 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Decision Predicate Graphs for Comprehensive Explanation of Isolation Forest
May 06, 2025The need to explain predictive models is well-established in modern machine learning. However, beyond model interpretability, understanding pre-processing methods is equally essential. Understanding how data modifications impact model performance improvements and potential biases and promoting a reliable pipeline is mandatory for developing robust machine learning solutions. Isolation Forest (iForest) is a widely used technique for outlier detection that performs well. Its effectiveness increases with the number of tree-based learners. However, this also complicates the explanation of outlier selection and the decision boundaries for inliers. This research introduces a novel Explainable AI (XAI) method, tackling the problem of global explainability. In detail, it aims to offer a global explanation for outlier detection to address its opaque nature. Our approach is based on the Decision Predicate Graph (DPG), which clarifies the logic of ensemble methods and provides both insights and a graph-based metric to explain how samples are identified as outliers using the proposed Inlier-Outlier Propagation Score (IOP-Score). Our proposal enhances iForest's explainability and provides a comprehensive view of the decision-making process, detailing which features contribute to outlier identification and how the model utilizes them. This method advances the state-of-the-art by providing insights into decision boundaries and a comprehensive view of holistic feature usage in outlier identification. -- thus promoting a fully explainable machine learning pipeline.
Problem-oriented AutoML in Clustering
Sep 24, 2024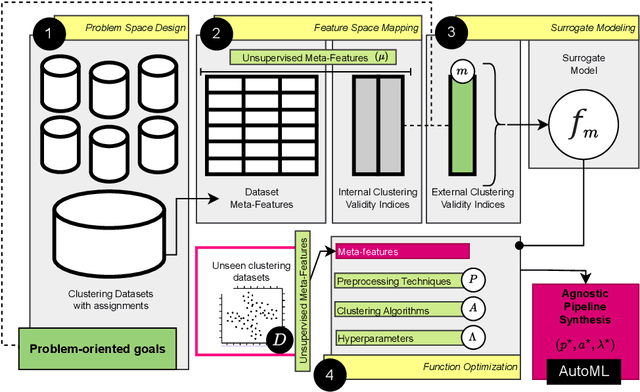

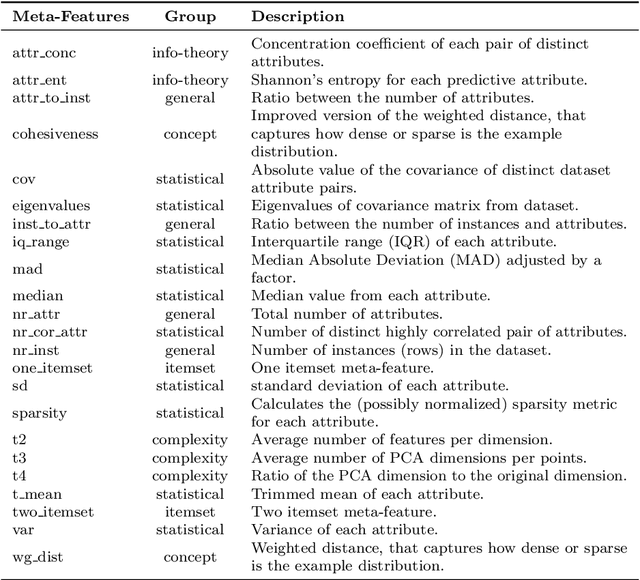
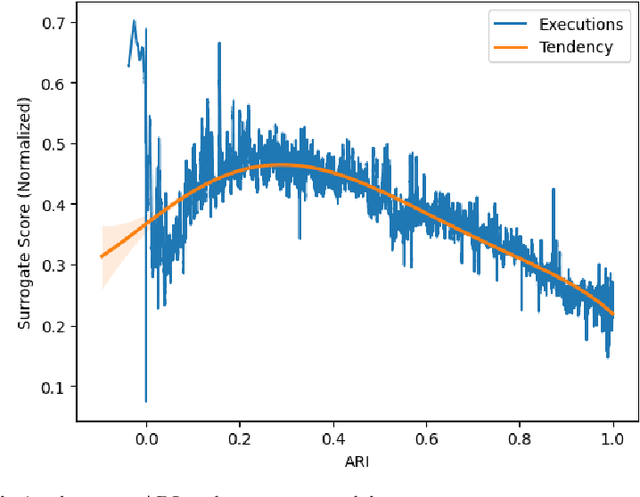
The Problem-oriented AutoML in Clustering (PoAC) framework introduces a novel, flexible approach to automating clustering tasks by addressing the shortcomings of traditional AutoML solutions. Conventional methods often rely on predefined internal Clustering Validity Indexes (CVIs) and static meta-features, limiting their adaptability and effectiveness across diverse clustering tasks. In contrast, PoAC establishes a dynamic connection between the clustering problem, CVIs, and meta-features, allowing users to customize these components based on the specific context and goals of their task. At its core, PoAC employs a surrogate model trained on a large meta-knowledge base of previous clustering datasets and solutions, enabling it to infer the quality of new clustering pipelines and synthesize optimal solutions for unseen datasets. Unlike many AutoML frameworks that are constrained by fixed evaluation metrics and algorithm sets, PoAC is algorithm-agnostic, adapting seamlessly to different clustering problems without requiring additional data or retraining. Experimental results demonstrate that PoAC not only outperforms state-of-the-art frameworks on a variety of datasets but also excels in specific tasks such as data visualization, and highlight its ability to dynamically adjust pipeline configurations based on dataset complexity.
