 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending Decision Predicate Graphs for Comprehensive Explanation of Isolation Forest
May 06, 2025The need to explain predictive models is well-established in modern machine learning. However, beyond model interpretability, understanding pre-processing methods is equally essential. Understanding how data modifications impact model performance improvements and potential biases and promoting a reliable pipeline is mandatory for developing robust machine learning solutions. Isolation Forest (iForest) is a widely used technique for outlier detection that performs well. Its effectiveness increases with the number of tree-based learners. However, this also complicates the explanation of outlier selection and the decision boundaries for inliers. This research introduces a novel Explainable AI (XAI) method, tackling the problem of global explainability. In detail, it aims to offer a global explanation for outlier detection to address its opaque nature. Our approach is based on the Decision Predicate Graph (DPG), which clarifies the logic of ensemble methods and provides both insights and a graph-based metric to explain how samples are identified as outliers using the proposed Inlier-Outlier Propagation Score (IOP-Score). Our proposal enhances iForest's explainability and provides a comprehensive view of the decision-making process, detailing which features contribute to outlier identification and how the model utilizes them. This method advances the state-of-the-art by providing insights into decision boundaries and a comprehensive view of holistic feature usage in outlier identification. -- thus promoting a fully explainable machine learning pipeline.
CORTEX: A Cost-Sensitive Rule and Tree Extraction Method
Feb 05, 2025



Tree-based and rule-based machine learning models play pivotal roles in explainable artificial intelligence (XAI) due to their unique ability to provide explanations in the form of tree or rule sets that are easily understandable and interpretable, making them essential for applications in which trust in model decisions is necessary. These transparent models are typically used in surrogate modeling, a post-hoc XAI approach for explaining the logic of black-box models, enabling users to comprehend and trust complex predictive systems while maintaining competitive performance. This study proposes the Cost-Sensitive Rule and Tree Extraction (CORTEX) method, a novel rule-based XAI algorithm grounded in the multi-class cost-sensitive decision tree (CSDT) method. The original version of the CSDT is extended to classification problems with more than two classes by inducing the concept of an n-dimensional class-dependent cost matrix. The performance of CORTEX as a rule-extractor XAI method is compared to other post-hoc tree and rule extraction methods across several datasets with different numbers of classes. Several quantitative evaluation metrics are employed to assess the explainability of generated rule sets. Our findings demonstrate that CORTEX is competitive with other tree-based methods and can be superior to other rule-based methods across different datasets. The extracted rule sets suggest the advantages of using the CORTEX method over other methods by producing smaller rule sets with shorter rules on average across datasets with a diverse number of classes. Overall, the results underscore the potential of CORTEX as a powerful XAI tool for scenarios that require the generation of clear, human-understandable rules while maintaining good predictive performance.
GPT Assisted Annotation of Rhetorical and Linguistic Features for Interpretable Propaganda Technique Detection in News Text
Jul 16, 2024
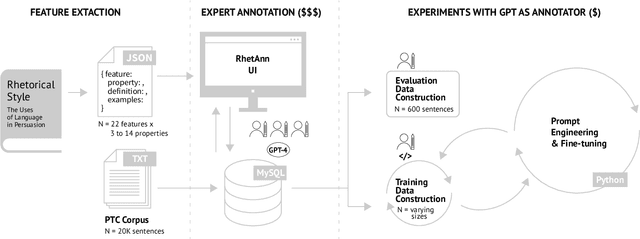


