 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeByzantine Cheap Talk: Adversarial Resilience and Topology Effects in LLM Coordination Games
Jun 05, 2026Multi-agent LLM systems increasingly rely on communication protocols for coordination, yet their robustness under adversarial and structural constraints remains poorly understood. Building on prior work showing that cheap-talk channels enable cooperation in LLM coordination games, we investigate two vulnerability classes in a 4-player Stag Hunt across six model families and 720 trials. First, when Byzantine agents signal cooperation but defect, non-Byzantine agents detect the betrayal within one round yet fail to adapt collectively: a substantial fraction continue cooperating despite repeated exploitation, unable to recover coordination due to the game's unanimity payoff structure. Second, explicitly restricting communication topology collapses cooperation, while applying identical restrictions silently preserves near-perfect cooperation. This establishes that coordination failure stems from agents' meta-reasoning about hidden information, not information loss itself. We identify two stable behavioral archetypes that replicate across all model cohorts: Defection-Prone models that switch permanently after betrayal, and Cooperation-Persistent models that continue cooperating at significant individual cost. These findings reveal concrete security vulnerabilities: communication channels can be exploited as adversarial injection vectors, and disclosing network topology to agents can degrade coordination even without any adversary present.
Dual Advantage Fields
Jun 02, 2026Offline goal-conditioned reinforcement learning requires both long-horizon reachability estimates and local action comparisons. Dual goal representations provide value fields that capture global goal reachability, but they do not directly specify which action should be preferred at a given state. We propose Dual Advantage Fields, a policy-extraction method that turns a bilinear dual value model into a local advantage signal. Under bilinear dual parameterization, the goal embedding is the gradient of the value field with respect to the state representation. DAF learns an action-effect model that predicts the discounted feature displacement induced by an action and scores actions by the alignment between this displacement and the goal direction. In the realizable case, this score equals the goal-conditioned Bellman advantage, yielding a standard local policy-improvement guarantee. On OGBench locomotion, manipulation, and puzzle tasks, DAF improves aggregate RLiable metrics and performs strongly in settings where locally correct actions differ from direct movement toward the final goal.
Convex Compositional Reasoning Models
May 25, 2026Compositional energy-based models can generalize to larger combinatorial reasoning problems by reusing a learned factor energy across many local constraints. In our paper, we show that a key bottleneck in compositional reasoning is not composition itself, but the non-convex geometry of the learned energy landscape. To solve this problem, we introduce Convex Compositional Energy Minimization (CCEM), a framework that parameterizes each factor with an input-convex neural network and optimizes the composed energy over a tight convex relaxation of the feasible set. Because convexity is preserved under summation, the global relaxed objective remains convex, enabling deterministic projected first-order optimization. CCEM is trained in two stages: factor-level contrastive learning to shape local energy basins, followed by end-to-end refinement through an unrolled projected solver. Our experiments show that our models trained on small subproblems or a single problem size transfer to larger instances without retraining.
LionMuon: Alternating Spectral and Sign Descent for Efficient Training
May 19, 2026In large-scale optimization, the cheapness and effectiveness of update steps are the most crucial factors for a successful optimizer. Sign-based optimizers like Lion or Signum produce cheap per-step updates, whereas Muon's spectral matrix-sign update gives a much stronger direction at a substantially higher per-step cost. In this work, we propose LionMuon, which retains the effectiveness of Muon steps while considerably cutting the averaged iteration cost, similar to sign-based methods. It alternates between Lion's and Muon's updates on a fixed period P, sharing a single dual-EMA momentum buffer between them. The optimizer state memory therefore matches Lion and is exactly half of AdamW's. A simpler single-EMA variant, SignMuon, by itself already outperforms pure Muon. At P = 2, LionMuon Pareto-dominates Muon, Lion, Signum, and AdamW on every dataset and architecture we tested at 124M model size, reaching lower validation loss at lower compute, and the same advantage persists at 355M and 720M scale. On the theory side, we prove sharp complexity bounds under heavy-tailed noise which are governed by period-averaged smoothness and noise that interpolate between Muon's and Lion's constants. These bounds predict the compute-optimal period and the conditions under which LionMuon outruns Muon and Lion. Code: https://github.com/brain-lab-research/lion-muon
Gradient Clipping Beyond Vector Norms: A Spectral Approach for Matrix-Valued Parameters
May 12, 2026Gradient clipping is a standard safeguard for training neural networks under noisy, heavy-tailed stochastic gradients; yet, most clipping rules treat all parameters as vectors and ignore the matrix structure of modern architectures. We show empirically that data outliers often amplify only a small number of leading singular values in layer-wise gradient matrices, while the rest of the spectrum remains largely unchanged. Motivated by this phenomenon, we propose spectral clipping, which stabilizes training by clamping singular values that exceed a threshold while preserving the singular directions. This framework generalizes classical gradient norm clipping and can be easily integrated into existing optimizers. We provide a convergence analysis for non-convex optimization with spectrally clipped SGD, yielding the optimal $\mathcal{O}\left(K^{\frac{2 - 2α}{3α- 2}}\right)$ rate for heavy-tailed noise. To minimize hyperparameter tuning, we introduce layer-wise adaptive thresholds based on moving averages or sliding-window quantiles of the top singular values. Finally, we develop efficient implementations that clip only the top $r$ singular values via randomized truncated SVD, avoiding full decompositions for large layers. We demonstrate competitive performance across synthetic heavy-tailed settings and neural network training tasks.
