 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Prompts Override Vision: Prompt-Induced Hallucinations in LVLMs
Apr 23, 2026Despite impressive progress in capabilities of large vision-language models (LVLMs), these systems remain vulnerable to hallucinations, i.e., outputs that are not grounded in the visual input. Prior work has attributed hallucinations in LVLMs to factors such as limitations of the vision backbone or the dominance of the language component, yet the relative importance of these factors remains unclear. To resolve this ambiguity, We propose HalluScope, a benchmark to better understand the extent to which different factors induce hallucinations. Our analysis indicates that hallucinations largely stem from excessive reliance on textual priors and background knowledge, especially information introduced through textual instructions. To mitigate hallucinations induced by textual instruction priors, we propose HalluVL-DPO, a framework for fine-tuning off-the-shelf LVLMs towards more visually grounded responses. HalluVL-DPO leverages preference optimization using a curated training dataset that we construct, guiding the model to prefer grounded responses over hallucinated ones. We demonstrate that our optimized model effectively mitigates the targeted hallucination failure mode, while preserving or improving performance on other hallucination benchmarks and visual capability evaluations. To support reproducibility and further research, we will publicly release our evaluation benchmark, preference training dataset, and code at https://pegah-kh.github.io/projects/prompts-override-vision/ .
FrescoDiffusion: 4K Image-to-Video with Prior-Regularized Tiled Diffusion
Mar 18, 2026Diffusion-based image-to-video (I2V) models are increasingly effective, yet they struggle to scale to ultra-high-resolution inputs (e.g., 4K). Generating videos at the model's native resolution often loses fine-grained structure, whereas high-resolution tiled denoising preserves local detail but breaks global layout consistency. This failure mode is particularly severe in the fresco animation setting: monumental artworks containing many distinct characters, objects, and semantically different sub-scenes that must remain spatially coherent over time. We introduce FrescoDiffusion, a training-free method for coherent large-format I2V generation from a single complex image. The key idea is to augment tiled denoising with a precomputed latent prior: we first generate a low-resolution video at the underlying model resolution and upsample its latent trajectory to obtain a global reference that captures long-range temporal and spatial structure. For 4K generation, we compute per-tile noise predictions and fuse them with this reference at every diffusion timestep by minimizing a single weighted least-squares objective in model-output space. The objective combines a standard tile-merging criterion with our regularization term, yielding a closed-form fusion update that strengthens global coherence while retaining fine detail. We additionally provide a spatial regularization variable that enables region-level control over where motion is allowed. Experiments on the VBench-I2V dataset and our proposed fresco I2V dataset show improved global consistency and fidelity over tiled baselines, while being computationally efficient. Our regularization enables explicit controllability of the trade-off between creativity and consistency.
MAD: Motion Appearance Decoupling for efficient Driving World Models
Jan 14, 2026Recent video diffusion models generate photorealistic, temporally coherent videos, yet they fall short as reliable world models for autonomous driving, where structured motion and physically consistent interactions are essential. Adapting these generalist video models to driving domains has shown promise but typically requires massive domain-specific data and costly fine-tuning. We propose an efficient adaptation framework that converts generalist video diffusion models into controllable driving world models with minimal supervision. The key idea is to decouple motion learning from appearance synthesis. First, the model is adapted to predict structured motion in a simplified form: videos of skeletonized agents and scene elements, focusing learning on physical and social plausibility. Then, the same backbone is reused to synthesize realistic RGB videos conditioned on these motion sequences, effectively "dressing" the motion with texture and lighting. This two-stage process mirrors a reasoning-rendering paradigm: first infer dynamics, then render appearance. Our experiments show this decoupled approach is exceptionally efficient: adapting SVD, we match prior SOTA models with less than 6% of their compute. Scaling to LTX, our MAD-LTX model outperforms all open-source competitors, and supports a comprehensive suite of text, ego, and object controls. Project page: https://vita-epfl.github.io/MAD-World-Model/
Driving on Registers
Jan 08, 2026We present DrivoR, a simple and efficient transformer-based architecture for end-to-end autonomous driving. Our approach builds on pretrained Vision Transformers (ViTs) and introduces camera-aware register tokens that compress multi-camera features into a compact scene representation, significantly reducing downstream computation without sacrificing accuracy. These tokens drive two lightweight transformer decoders that generate and then score candidate trajectories. The scoring decoder learns to mimic an oracle and predicts interpretable sub-scores representing aspects such as safety, comfort, and efficiency, enabling behavior-conditioned driving at inference. Despite its minimal design, DrivoR outperforms or matches strong contemporary baselines across NAVSIM-v1, NAVSIM-v2, and the photorealistic closed-loop HUGSIM benchmark. Our results show that a pure-transformer architecture, combined with targeted token compression, is sufficient for accurate, efficient, and adaptive end-to-end driving. Code and checkpoints will be made available via the project page.
