 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinistral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Voxtral
Jul 17, 2025We present Voxtral Mini and Voxtral Small, two multimodal audio chat models. Voxtral is trained to comprehend both spoken audio and text documents, achieving state-of-the-art performance across a diverse range of audio benchmarks, while preserving strong text capabilities. Voxtral Small outperforms a number of closed-source models, while being small enough to run locally. A 32K context window enables the model to handle audio files up to 40 minutes in duration and long multi-turn conversations. We also contribute three benchmarks for evaluating speech understanding models on knowledge and trivia. Both Voxtral models are released under Apache 2.0 license.
Magistral
Jun 12, 2025



We introduce Magistral, Mistral's first reasoning model and our own scalable reinforcement learning (RL) pipeline. Instead of relying on existing implementations and RL traces distilled from prior models, we follow a ground up approach, relying solely on our own models and infrastructure. Notably, we demonstrate a stack that enabled us to explore the limits of pure RL training of LLMs, present a simple method to force the reasoning language of the model, and show that RL on text data alone maintains most of the initial checkpoint's capabilities. We find that RL on text maintains or improves multimodal understanding, instruction following and function calling. We present Magistral Medium, trained for reasoning on top of Mistral Medium 3 with RL alone, and we open-source Magistral Small (Apache 2.0) which further includes cold-start data from Magistral Medium.
LDAdam: Adaptive Optimization from Low-Dimensional Gradient Statistics
Oct 21, 2024We introduce LDAdam, a memory-efficient optimizer for training large models, that performs adaptive optimization steps within lower dimensional subspaces, while consistently exploring the full parameter space during training. This strategy keeps the optimizer's memory footprint to a fraction of the model size. LDAdam relies on a new projection-aware update rule for the optimizer states that allows for transitioning between subspaces, i.e., estimation of the statistics of the projected gradients. To mitigate the errors due to low-rank projection, LDAdam integrates a new generalized error feedback mechanism, which explicitly accounts for both gradient and optimizer state compression. We prove the convergence of LDAdam under standard assumptions, and show that LDAdam allows for accurate and efficient fine-tuning and pre-training of language models.
MicroAdam: Accurate Adaptive Optimization with Low Space Overhead and Provable Convergence
May 24, 2024We propose a new variant of the Adam optimizer [Kingma and Ba, 2014] called MICROADAM that specifically minimizes memory overheads, while maintaining theoretical convergence guarantees. We achieve this by compressing the gradient information before it is fed into the optimizer state, thereby reducing its memory footprint significantly. We control the resulting compression error via a novel instance of the classical error feedback mechanism from distributed optimization [Seide et al., 2014, Alistarh et al., 2018, Karimireddy et al., 2019] in which the error correction information is itself compressed to allow for practical memory gains. We prove that the resulting approach maintains theoretical convergence guarantees competitive to those of AMSGrad, while providing good practical performance. Specifically, we show that MICROADAM can be implemented efficiently on GPUs: on both million-scale (BERT) and billion-scale (LLaMA) models, MicroAdam provides practical convergence competitive to that of the uncompressed Adam baseline, with lower memory usage and similar running time. Our code is available at https://github.com/IST-DASLab/MicroAdam.