Are Large Language Models the New Interface for Data Pipelines?
Jun 06, 2024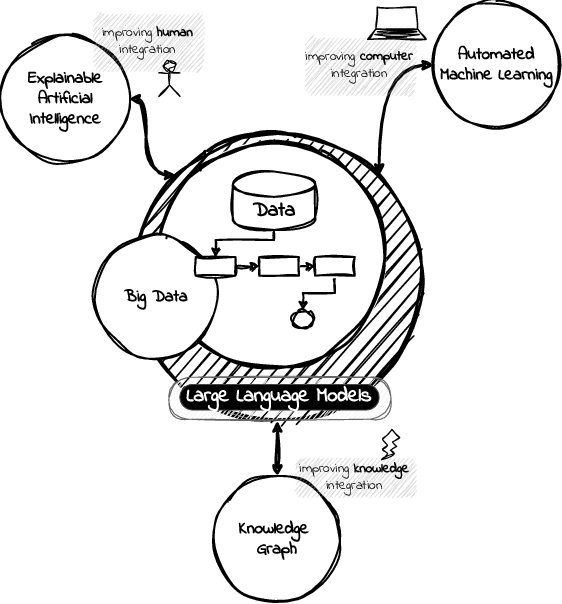
A Language Model is a term that encompasses various types of models designed to understand and generate human communication. Large Language Models (LLMs) have gained significant attention due to their ability to process text with human-like fluency and coherence, making them valuable for a wide range of data-related tasks fashioned as pipelines. The capabilities of LLMs in natural language understanding and generation, combined with their scalability, versatility, and state-of-the-art performance, enable innovative applications across various AI-related fields, including eXplainable Artificial Intelligence (XAI), Automated Machine Learning (AutoML), and Knowledge Graphs (KG). Furthermore, we believe these models can extract valuable insights and make data-driven decisions at scale, a practice commonly referred to as Big Data Analytics (BDA). In this position paper, we provide some discussions in the direction of unlocking synergies among these technologies, which can lead to more powerful and intelligent AI solutions, driving improvements in data pipelines across a wide range of applications and domains integrating humans, computers, and knowledge.
Decision Predicate Graphs: Enhancing Interpretability in Tree Ensembles
Apr 03, 2024Understanding the decisions of tree-based ensembles and their relationships is pivotal for machine learning model interpretation. Recent attempts to mitigate the human-in-the-loop interpretation challenge have explored the extraction of the decision structure underlying the model taking advantage of graph simplification and path emphasis. However, while these efforts enhance the visualisation experience, they may either result in a visually complex representation or compromise the interpretability of the original ensemble model. In addressing this challenge, especially in complex scenarios, we introduce the Decision Predicate Graph (DPG) as a model-agnostic tool to provide a global interpretation of the model. DPG is a graph structure that captures the tree-based ensemble model and learned dataset details, preserving the relations among features, logical decisions, and predictions towards emphasising insightful points. Leveraging well-known graph theory concepts, such as the notions of centrality and community, DPG offers additional quantitative insights into the model, complementing visualisation techniques, expanding the problem space descriptions, and offering diverse possibilities for extensions. Empirical experiments demonstrate the potential of DPG in addressing traditional benchmarks and complex classification scenarios.
