 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistance-Aware Muon: Adaptive Step Scaling for Normalized Optimization
May 18, 2026Muon and related normalized optimizers decouple the choice of update direction from the choice of step scale, but their practical performance remains sensitive to the scale of the normalized step. We study adaptive scaling rules for Muon in general norm geometries and develop three complementary algorithms. For smooth non-convex objectives, we introduce Distance-Adaptive Muon, whose trust-region radius is set from the radius explored by the trajectory, and prove a stationarity guarantee under a bounded-trajectory assumption. We then turn to star-convex objectives, a tractable model of the favorable global geometry often used to reason about the empirical loss landscapes of deep neural networks, where objective-gap guarantees are possible. In this setting, we first introduce Scale-Calibrated Muon, which keeps Muon's exponential moving average but sets the step length from a local descent certificate computed from the current gradient and momentum. For this method, we prove a last-iterate O(1/T) objective-gap bound under a bounded initial sublevel-set assumption, where the corresponding radius parameter appears only in the analysis and not in the algorithm. Finally, we develop Distance-Free Muon, a recentered trust-region method that uses a scalar distance certificate and a majorized one-dimensional search to select the trust-region radius without requiring the unknown distance from the initialization to a global minimizer. Experiments on Transformer language modeling (GPT-124M/WikiText-103) and image classification (ViT-Tiny/CIFAR-100) show that the proposed adaptive scaling rules reduce sensitivity to manual scale tuning and match or improve tuned fixed-scale Muon baselines under the tested budgets.
Communication-Efficient Gluon in Federated Learning
Apr 12, 2026Recent developments have shown that Muon-type optimizers based on linear minimization oracles (LMOs) over non-Euclidean norm balls have the potential to get superior practical performance than Adam-type methods in the training of large language models. Since large-scale neural networks are trained across massive machines, communication cost becomes the bottleneck. To address this bottleneck, we investigate Gluon, which is an extension of Muon under the more general layer-wise $(L^0, L^1)$-smooth setting, with both unbiased and contraction compressors. In order to reduce the compression error, we employ the variance reduced technique in SARAH in our compressed methods. The convergence rates and improved communication cost are achieved under certain conditions. As a byproduct, a new variance reduced algorithm with faster convergence rate than Gluon is obtained. We also incorporate momentum variance reduction (MVR) to these compressed algorithms and comparable communication cost is derived under weaker conditions when $L_i^1 \neq 0$. Finally, several numerical experiments are conducted to verify the superior performance of our compressed algorithms in terms of communication cost.
Byzantine-Robust and Differentially Private Federated Optimization under Weaker Assumptions
Mar 24, 2026Federated Learning (FL) enables heterogeneous clients to collaboratively train a shared model without centralizing their raw data, offering an inherent level of privacy. However, gradients and model updates can still leak sensitive information, while malicious servers may mount adversarial attacks such as Byzantine manipulation. These vulnerabilities highlight the need to address differential privacy (DP) and Byzantine robustness within a unified framework. Existing approaches, however, often rely on unrealistic assumptions such as bounded gradients, require auxiliary server-side datasets, or fail to provide convergence guarantees. We address these limitations by proposing Byz-Clip21-SGD2M, a new algorithm that integrates robust aggregation with double momentum and carefully designed clipping. We prove high-probability convergence guarantees under standard $L$-smoothness and $σ$-sub-Gaussian gradient noise assumptions, thereby relaxing conditions that dominate prior work. Our analysis recovers state-of-the-art convergence rates in the absence of adversaries and improves utility guarantees under Byzantine and DP settings. Empirical evaluations on CNN and MLP models trained on MNIST further validate the effectiveness of our approach.
First Provable Guarantees for Practical Private FL: Beyond Restrictive Assumptions
Dec 25, 2025Federated Learning (FL) enables collaborative training on decentralized data. Differential privacy (DP) is crucial for FL, but current private methods often rely on unrealistic assumptions (e.g., bounded gradients or heterogeneity), hindering practical application. Existing works that relax these assumptions typically neglect practical FL features, including multiple local updates and partial client participation. We introduce Fed-$α$-NormEC, the first differentially private FL framework providing provable convergence and DP guarantees under standard assumptions while fully supporting these practical features. Fed-$α$-NormE integrates local updates (full and incremental gradient steps), separate server and client stepsizes, and, crucially, partial client participation, which is essential for real-world deployment and vital for privacy amplification. Our theoretical guarantees are corroborated by experiments on private deep learning tasks.