Insights from the Future for Continual Learning
Jun 24, 2020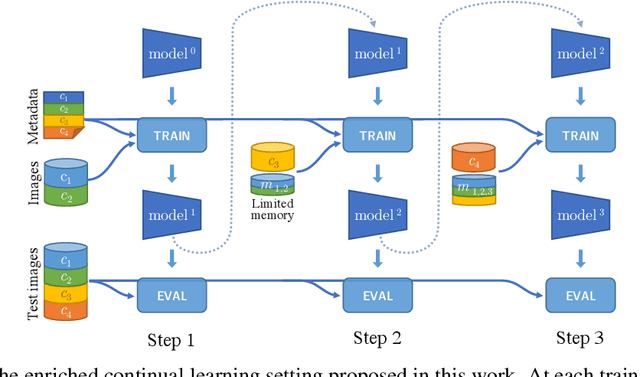
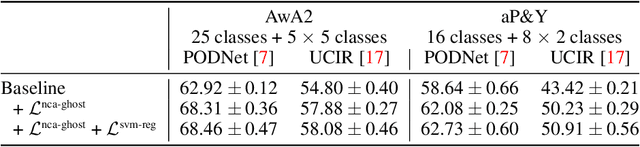

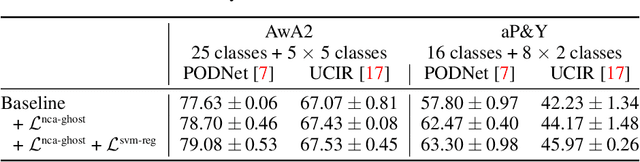
Continual learning aims to learn tasks sequentially, with (often severe) constraints on the storage of old learning samples, without suffering from catastrophic forgetting. In this work, we propose prescient continual learning, a novel experimental setting, to incorporate existing information about the classes, prior to any training data. Usually, each task in a traditional continual learning setting evaluates the model on present and past classes, the latter with a limited number of training samples. Our setting adds future classes, with no training samples at all. We introduce Ghost Model, a representation-learning-based model for continual learning using ideas from zero-shot learning. A generative model of the representation space in concert with a careful adjustment of the losses allows us to exploit insights from future classes to constraint the spatial arrangement of the past and current classes. Quantitative results on the AwA2 and aP\&Y datasets and detailed visualizations showcase the interest of this new setting and the method we propose to address it.
Small-Task Incremental Learning
Apr 28, 2020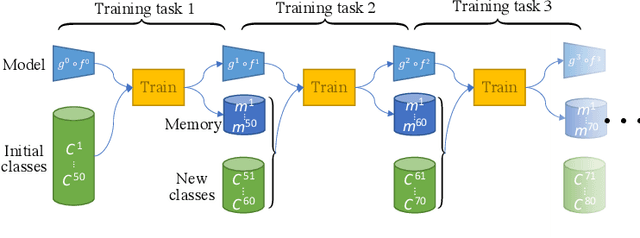
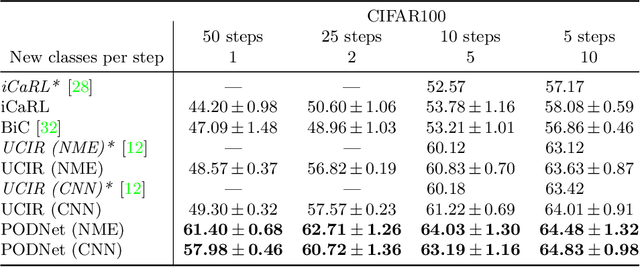

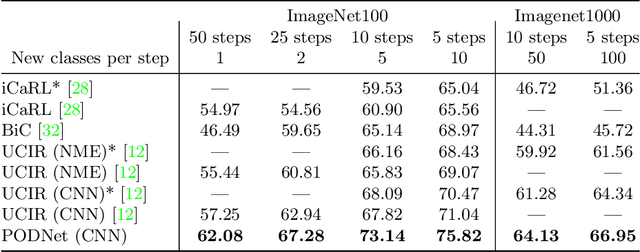
Lifelong learning has attracted much attention, but existing works still struggle to fight catastrophic forgetting and accumulate knowledge over long stretches of incremental learning. In this work, we propose PODNet, a model inspired by representation learning. By carefully balancing the compromise between remembering the old classes and learning new ones, PODNet fights catastrophic forgetting, even over very long runs of small incremental tasks-- a setting so far unexplored by current works. PODNet innovates on existing art with an efficient spatial-based distillation-loss applied throughout the model and a representation comprising multiple proxy vectors for each class. We validate those innovations thoroughly, comparing PODNet with three state-of-the-art models on three datasets: CIFAR100, ImageNet100, and ImageNet1000. Our results showcase a significant advantage of PODNet over existing art, with accuracy gains of 12.10, 4.83, and 2.85 percentage points, respectively. Code will be released at this address: https://github.com/arthurdouillard/incremental_learning.pytorch.
