 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Laws for Native Multimodal Models Scaling Laws for Native Multimodal Models
Apr 10, 2025



Building general-purpose models that can effectively perceive the world through multimodal signals has been a long-standing goal. Current approaches involve integrating separately pre-trained components, such as connecting vision encoders to LLMs and continuing multimodal training. While such approaches exhibit remarkable sample efficiency, it remains an open question whether such late-fusion architectures are inherently superior. In this work, we revisit the architectural design of native multimodal models (NMMs)--those trained from the ground up on all modalities--and conduct an extensive scaling laws study, spanning 457 trained models with different architectures and training mixtures. Our investigation reveals no inherent advantage to late-fusion architectures over early-fusion ones, which do not rely on image encoders. On the contrary, early-fusion exhibits stronger performance at lower parameter counts, is more efficient to train, and is easier to deploy. Motivated by the strong performance of the early-fusion architectures, we show that incorporating Mixture of Experts (MoEs) allows for models that learn modality-specific weights, significantly enhancing performance.
Multimodal Autoregressive Pre-training of Large Vision Encoders
Nov 21, 2024



We introduce a novel method for pre-training of large-scale vision encoders. Building on recent advancements in autoregressive pre-training of vision models, we extend this framework to a multimodal setting, i.e., images and text. In this paper, we present AIMV2, a family of generalist vision encoders characterized by a straightforward pre-training process, scalability, and remarkable performance across a range of downstream tasks. This is achieved by pairing the vision encoder with a multimodal decoder that autoregressively generates raw image patches and text tokens. Our encoders excel not only in multimodal evaluations but also in vision benchmarks such as localization, grounding, and classification. Notably, our AIMV2-3B encoder achieves 89.5% accuracy on ImageNet-1k with a frozen trunk. Furthermore, AIMV2 consistently outperforms state-of-the-art contrastive models (e.g., CLIP, SigLIP) in multimodal image understanding across diverse settings.
Simplifying Open-Set Video Domain Adaptation with Contrastive Learning
Jan 09, 2023



In an effort to reduce annotation costs in action recognition, unsupervised video domain adaptation methods have been proposed that aim to adapt a predictive model from a labelled dataset (i.e., source domain) to an unlabelled dataset (i.e., target domain). In this work we address a more realistic scenario, called open-set video domain adaptation (OUVDA), where the target dataset contains "unknown" semantic categories that are not shared with the source. The challenge lies in aligning the shared classes of the two domains while separating the shared classes from the unknown ones. In this work we propose to address OUVDA with an unified contrastive learning framework that learns discriminative and well-clustered features. We also propose a video-oriented temporal contrastive loss that enables our method to better cluster the feature space by exploiting the freely available temporal information in video data. We show that discriminative feature space facilitates better separation of the unknown classes, and thereby allows us to use a simple similarity based score to identify them. We conduct thorough experimental evaluation on multiple OUVDA benchmarks and show the effectiveness of our proposed method against the prior art.
