 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting LocalSGD and SCAFFOLD: Improved Rates and Missing Analysis
Jan 08, 2025


LocalSGD and SCAFFOLD are widely used methods in distributed stochastic optimization, with numerous applications in machine learning, large-scale data processing, and federated learning. However, rigorously establishing their theoretical advantages over simpler methods, such as minibatch SGD (MbSGD), has proven challenging, as existing analyses often rely on strong assumptions, unrealistic premises, or overly restrictive scenarios. In this work, we revisit the convergence properties of LocalSGD and SCAFFOLD under a variety of existing or weaker conditions, including gradient similarity, Hessian similarity, weak convexity, and Lipschitz continuity of the Hessian. Our analysis shows that (i) LocalSGD achieves faster convergence compared to MbSGD for weakly convex functions without requiring stronger gradient similarity assumptions; (ii) LocalSGD benefits significantly from higher-order similarity and smoothness; and (iii) SCAFFOLD demonstrates faster convergence than MbSGD for a broader class of non-quadratic functions. These theoretical insights provide a clearer understanding of the conditions under which LocalSGD and SCAFFOLD outperform MbSGD.
Communication-Efficient Gradient Descent-Accent Methods for Distributed Variational Inequalities: Unified Analysis and Local Updates
Jun 08, 2023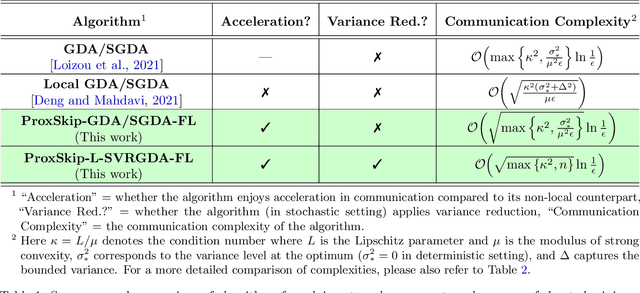
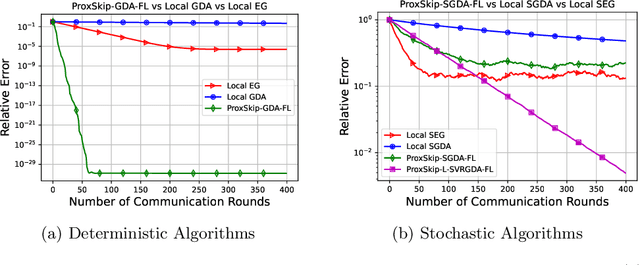

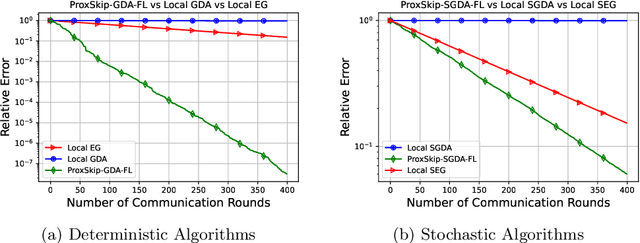
Distributed and federated learning algorithms and techniques associated primarily with minimization problems. However, with the increase of minimax optimization and variational inequality problems in machine learning, the necessity of designing efficient distributed/federated learning approaches for these problems is becoming more apparent. In this paper, we provide a unified convergence analysis of communication-efficient local training methods for distributed variational inequality problems (VIPs). Our approach is based on a general key assumption on the stochastic estimates that allows us to propose and analyze several novel local training algorithms under a single framework for solving a class of structured non-monotone VIPs. We present the first local gradient descent-accent algorithms with provable improved communication complexity for solving distributed variational inequalities on heterogeneous data. The general algorithmic framework recovers state-of-the-art algorithms and their sharp convergence guarantees when the setting is specialized to minimization or minimax optimization problems. Finally, we demonstrate the strong performance of the proposed algorithms compared to state-of-the-art methods when solving federated minimax optimization problems.
Decentralized Local Stochastic Extra-Gradient for Variational Inequalities
Jun 15, 2021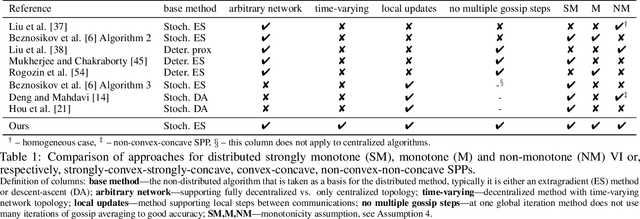
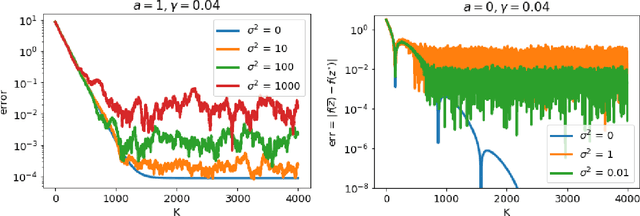
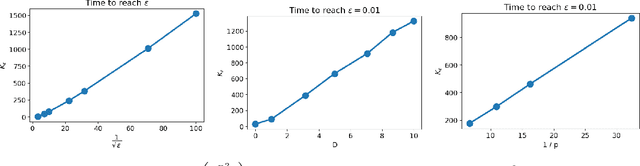
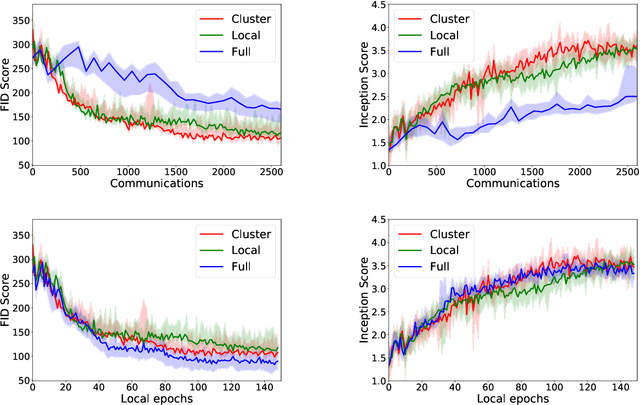
We consider decentralized stochastic variational inequalities where the problem data is distributed across many participating devices (heterogeneous, or non-IID data setting). We propose a novel method - based on stochastic extra-gradient - where participating devices can communicate over arbitrary, possibly time-varying network topologies. This covers both the fully decentralized optimization setting and the centralized topologies commonly used in Federated Learning. Our method further supports multiple local updates on the workers for reducing the communication frequency between workers. We theoretically analyze the proposed scheme in the strongly monotone, monotone and non-monotone setting. As a special case, our method and analysis apply in particular to decentralized stochastic min-max problems which are being studied with increased interest in Deep Learning. For example, the training objective of Generative Adversarial Networks (GANs) are typically saddle point problems and the decentralized training of GANs has been reported to be extremely challenging. While SOTA techniques rely on either repeated gossip rounds or proximal updates, we alleviate both of these requirements. Experimental results for decentralized GAN demonstrate the effectiveness of our proposed algorithm.