DualDis: Dual-Branch Disentangling with Adversarial Learning
Jun 03, 2019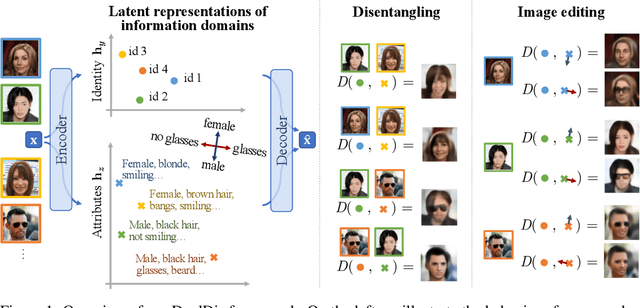
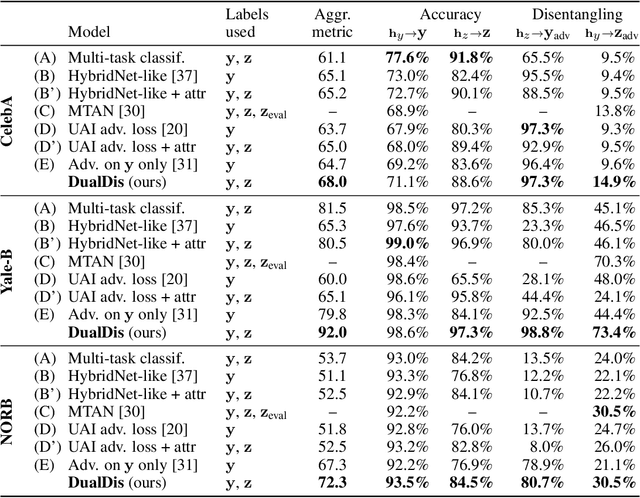
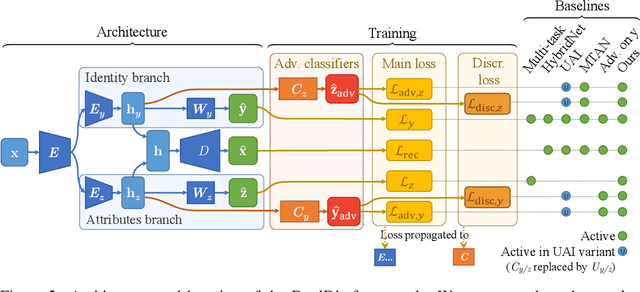

In computer vision, disentangling techniques aim at improving latent representations of images by modeling factors of variation. In this paper, we propose DualDis, a new auto-encoder-based framework that disentangles and linearizes class and attribute information. This is achieved thanks to a two-branch architecture forcing the separation of the two kinds of information, accompanied by a decoder for image reconstruction and generation. To effectively separate the information, we propose to use a combination of regular and adversarial classifiers to guide the two branches in specializing for class and attribute information respectively. We also investigate the possibility of using semi-supervised learning for an effective disentangling even using few labels. We leverage the linearization property of the latent spaces for semantic image editing and generation of new images. We validate our approach on CelebA, Yale-B and NORB by measuring the efficiency of information separation via classification metrics, visual image manipulation and data augmentation.