Byzantine-Robust Optimization under $(L_0, L_1)$-Smoothness
Mar 12, 2026We consider distributed optimization under Byzantine attacks in the presence of $(L_0,L_1)$-smoothness, a generalization of standard $L$-smoothness that captures functions with state-dependent gradient Lipschitz constants. We propose Byz-NSGDM, a normalized stochastic gradient descent method with momentum that achieves robustness against Byzantine workers while maintaining convergence guarantees. Our algorithm combines momentum normalization with Byzantine-robust aggregation enhanced by Nearest Neighbor Mixing (NNM) to handle both the challenges posed by $(L_0,L_1)$-smoothness and Byzantine adversaries. We prove that Byz-NSGDM achieves a convergence rate of $O(K^{-1/4})$ up to a Byzantine bias floor proportional to the robustness coefficient and gradient heterogeneity. Experimental validation on heterogeneous MNIST classification, synthetic $(L_0,L_1)$-smooth optimization, and character-level language modeling with a small GPT model demonstrates the effectiveness of our approach against various Byzantine attack strategies. An ablation study further shows that Byz-NSGDM is robust across a wide range of momentum and learning rate choices.
Beyond SGD, Without SVD: Proximal Subspace Iteration LoRA with Diagonal Fractional K-FAC
Feb 18, 2026Low-Rank Adaptation (LoRA) fine-tunes large models by learning low-rank updates on top of frozen weights, dramatically reducing trainable parameters and memory. In this work, we address the gap between training with full steps with low-rank projections (SVDLoRA) and LoRA fine-tuning. We propose LoRSum, a memory-efficient subroutine that closes this gap for gradient descent by casting LoRA optimization as a proximal sub-problem and solving it efficiently with alternating least squares updates, which we prove to be an implicit block power method. We recover several recently proposed preconditioning methods for LoRA as special cases, and show that LoRSum can also be used for updating a low-rank momentum. In order to address full steps with preconditioned gradient descent, we propose a scaled variant of LoRSum that uses structured metrics such as K-FAC and Shampoo, and we show that storing the diagonal of these metrics still allows them to perform well while remaining memory-efficient. Experiments on a synthetic task, CIFAR-100, and language-model fine-tuning on GLUE, SQuAD v2, and WikiText-103, show that our method can match or improve LoRA baselines given modest compute overhead, while avoiding full-matrix SVD projections and retaining LoRA-style parameter efficiency.
Exploring New Frontiers in Vertical Federated Learning: the Role of Saddle Point Reformulation
Feb 17, 2026The objective of Vertical Federated Learning (VFL) is to collectively train a model using features available on different devices while sharing the same users. This paper focuses on the saddle point reformulation of the VFL problem via the classical Lagrangian function. We first demonstrate how this formulation can be solved using deterministic methods. More importantly, we explore various stochastic modifications to adapt to practical scenarios, such as employing compression techniques for efficient information transmission, enabling partial participation for asynchronous communication, and utilizing coordinate selection for faster local computation. We show that the saddle point reformulation plays a key role and opens up possibilities to use mentioned extension that seem to be impossible in the standard minimization formulation. Convergence estimates are provided for each algorithm, demonstrating their effectiveness in addressing the VFL problem. Additionally, alternative reformulations are investigated, and numerical experiments are conducted to validate performance and effectiveness of the proposed approach.