SSDD: Single-Step Diffusion Decoder for Efficient Image Tokenization
Oct 06, 2025Tokenizers are a key component of state-of-the-art generative image models, extracting the most important features from the signal while reducing data dimension and redundancy. Most current tokenizers are based on KL-regularized variational autoencoders (KL-VAE), trained with reconstruction, perceptual and adversarial losses. Diffusion decoders have been proposed as a more principled alternative to model the distribution over images conditioned on the latent. However, matching the performance of KL-VAE still requires adversarial losses, as well as a higher decoding time due to iterative sampling. To address these limitations, we introduce a new pixel diffusion decoder architecture for improved scaling and training stability, benefiting from transformer components and GAN-free training. We use distillation to replicate the performance of the diffusion decoder in an efficient single-step decoder. This makes SSDD the first diffusion decoder optimized for single-step reconstruction trained without adversarial losses, reaching higher reconstruction quality and faster sampling than KL-VAE. In particular, SSDD improves reconstruction FID from $0.87$ to $0.50$ with $1.4\times$ higher throughput and preserve generation quality of DiTs with $3.8\times$ faster sampling. As such, SSDD can be used as a drop-in replacement for KL-VAE, and for building higher-quality and faster generative models.
RAP: 3D Rasterization Augmented End-to-End Planning
Oct 05, 2025Imitation learning for end-to-end driving trains policies only on expert demonstrations. Once deployed in a closed loop, such policies lack recovery data: small mistakes cannot be corrected and quickly compound into failures. A promising direction is to generate alternative viewpoints and trajectories beyond the logged path. Prior work explores photorealistic digital twins via neural rendering or game engines, but these methods are prohibitively slow and costly, and thus mainly used for evaluation. In this work, we argue that photorealism is unnecessary for training end-to-end planners. What matters is semantic fidelity and scalability: driving depends on geometry and dynamics, not textures or lighting. Motivated by this, we propose 3D Rasterization, which replaces costly rendering with lightweight rasterization of annotated primitives, enabling augmentations such as counterfactual recovery maneuvers and cross-agent view synthesis. To transfer these synthetic views effectively to real-world deployment, we introduce a Raster-to-Real feature-space alignment that bridges the sim-to-real gap. Together, these components form Rasterization Augmented Planning (RAP), a scalable data augmentation pipeline for planning. RAP achieves state-of-the-art closed-loop robustness and long-tail generalization, ranking first on four major benchmarks: NAVSIM v1/v2, Waymo Open Dataset Vision-based E2E Driving, and Bench2Drive. Our results show that lightweight rasterization with feature alignment suffices to scale E2E training, offering a practical alternative to photorealistic rendering. Project page: https://alan-lanfeng.github.io/RAP/.
IPA: An Information-Preserving Input Projection Framework for Efficient Foundation Model Adaptation
Sep 04, 2025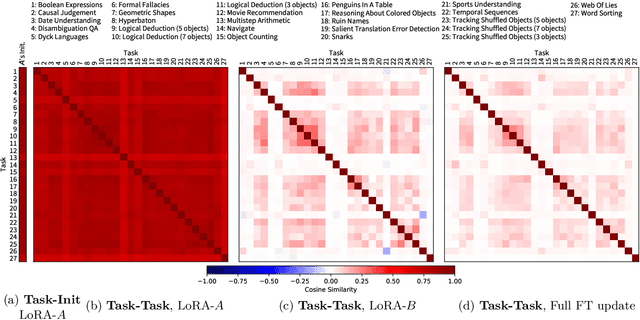
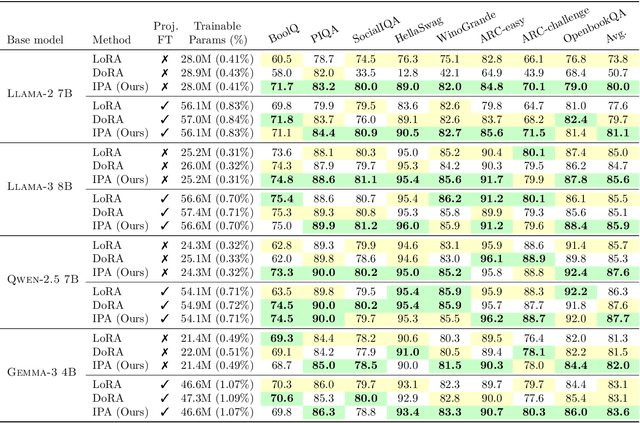
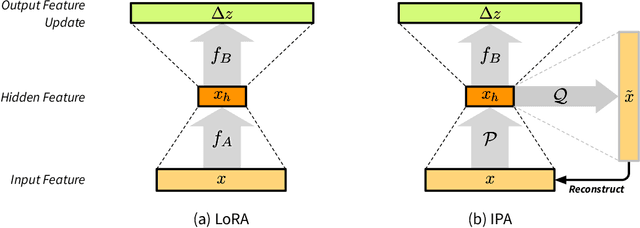
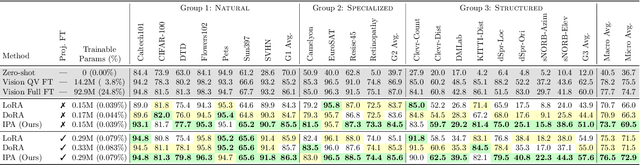
Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, reduce adaptation cost by injecting low-rank updates into pretrained weights. However, LoRA's down-projection is randomly initialized and data-agnostic, discarding potentially useful information. Prior analyses show that this projection changes little during training, while the up-projection carries most of the adaptation, making the random input compression a performance bottleneck. We propose IPA, a feature-aware projection framework that explicitly preserves information in the reduced hidden space. In the linear case, we instantiate IPA with algorithms approximating top principal components, enabling efficient projector pretraining with negligible inference overhead. Across language and vision benchmarks, IPA consistently improves over LoRA and DoRA, achieving on average 1.5 points higher accuracy on commonsense reasoning and 2.3 points on VTAB-1k, while matching full LoRA performance with roughly half the trainable parameters when the projection is frozen.