Tailoring Machine Learning for Process Mining
Jun 17, 2023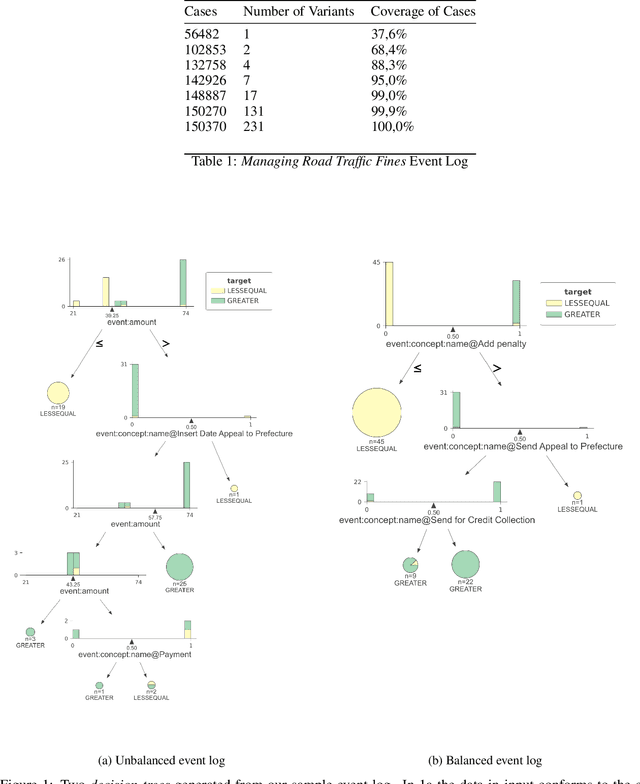
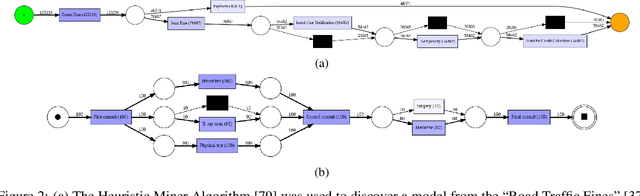
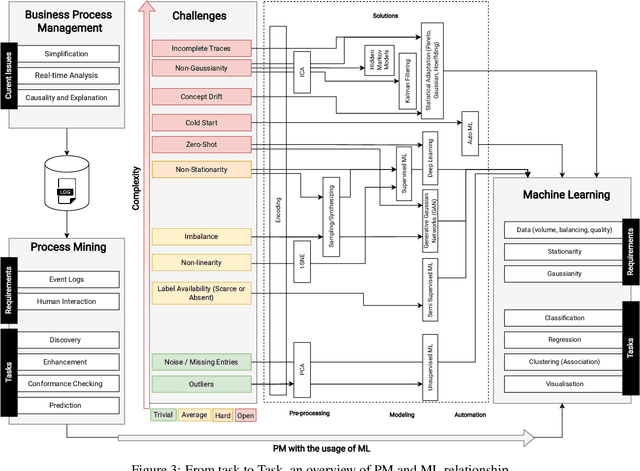
Machine learning models are routinely integrated into process mining pipelines to carry out tasks like data transformation, noise reduction, anomaly detection, classification, and prediction. Often, the design of such models is based on some ad-hoc assumptions about the corresponding data distributions, which are not necessarily in accordance with the non-parametric distributions typically observed with process data. Moreover, the learning procedure they follow ignores the constraints concurrency imposes to process data. Data encoding is a key element to smooth the mismatch between these assumptions but its potential is poorly exploited. In this paper, we argue that a deeper insight into the issues raised by training machine learning models with process data is crucial to ground a sound integration of process mining and machine learning. Our analysis of such issues is aimed at laying the foundation for a methodology aimed at correctly aligning machine learning with process mining requirements and stimulating the research to elaborate in this direction.