Improved Convergence in Parameter-Agnostic Error Feedback through Momentum
Nov 18, 2025Communication compression is essential for scalable distributed training of modern machine learning models, but it often degrades convergence due to the noise it introduces. Error Feedback (EF) mechanisms are widely adopted to mitigate this issue of distributed compression algorithms. Despite their popularity and training efficiency, existing distributed EF algorithms often require prior knowledge of problem parameters (e.g., smoothness constants) to fine-tune stepsizes. This limits their practical applicability especially in large-scale neural network training. In this paper, we study normalized error feedback algorithms that combine EF with normalized updates, various momentum variants, and parameter-agnostic, time-varying stepsizes, thus eliminating the need for problem-dependent tuning. We analyze the convergence of these algorithms for minimizing smooth functions, and establish parameter-agnostic complexity bounds that are close to the best-known bounds with carefully-tuned problem-dependent stepsizes. Specifically, we show that normalized EF21 achieve the convergence rate of near ${O}(1/T^{1/4})$ for Polyak's heavy-ball momentum, ${O}(1/T^{2/7})$ for Iterative Gradient Transport (IGT), and ${O}(1/T^{1/3})$ for STORM and Hessian-corrected momentum. Our results hold with decreasing stepsizes and small mini-batches. Finally, our empirical experiments confirm our theoretical insights.
Methods with Local Steps and Random Reshuffling for Generally Smooth Non-Convex Federated Optimization
Dec 03, 2024Non-convex Machine Learning problems typically do not adhere to the standard smoothness assumption. Based on empirical findings, Zhang et al. (2020b) proposed a more realistic generalized $(L_0, L_1)$-smoothness assumption, though it remains largely unexplored. Many existing algorithms designed for standard smooth problems need to be revised. However, in the context of Federated Learning, only a few works address this problem but rely on additional limiting assumptions. In this paper, we address this gap in the literature: we propose and analyze new methods with local steps, partial participation of clients, and Random Reshuffling without extra restrictive assumptions beyond generalized smoothness. The proposed methods are based on the proper interplay between clients' and server's stepsizes and gradient clipping. Furthermore, we perform the first analysis of these methods under the Polyak-{\L} ojasiewicz condition. Our theory is consistent with the known results for standard smooth problems, and our experimental results support the theoretical insights.
Randomized Asymmetric Chain of LoRA: The First Meaningful Theoretical Framework for Low-Rank Adaptation
Oct 10, 2024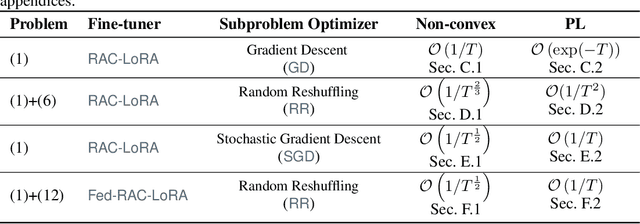

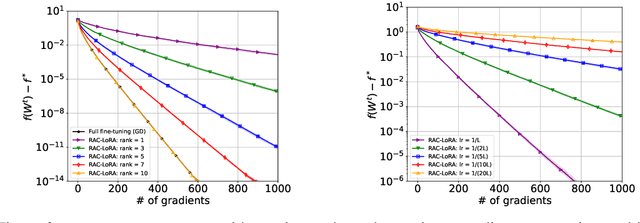
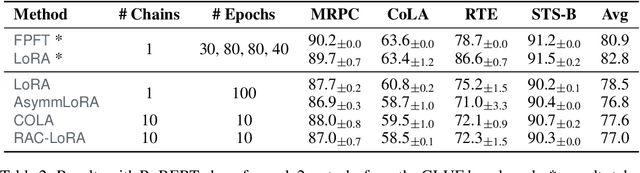
Fine-tuning has become a popular approach to adapting large foundational models to specific tasks. As the size of models and datasets grows, parameter-efficient fine-tuning techniques are increasingly important. One of the most widely used methods is Low-Rank Adaptation (LoRA), with adaptation update expressed as the product of two low-rank matrices. While LoRA was shown to possess strong performance in fine-tuning, it often under-performs when compared to full-parameter fine-tuning (FPFT). Although many variants of LoRA have been extensively studied empirically, their theoretical optimization analysis is heavily under-explored. The starting point of our work is a demonstration that LoRA and its two extensions, Asymmetric LoRA and Chain of LoRA, indeed encounter convergence issues. To address these issues, we propose Randomized Asymmetric Chain of LoRA (RAC-LoRA) -- a general optimization framework that rigorously analyzes the convergence rates of LoRA-based methods. Our approach inherits the empirical benefits of LoRA-style heuristics, but introduces several small but important algorithmic modifications which turn it into a provably convergent method. Our framework serves as a bridge between FPFT and low-rank adaptation. We provide provable guarantees of convergence to the same solution as FPFT, along with the rate of convergence. Additionally, we present a convergence analysis for smooth, non-convex loss functions, covering gradient descent, stochastic gradient descent, and federated learning settings. Our theoretical findings are supported by experimental results.
