 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRDO: Distributed Low-Rank Optimization with Infrequent Communication
Feb 04, 2026Distributed training of foundation models via $\texttt{DDP}$ is limited by interconnect bandwidth. While infrequent communication strategies reduce synchronization frequency, they remain bottlenecked by the memory and communication requirements of optimizer states. Low-rank optimizers can alleviate these constraints; however, in the local-update regime, workers lack access to the full-batch gradients required to compute low-rank projections, which degrades performance. We propose $\texttt{LoRDO}$, a principled framework unifying low-rank optimization with infrequent synchronization. We first demonstrate that, while global projections based on pseudo-gradients are theoretically superior, they permanently restrict the optimization trajectory to a low-rank subspace. To restore subspace exploration, we introduce a full-rank quasi-hyperbolic update. $\texttt{LoRDO}$ achieves near-parity with low-rank $\texttt{DDP}$ in language modeling and downstream tasks at model scales of $125$M--$720$M, while reducing communication by $\approx 10 \times$. Finally, we show that $\texttt{LoRDO}$ improves performance even more in very low-memory settings with small rank/batch size.
DASH: Faster Shampoo via Batched Block Preconditioning and Efficient Inverse-Root Solvers
Feb 02, 2026Shampoo is one of the leading approximate second-order optimizers: a variant of it has won the MLCommons AlgoPerf competition, and it has been shown to produce models with lower activation outliers that are easier to compress. Yet, applying Shampoo currently comes at the cost of significant computational slowdown, due to its expensive internal operations. In this paper, we take a significant step to address this shortcoming by proposing \method (for \textbf{D}istributed \textbf{A}ccelerated \textbf{SH}ampoo), a faster implementation of Distributed Shampoo based on two main new techniques: First, we show that preconditioner blocks can be stacked into 3D tensors to significantly improve GPU utilization; second, we introduce the Newton-DB iteration and the Chebyshev polynomial approximations as novel and faster approaches for computing the inverse matrix roots required by Shampoo. Along with these algorithmic contributions, we provide a first in-depth analysis of how matrix scaling critically affects Shampoo convergence. On the practical side, our GPU-aware implementation achieves up to $4.83\times$ faster optimizer steps compared to the well-optimized Distributed Shampoo, while Newton-DB attains the lowest validation perplexity per iteration among all tested methods. Our code is available at https://github.com/IST-DASLab/DASH.
Optimizers Qualitatively Alter Solutions And We Should Leverage This
Jul 16, 2025Due to the nonlinear nature of Deep Neural Networks (DNNs), one can not guarantee convergence to a unique global minimum of the loss when using optimizers relying only on local information, such as SGD. Indeed, this was a primary source of skepticism regarding the feasibility of DNNs in the early days of the field. The past decades of progress in deep learning have revealed this skepticism to be misplaced, and a large body of empirical evidence shows that sufficiently large DNNs following standard training protocols exhibit well-behaved optimization dynamics that converge to performant solutions. This success has biased the community to use convex optimization as a mental model for learning, leading to a focus on training efficiency, either in terms of required iteration, FLOPs or wall-clock time, when improving optimizers. We argue that, while this perspective has proven extremely fruitful, another perspective specific to DNNs has received considerably less attention: the optimizer not only influences the rate of convergence, but also the qualitative properties of the learned solutions. Restated, the optimizer can and will encode inductive biases and change the effective expressivity of a given class of models. Furthermore, we believe the optimizer can be an effective way of encoding desiderata in the learning process. We contend that the community should aim at understanding the biases of already existing methods, as well as aim to build new optimizers with the explicit intent of inducing certain properties of the solution, rather than solely judging them based on their convergence rates. We hope our arguments will inspire research to improve our understanding of how the learning process can impact the type of solution we converge to, and lead to a greater recognition of optimizers design as a critical lever that complements the roles of architecture and data in shaping model outcomes.