Rethinking Default Values: a Low Cost and Efficient Strategy to Define Hyperparameters
Aug 19, 2020
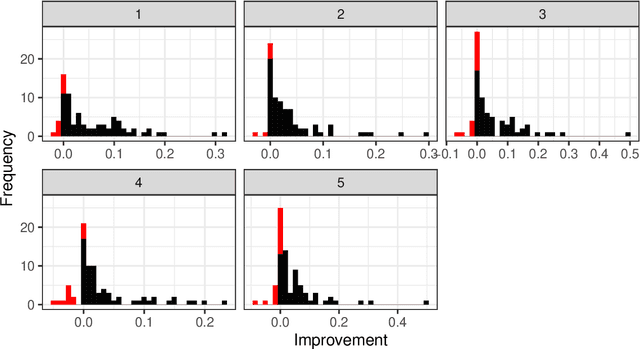
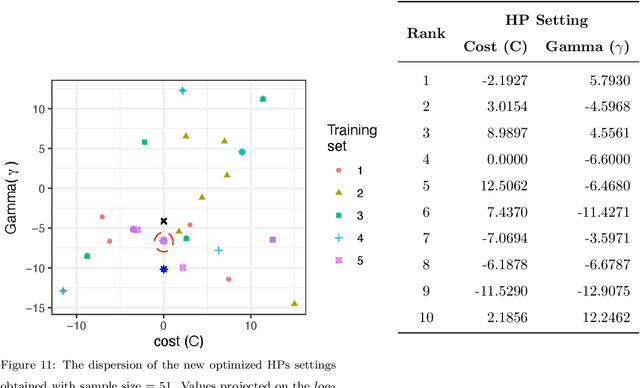
Machine Learning (ML) algorithms have been successfully employed by a vast range of practitioners with different backgrounds. One of the reasons for ML popularity is the capability to consistently delivers accurate results, which can be further boosted by adjusting hyperparameters (HP). However, part of practitioners has limited knowledge about the algorithms and does not take advantage of suitable HP settings. In general, HP values are defined by trial and error, tuning, or by using default values. Trial and error is very subjective, time costly and dependent on the user experience. Tuning techniques search for HP values able to maximize the predictive performance of induced models for a given dataset, but with the drawback of a high computational cost and target specificity. To avoid tuning costs, practitioners use default values suggested by the algorithm developer or by tools implementing the algorithm. Although default values usually result in models with acceptable predictive performance, different implementations of the same algorithm can suggest distinct default values. To maintain a balance between tuning and using default values, we propose a strategy to generate new optimized default values. Our approach is grounded on a small set of optimized values able to obtain predictive performance values better than default settings provided by popular tools. The HP candidates are estimated through a pool of promising values tuned from a small and informative set of datasets. After performing a large experiment and a careful analysis of the results, we concluded that our approach delivers better default values. Besides, it leads to competitive solutions when compared with the use of tuned values, being easier to use and having a lower cost.Based on our results, we also extracted simple rules to guide practitioners in deciding whether using our new methodology or a tuning approach.