MicroAdam: Accurate Adaptive Optimization with Low Space Overhead and Provable Convergence
May 24, 2024We propose a new variant of the Adam optimizer [Kingma and Ba, 2014] called MICROADAM that specifically minimizes memory overheads, while maintaining theoretical convergence guarantees. We achieve this by compressing the gradient information before it is fed into the optimizer state, thereby reducing its memory footprint significantly. We control the resulting compression error via a novel instance of the classical error feedback mechanism from distributed optimization [Seide et al., 2014, Alistarh et al., 2018, Karimireddy et al., 2019] in which the error correction information is itself compressed to allow for practical memory gains. We prove that the resulting approach maintains theoretical convergence guarantees competitive to those of AMSGrad, while providing good practical performance. Specifically, we show that MICROADAM can be implemented efficiently on GPUs: on both million-scale (BERT) and billion-scale (LLaMA) models, MicroAdam provides practical convergence competitive to that of the uncompressed Adam baseline, with lower memory usage and similar running time. Our code is available at https://github.com/IST-DASLab/MicroAdam.
Streamlining in the Riemannian Realm: Efficient Riemannian Optimization with Loopless Variance Reduction
Mar 11, 2024
In this study, we investigate stochastic optimization on Riemannian manifolds, focusing on the crucial variance reduction mechanism used in both Euclidean and Riemannian settings. Riemannian variance-reduced methods usually involve a double-loop structure, computing a full gradient at the start of each loop. Determining the optimal inner loop length is challenging in practice, as it depends on strong convexity or smoothness constants, which are often unknown or hard to estimate. Motivated by Euclidean methods, we introduce the Riemannian Loopless SVRG (R-LSVRG) and PAGE (R-PAGE) methods. These methods replace the outer loop with probabilistic gradient computation triggered by a coin flip in each iteration, ensuring simpler proofs, efficient hyperparameter selection, and sharp convergence guarantees. Using R-PAGE as a framework for non-convex Riemannian optimization, we demonstrate its applicability to various important settings. For example, we derive Riemannian MARINA (R-MARINA) for distributed settings with communication compression, providing the best theoretical communication complexity guarantees for non-convex distributed optimization over Riemannian manifolds. Experimental results support our theoretical findings.
MAST: Model-Agnostic Sparsified Training
Nov 27, 2023We introduce a novel optimization problem formulation that departs from the conventional way of minimizing machine learning model loss as a black-box function. Unlike traditional formulations, the proposed approach explicitly incorporates an initially pre-trained model and random sketch operators, allowing for sparsification of both the model and gradient during training. We establish insightful properties of the proposed objective function and highlight its connections to the standard formulation. Furthermore, we present several variants of the Stochastic Gradient Descent (SGD) method adapted to the new problem formulation, including SGD with general sampling, a distributed version, and SGD with variance reduction techniques. We achieve tighter convergence rates and relax assumptions, bridging the gap between theoretical principles and practical applications, covering several important techniques such as Dropout and Sparse training. This work presents promising opportunities to enhance the theoretical understanding of model training through a sparsification-aware optimization approach.