SVD-Free Low-Rank Adaptive Gradient Optimization for Large Language Models
May 23, 2025Low-rank optimization has emerged as a promising direction in training large language models (LLMs) to reduce the memory usage of adaptive optimizers by constraining learning to a lower-dimensional space. Prior work typically projects gradients of linear layers using approaches based on Singular Value Decomposition (SVD). However, applying SVD-based procedures individually to each layer in large models is computationally expensive and incurs additional memory costs due to storing the projection matrices. In this work, we propose a computationally efficient and conceptually simple two-step procedure to approximate SVD-based gradient projections into lower-dimensional spaces. First, we construct a complete orthogonal basis using predefined orthogonal matrices of the Discrete Cosine Transform (DCT). Second, we adaptively select basis columns based on their alignment with the gradient of each layer. Each projection matrix in our method is obtained via a single matrix multiplication followed by a lightweight sorting step to identify the most relevant basis vectors. Due to the predefined nature of the orthogonal bases, they are computed once at the start of training. During training, we store only the indices of the selected columns, avoiding the need to store full projection matrices for each layer. Our numerical experiments on both pre-training and fine-tuning tasks demonstrate the effectiveness of our dual strategy in approximating optimal low-rank projections, matching the performance of costly SVD-based methods while achieving faster runtime and reduced memory usage.
LDAdam: Adaptive Optimization from Low-Dimensional Gradient Statistics
Oct 21, 2024We introduce LDAdam, a memory-efficient optimizer for training large models, that performs adaptive optimization steps within lower dimensional subspaces, while consistently exploring the full parameter space during training. This strategy keeps the optimizer's memory footprint to a fraction of the model size. LDAdam relies on a new projection-aware update rule for the optimizer states that allows for transitioning between subspaces, i.e., estimation of the statistics of the projected gradients. To mitigate the errors due to low-rank projection, LDAdam integrates a new generalized error feedback mechanism, which explicitly accounts for both gradient and optimizer state compression. We prove the convergence of LDAdam under standard assumptions, and show that LDAdam allows for accurate and efficient fine-tuning and pre-training of language models.
The Iterative Optimal Brain Surgeon: Faster Sparse Recovery by Leveraging Second-Order Information
Aug 30, 2024The rising footprint of machine learning has led to a focus on imposing \emph{model sparsity} as a means of reducing computational and memory costs. For deep neural networks (DNNs), the state-of-the-art accuracy-vs-sparsity is achieved by heuristics inspired by the classical Optimal Brain Surgeon (OBS) framework~\citep{lecun90brain, hassibi1992second, hassibi1993optimal}, which leverages loss curvature information to make better pruning decisions. Yet, these results still lack a solid theoretical understanding, and it is unclear whether they can be improved by leveraging connections to the wealth of work on sparse recovery algorithms. In this paper, we draw new connections between these two areas and present new sparse recovery algorithms inspired by the OBS framework that comes with theoretical guarantees under reasonable assumptions and have strong practical performance. Specifically, our work starts from the observation that we can leverage curvature information in OBS-like fashion upon the projection step of classic iterative sparse recovery algorithms such as IHT. We show for the first time that this leads both to improved convergence bounds under standard assumptions. Furthermore, we present extensions of this approach to the practical task of obtaining accurate sparse DNNs, and validate it experimentally at scale for Transformer-based models on vision and language tasks.
MicroAdam: Accurate Adaptive Optimization with Low Space Overhead and Provable Convergence
May 24, 2024We propose a new variant of the Adam optimizer [Kingma and Ba, 2014] called MICROADAM that specifically minimizes memory overheads, while maintaining theoretical convergence guarantees. We achieve this by compressing the gradient information before it is fed into the optimizer state, thereby reducing its memory footprint significantly. We control the resulting compression error via a novel instance of the classical error feedback mechanism from distributed optimization [Seide et al., 2014, Alistarh et al., 2018, Karimireddy et al., 2019] in which the error correction information is itself compressed to allow for practical memory gains. We prove that the resulting approach maintains theoretical convergence guarantees competitive to those of AMSGrad, while providing good practical performance. Specifically, we show that MICROADAM can be implemented efficiently on GPUs: on both million-scale (BERT) and billion-scale (LLaMA) models, MicroAdam provides practical convergence competitive to that of the uncompressed Adam baseline, with lower memory usage and similar running time. Our code is available at https://github.com/IST-DASLab/MicroAdam.