An empirical study on hyperparameter tuning of decision trees
Dec 05, 2018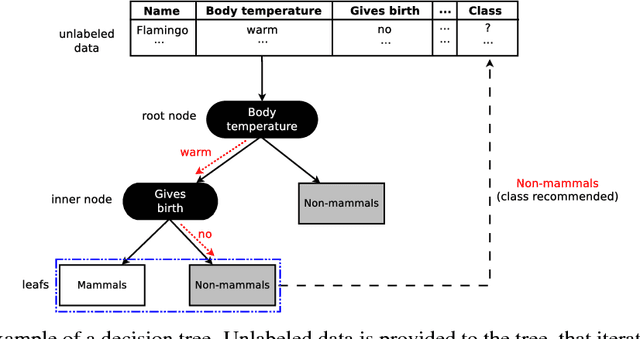
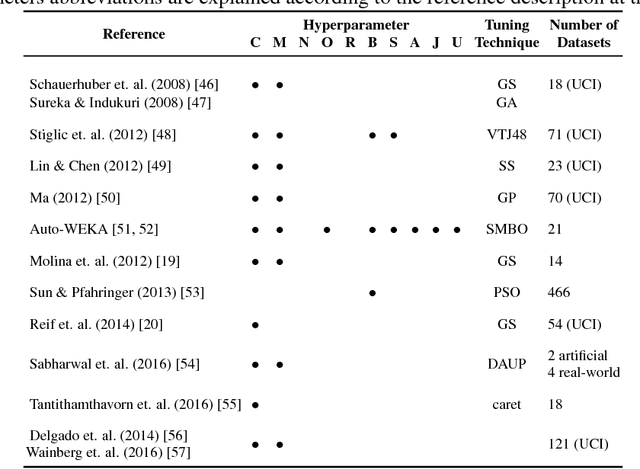
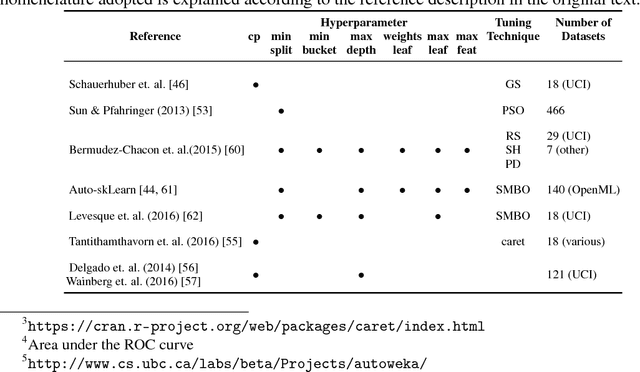
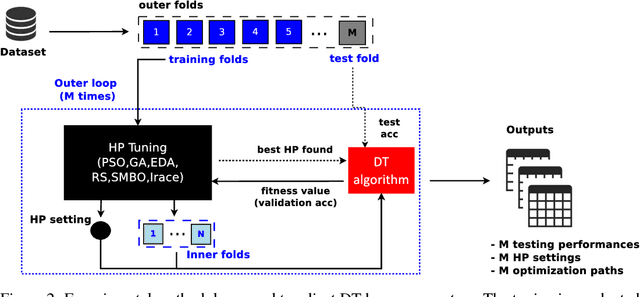
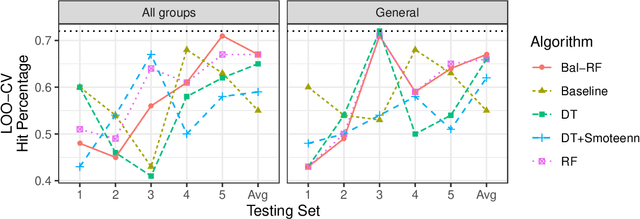
Machine learning algorithms often contain many hyperparameters whose values affect the predictive performance of the induced models in intricate ways. Due to the high number of possibilities for these hyperparameter configurations, and their complex interactions, it is common to use optimization techniques to find settings that lead to high predictive accuracy. However, we lack insight into how to efficiently explore this vast space of configurations: which are the best optimization techniques, how should we use them, and how significant is their effect on predictive or runtime performance? This paper provides a comprehensive approach for investigating the effects of hyperparameter tuning on three Decision Tree induction algorithms, CART, C4.5 and CTree. These algorithms were selected because they are based on similar principles, have presented a high predictive performance in several previous works and induce interpretable classification models. Additionally, they contain many interacting hyperparameters to be adjusted. Experiments were carried out with different tuning strategies to induce models and evaluate the relevance of hyperparameters using 94 classification datasets from OpenML. Experimental results indicate that hyperparameter tuning provides statistically significant improvements for C4.5 and CTree in only one-third of the datasets, and in most of the datasets for CART. Different tree algorithms may present different tuning scenarios, but in general, the tuning techniques required relatively few iterations to find accurate solutions. Furthermore, the best technique for all the algorithms was the Irace. Finally, we find that tuning a specific small subset of hyperparameters contributes most of the achievable optimal predictive performance.