Variational prompt tuning improves generalization of vision-language models
Oct 05, 2022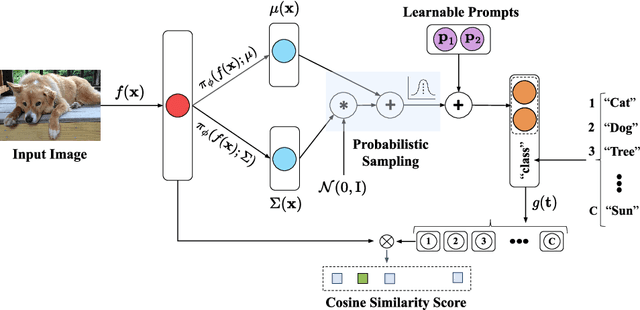
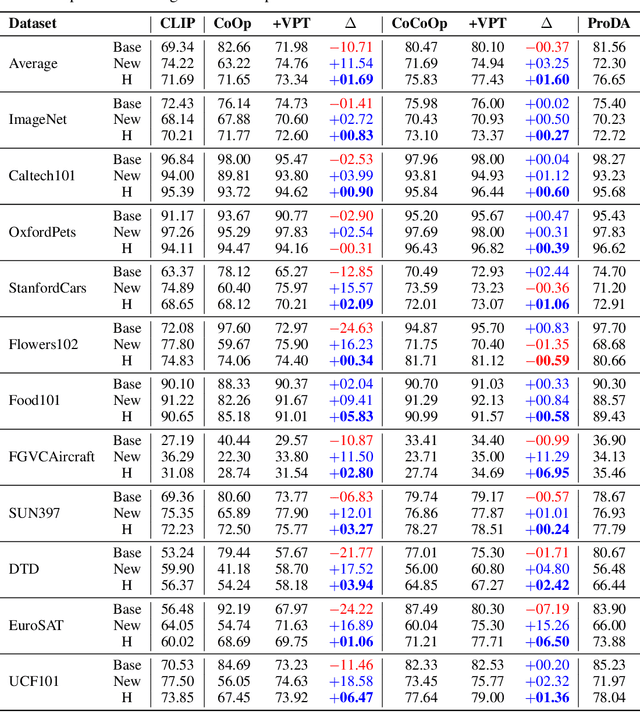
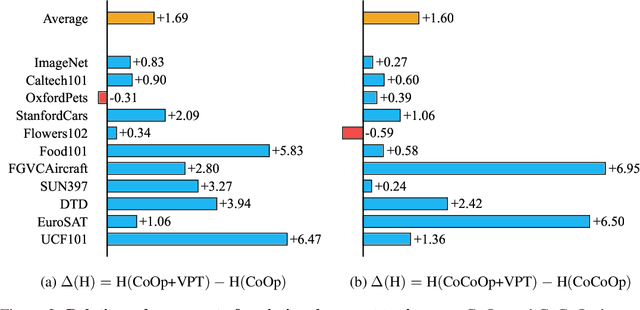
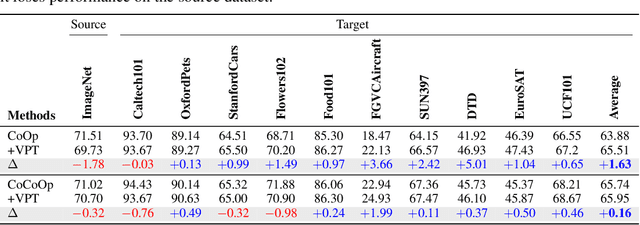
Prompt tuning provides an efficient mechanism to adapt large vision-language models to downstream tasks by treating part of the input language prompts as learnable parameters while freezing the rest of the model. Existing works for prompt tuning are however prone to damaging the generalization capabilities of the foundation models, because the learned prompts lack the capacity of covering certain concepts within the language model. To avoid such limitation, we propose a probabilistic modeling of the underlying distribution of prompts, allowing prompts within the support of an associated concept to be derived through stochastic sampling. This results in a more complete and richer transfer of the information captured by the language model, providing better generalization capabilities for downstream tasks. The resulting algorithm relies on a simple yet powerful variational framework that can be directly integrated with other developments. We show our approach is seamlessly integrated into both standard and conditional prompt learning frameworks, improving the performance on both cases considerably, especially with regards to preserving the generalization capability of the original model. Our method provides the current state-of-the-art for prompt learning, surpassing CoCoOp by 1.6% average Top-1 accuracy on the standard benchmark. Remarkably, it even surpasses the original CLIP model in terms of generalization to new classes. Implementation code will be released.