Where Does Warm-Up Come From? Adaptive Scheduling for Norm-Constrained Optimizers
Feb 05, 2026We study adaptive learning rate scheduling for norm-constrained optimizers (e.g., Muon and Lion). We introduce a generalized smoothness assumption under which local curvature decreases with the suboptimality gap and empirically verify that this behavior holds along optimization trajectories. Under this assumption, we establish convergence guarantees under an appropriate choice of learning rate, for which warm-up followed by decay arises naturally from the proof rather than being imposed heuristically. Building on this theory, we develop a practical learning rate scheduler that relies only on standard hyperparameters and adapts the warm-up duration automatically at the beginning of training. We evaluate this method on large language model pretraining with LLaMA architectures and show that our adaptive warm-up selection consistently outperforms or at least matches the best manually tuned warm-up schedules across all considered setups, without additional hyperparameter search. Our source code is available at https://github.com/brain-lab-research/llm-baselines/tree/warmup
Tractable Probabilistic Models for Investment Planning
Nov 17, 2025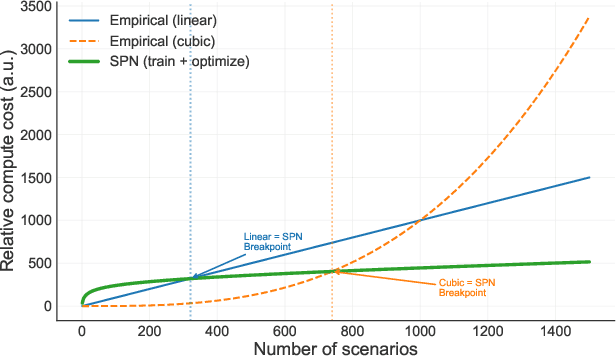
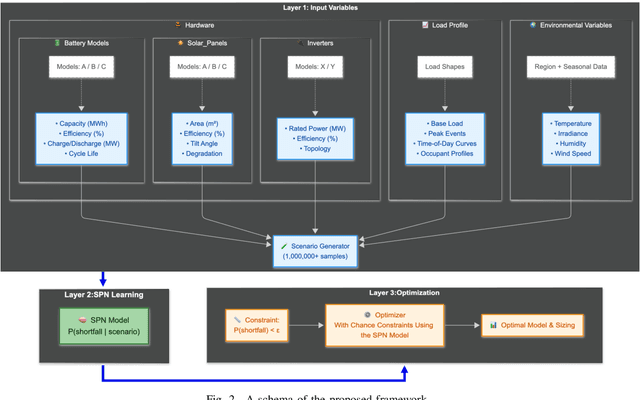
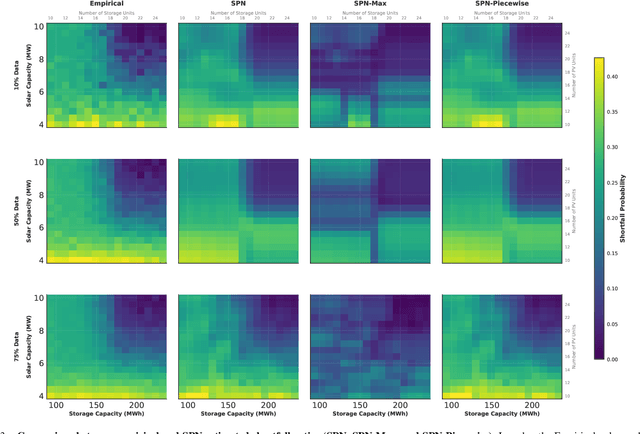
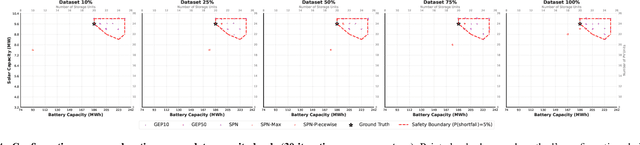
Investment planning in power utilities, such as generation and transmission expansion, requires decade-long forecasts under profound uncertainty. Forecasting of energy mix and energy use decades ahead is nontrivial. Classical approaches focus on generating a finite number of scenarios (modeled as a mixture of Diracs in statistical theory terms), which limits insight into scenario-specific volatility and hinders robust decision-making. We propose an alternative using tractable probabilistic models (TPMs), particularly sum-product networks (SPNs). These models enable exact, scalable inference of key quantities such as scenario likelihoods, marginals, and conditional probabilities, supporting robust scenario expansion and risk assessment. This framework enables direct embedding of chance-constrained optimization into investment planning, enforcing safety or reliability with prescribed confidence levels. TPMs allow both scenario analysis and volatility quantification by compactly representing high-dimensional uncertainties. We demonstrate the approach's effectiveness through a representative power system planning case study, illustrating computational and reliability advantages over traditional scenario-based models.