Strict Very Fast Decision Tree: a memory conservative algorithm for data stream mining
May 17, 2018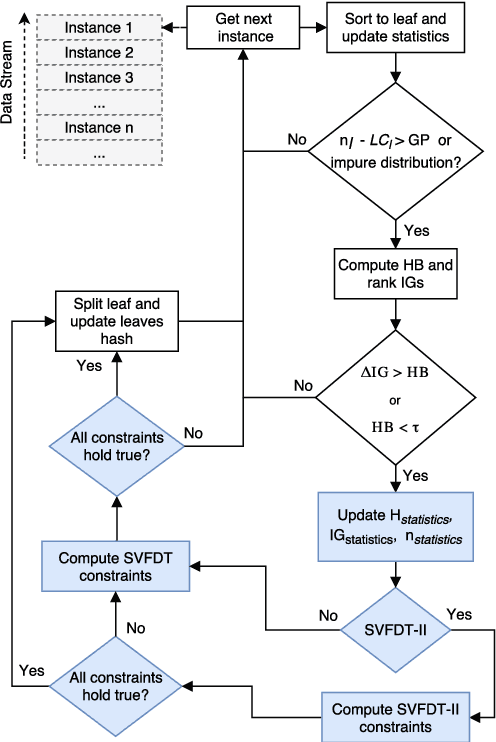
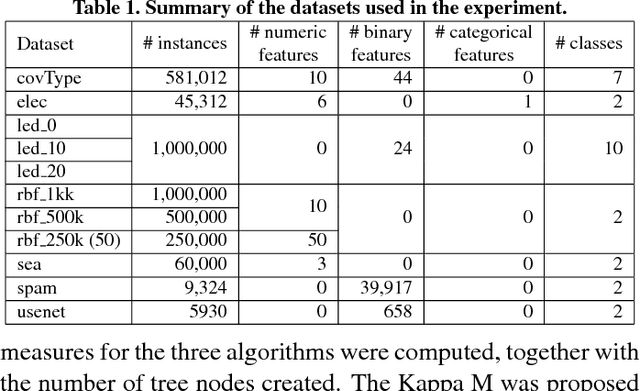

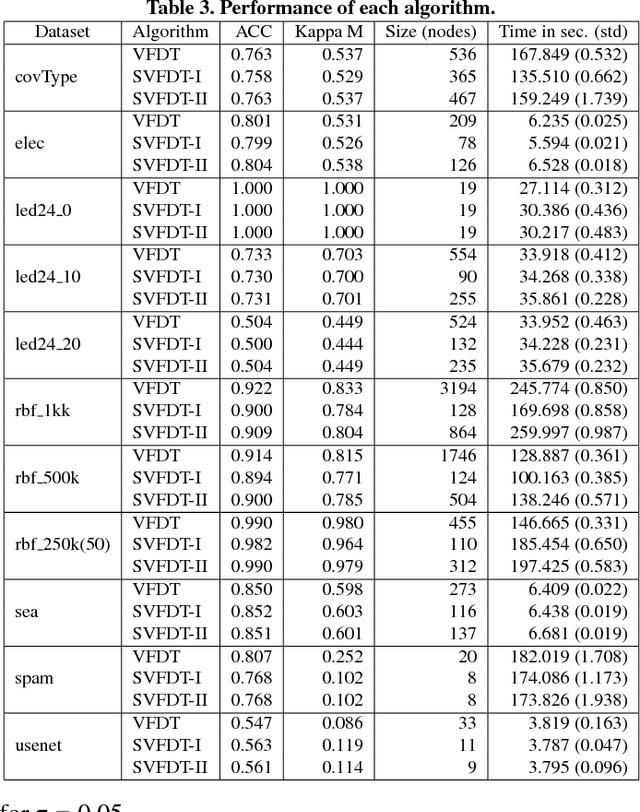
Dealing with memory and time constraints are current challenges when learning from data streams with a massive amount of data. Many algorithms have been proposed to handle these difficulties, among them, the Very Fast Decision Tree (VFDT) algorithm. Although the VFDT has been widely used in data stream mining, in the last years, several authors have suggested modifications to increase its performance, putting aside memory concerns by proposing memory-costly solutions. Besides, most data stream mining solutions have been centred around ensembles, which combine the memory costs of their weak learners, usually VFDTs. To reduce the memory cost, keeping the predictive performance, this study proposes the Strict VFDT (SVFDT), a novel algorithm based on the VFDT. The SVFDT algorithm minimises unnecessary tree growth, substantially reducing memory usage and keeping competitive predictive performance. Moreover, since it creates much more shallow trees than VFDT, SVFDT can achieve a shorter processing time. Experiments were carried out comparing the SVFDT with the VFDT in 11 benchmark data stream datasets. This comparison assessed the trade-off between accuracy, memory, and processing time. Statistical analysis showed that the proposed algorithm obtained similar predictive performance and significantly reduced processing time and memory use. Thus, SVFDT is a suitable option for data stream mining with memory and time limitations, recommended as a weak learner in ensemble-based solutions.