Strict Very Fast Decision Tree: a memory conservative algorithm for data stream mining
May 17, 2018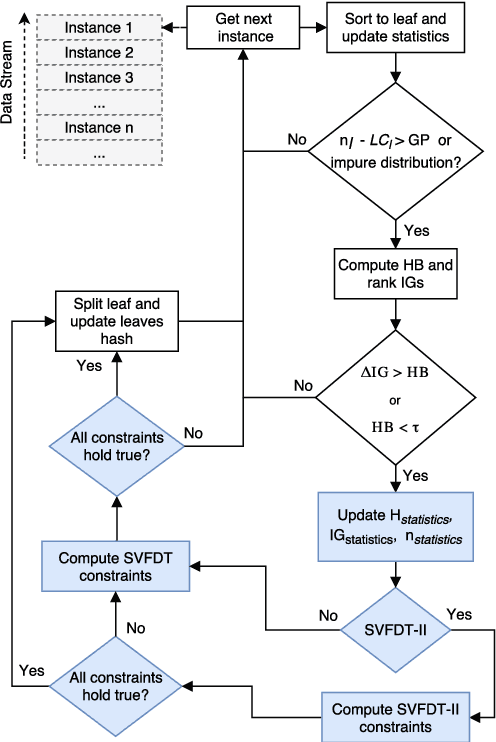
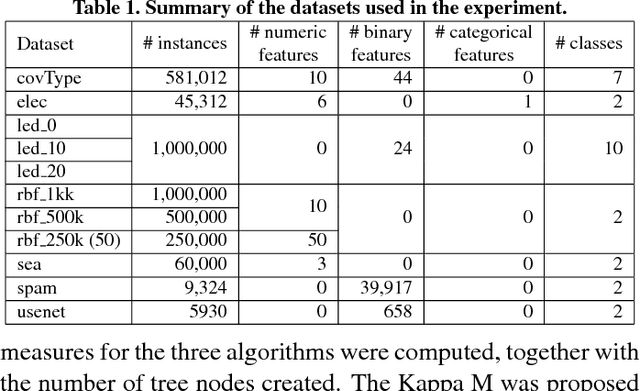

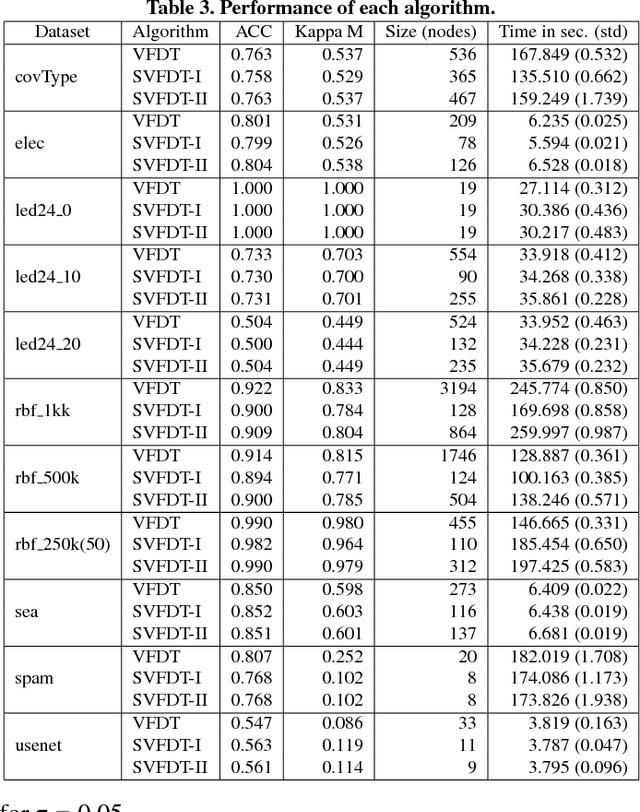
Dealing with memory and time constraints are current challenges when learning from data streams with a massive amount of data. Many algorithms have been proposed to handle these difficulties, among them, the Very Fast Decision Tree (VFDT) algorithm. Although the VFDT has been widely used in data stream mining, in the last years, several authors have suggested modifications to increase its performance, putting aside memory concerns by proposing memory-costly solutions. Besides, most data stream mining solutions have been centred around ensembles, which combine the memory costs of their weak learners, usually VFDTs. To reduce the memory cost, keeping the predictive performance, this study proposes the Strict VFDT (SVFDT), a novel algorithm based on the VFDT. The SVFDT algorithm minimises unnecessary tree growth, substantially reducing memory usage and keeping competitive predictive performance. Moreover, since it creates much more shallow trees than VFDT, SVFDT can achieve a shorter processing time. Experiments were carried out comparing the SVFDT with the VFDT in 11 benchmark data stream datasets. This comparison assessed the trade-off between accuracy, memory, and processing time. Statistical analysis showed that the proposed algorithm obtained similar predictive performance and significantly reduced processing time and memory use. Thus, SVFDT is a suitable option for data stream mining with memory and time limitations, recommended as a weak learner in ensemble-based solutions.