Error Feedback Can Accurately Compress Preconditioners
Jun 16, 2023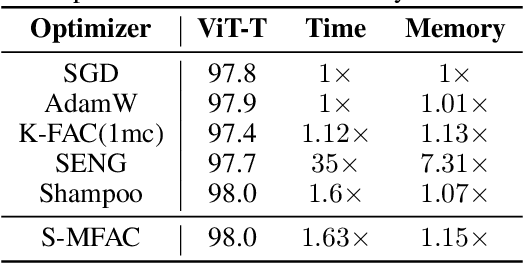
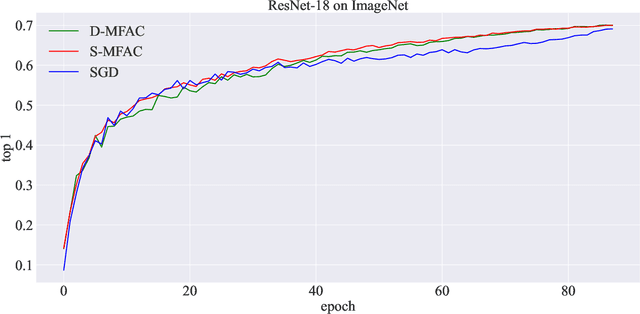
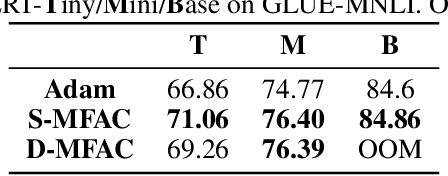
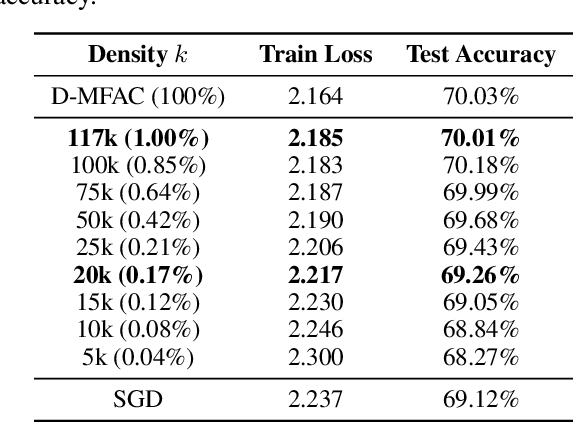
Leveraging second-order information at the scale of deep networks is one of the main lines of approach for improving the performance of current optimizers for deep learning. Yet, existing approaches for accurate full-matrix preconditioning, such as Full-Matrix Adagrad (GGT) or Matrix-Free Approximate Curvature (M-FAC) suffer from massive storage costs when applied even to medium-scale models, as they must store a sliding window of gradients, whose memory requirements are multiplicative in the model dimension. In this paper, we address this issue via an efficient and simple-to-implement error-feedback technique that can be applied to compress preconditioners by up to two orders of magnitude in practice, without loss of convergence. Specifically, our approach compresses the gradient information via sparsification or low-rank compression \emph{before} it is fed into the preconditioner, feeding the compression error back into future iterations. Extensive experiments on deep neural networks for vision show that this approach can compress full-matrix preconditioners by up to two orders of magnitude without impact on accuracy, effectively removing the memory overhead of full-matrix preconditioning for implementations of full-matrix Adagrad (GGT) and natural gradient (M-FAC). Our code is available at https://github.com/IST-DASLab/EFCP.