HybridNet: Classification and Reconstruction Cooperation for Semi-Supervised Learning
Jul 30, 2018
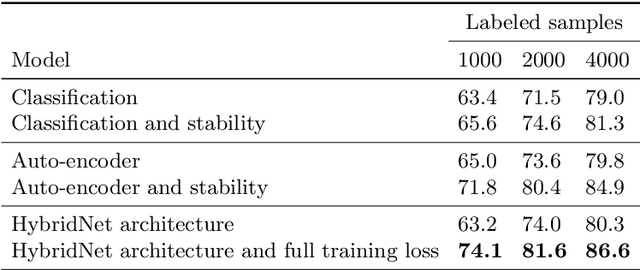


In this paper, we introduce a new model for leveraging unlabeled data to improve generalization performances of image classifiers: a two-branch encoder-decoder architecture called HybridNet. The first branch receives supervision signal and is dedicated to the extraction of invariant class-related representations. The second branch is fully unsupervised and dedicated to model information discarded by the first branch to reconstruct input data. To further support the expected behavior of our model, we propose an original training objective. It favors stability in the discriminative branch and complementarity between the learned representations in the two branches. HybridNet is able to outperform state-of-the-art results on CIFAR-10, SVHN and STL-10 in various semi-supervised settings. In addition, visualizations and ablation studies validate our contributions and the behavior of the model on both CIFAR-10 and STL-10 datasets.
SHADE: Information Based Regularization for Deep Learning
May 22, 2018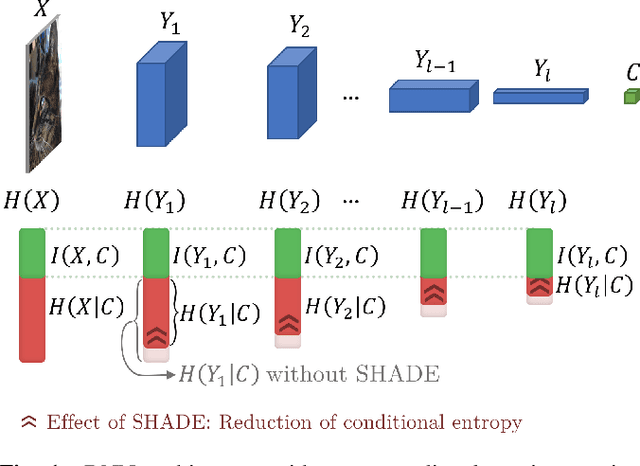
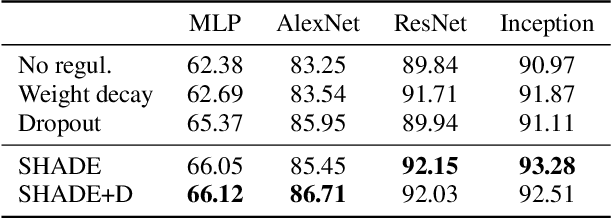
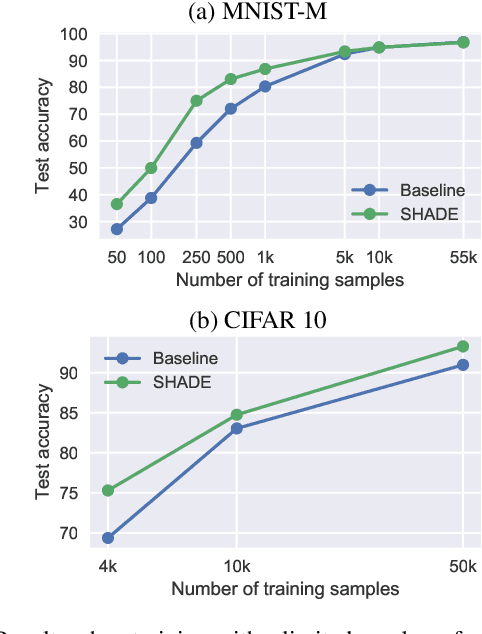

Regularization is a big issue for training deep neural networks. In this paper, we propose a new information-theory-based regularization scheme named SHADE for SHAnnon DEcay. The originality of the approach is to define a prior based on conditional entropy, which explicitly decouples the learning of invariant representations in the regularizer and the learning of correlations between inputs and labels in the data fitting term. Our second contribution is to derive a stochastic version of the regularizer compatible with deep learning, resulting in a tractable training scheme. We empirically validate the efficiency of our approach to improve classification performances compared to common regularization schemes on several standard architectures.