Scaling Laws for Native Multimodal Models Scaling Laws for Native Multimodal Models
Apr 10, 2025



Building general-purpose models that can effectively perceive the world through multimodal signals has been a long-standing goal. Current approaches involve integrating separately pre-trained components, such as connecting vision encoders to LLMs and continuing multimodal training. While such approaches exhibit remarkable sample efficiency, it remains an open question whether such late-fusion architectures are inherently superior. In this work, we revisit the architectural design of native multimodal models (NMMs)--those trained from the ground up on all modalities--and conduct an extensive scaling laws study, spanning 457 trained models with different architectures and training mixtures. Our investigation reveals no inherent advantage to late-fusion architectures over early-fusion ones, which do not rely on image encoders. On the contrary, early-fusion exhibits stronger performance at lower parameter counts, is more efficient to train, and is easier to deploy. Motivated by the strong performance of the early-fusion architectures, we show that incorporating Mixture of Experts (MoEs) allows for models that learn modality-specific weights, significantly enhancing performance.
VaViM and VaVAM: Autonomous Driving through Video Generative Modeling
Feb 21, 2025We explore the potential of large-scale generative video models for autonomous driving, introducing an open-source auto-regressive video model (VaViM) and its companion video-action model (VaVAM) to investigate how video pre-training transfers to real-world driving. VaViM is a simple auto-regressive video model that predicts frames using spatio-temporal token sequences. We show that it captures the semantics and dynamics of driving scenes. VaVAM, the video-action model, leverages the learned representations of VaViM to generate driving trajectories through imitation learning. Together, the models form a complete perception-to-action pipeline. We evaluate our models in open- and closed-loop driving scenarios, revealing that video-based pre-training holds promise for autonomous driving. Key insights include the semantic richness of the learned representations, the benefits of scaling for video synthesis, and the complex relationship between model size, data, and safety metrics in closed-loop evaluations. We release code and model weights at https://github.com/valeoai/VideoActionModel
GaussRender: Learning 3D Occupancy with Gaussian Rendering
Feb 07, 2025



Understanding the 3D geometry and semantics of driving scenes is critical for developing of safe autonomous vehicles. While 3D occupancy models are typically trained using voxel-based supervision with standard losses (e.g., cross-entropy, Lovasz, dice), these approaches treat voxel predictions independently, neglecting their spatial relationships. In this paper, we propose GaussRender, a plug-and-play 3D-to-2D reprojection loss that enhances voxel-based supervision. Our method projects 3D voxel representations into arbitrary 2D perspectives and leverages Gaussian splatting as an efficient, differentiable rendering proxy of voxels, introducing spatial dependencies across projected elements. This approach improves semantic and geometric consistency, handles occlusions more efficiently, and requires no architectural modifications. Extensive experiments on multiple benchmarks (SurroundOcc-nuScenes, Occ3D-nuScenes, SSCBench-KITTI360) demonstrate consistent performance gains across various 3D occupancy models (TPVFormer, SurroundOcc, Symphonies), highlighting the robustness and versatility of our framework. The code is available at https://github.com/valeoai/GaussRender.