistic generalized $(L_0, L_1)$-smoothness assumption, though it remains largely unexplored. Many existing algorithms designed for standard smooth problems need to be revised. However, in the context of Federated Learning, only a few works address this problem but rely on additional limiting assumptions. In this paper, we address this gap in the literature: we propose and analyze new methods with local steps, partial participation of clients, and Random Reshuffling without extra restrictive assumptions beyond generalized smoothness. The proposed methods are based on the proper interplay between clients' and server's stepsizes and gradient clipping. Furthermore, we perform the first analysis of these methods under the Polyak-{\L} ojasiewicz condition. Our theory is consistent with the known results for standard smooth problems, and our experimental results support the theoretical insights.
FRUGAL: Memory-Efficient Optimization by Reducing State Overhead for Scalable Training
Nov 12, 2024With the increase in the number of parameters in large language models, the process of pre-training and fine-tuning increasingly demands larger volumes of GPU memory. A significant portion of this memory is typically consumed by the optimizer state. To overcome this challenge, recent approaches such as low-rank adaptation (LoRA (Hu et al., 2021)), low-rank gradient projection (GaLore (Zhao et al., 2024)), and blockwise optimization (BAdam (Luo et al., 2024)) have been proposed. However, in all these algorithms, the $\textit{effective rank of the weight updates remains low-rank}$, which can lead to a substantial loss of information from the gradient. This loss can be critically important, especially during the pre-training stage. In this paper, we introduce $\texttt{FRUGAL}$ ($\textbf{F}$ull-$\textbf{R}$ank $\textbf{U}$pdates with $\textbf{G}$r$\textbf{A}$dient sp$\textbf{L}$itting), a new memory-efficient optimization framework. $\texttt{FRUGAL}$ leverages gradient splitting to perform low-dimensional updates using advanced algorithms (such as Adam), while updates along the remaining directions are executed via state-free methods like SGD or signSGD (Bernstein et al., 2018). Our framework can be integrated with various low-rank update selection techniques, including GaLore and BAdam. We provide theoretical convergence guarantees for our framework when using SGDM for low-dimensional updates and SGD for state-free updates. Additionally, our method consistently outperforms concurrent approaches across various fixed memory budgets, achieving state-of-the-art results in pre-training and fine-tuning tasks while balancing memory efficiency and performance metrics.