While the use of machine learning for the detection of propaganda techniques in text has garnered considerable attention, most approaches focus on "black-box" solutions with opaque inner workings. Interpretable approaches provide a solution, however, they depend on careful feature engineering and costly expert annotated data. Additionally, language features specific to propagandistic text are generally the focus of rhetoricians or linguists, and there is no data set labeled with such features suitable for machine learning. This study codifies 22 rhetorical and linguistic features identified in literature related to the language of persuasion for the purpose of annotating an existing data set labeled with propaganda techniques. To help human experts annotate natural language sentences with these features, RhetAnn, a web application, was specifically designed to minimize an otherwise considerable mental effort. Finally, a small set of annotated data was used to fine-tune GPT-3.5, a generative large language model (LLM), to annotate the remaining data while optimizing for financial cost and classification accuracy. This study demonstrates how combining a small number of human annotated examples with GPT can be an effective strategy for scaling the annotation process at a fraction of the cost of traditional annotation relying solely on human experts. The results are on par with the best performing model at the time of writing, namely GPT-4, at 10x less the cost. Our contribution is a set of features, their properties, definitions, and examples in a machine-readable format, along with the code for RhetAnn and the GPT prompts and fine-tuning procedures for advancing state-of-the-art interpretable propaganda technique detection.
CNN-based explanation ensembling for dataset, representation and explanations evaluation
Apr 16, 2024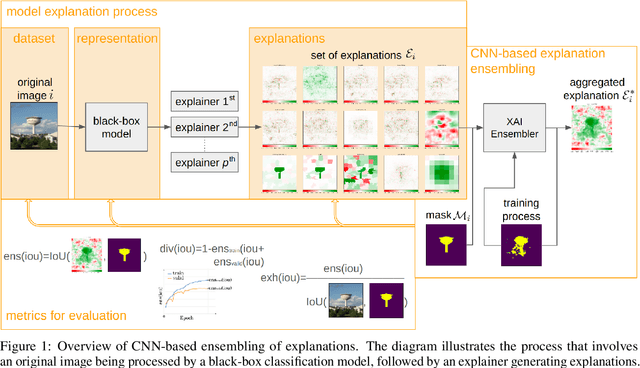
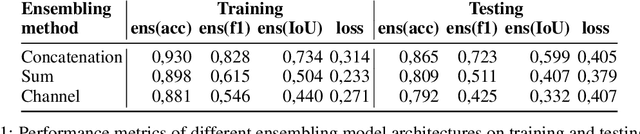


Explainable Artificial Intelligence has gained significant attention due to the widespread use of complex deep learning models in high-stake domains such as medicine, finance, and autonomous cars. However, different explanations often present different aspects of the model's behavior. In this research manuscript, we explore the potential of ensembling explanations generated by deep classification models using convolutional model. Through experimentation and analysis, we aim to investigate the implications of combining explanations to uncover a more coherent and reliable patterns of the model's behavior, leading to the possibility of evaluating the representation learned by the model. With our method, we can uncover problems of under-representation of images in a certain class. Moreover, we discuss other side benefits like features' reduction by replacing the original image with its explanations resulting in the removal of some sensitive information. Through the use of carefully selected evaluation metrics from the Quantus library, we demonstrated the method's superior performance in terms of Localisation and Faithfulness, compared to individual explanations.
Explainable Artificial Intelligence (XAI) 2.0: A Manifesto of Open Challenges and Interdisciplinary Research Directions
Oct 30, 2023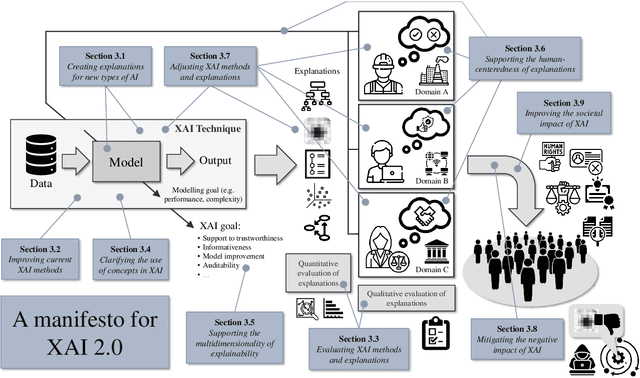
As systems based on opaque Artificial Intelligence (AI) continue to flourish in diverse real-world applications, understanding these black box models has become paramount. In response, Explainable AI (XAI) has emerged as a field of research with practical and ethical benefits across various domains. This paper not only highlights the advancements in XAI and its application in real-world scenarios but also addresses the ongoing challenges within XAI, emphasizing the need for broader perspectives and collaborative efforts. We bring together experts from diverse fields to identify open problems, striving to synchronize research agendas and accelerate XAI in practical applications. By fostering collaborative discussion and interdisciplinary cooperation, we aim to propel XAI forward, contributing to its continued success. Our goal is to put forward a comprehensive proposal for advancing XAI. To achieve this goal, we present a manifesto of 27 open problems categorized into nine categories. These challenges encapsulate the complexities and nuances of XAI and offer a road map for future research. For each problem, we provide promising research directions in the hope of harnessing the collective intelligence of interested stakeholders.
Interpretable Timbre Synthesis using Variational Autoencoders Regularized on Timbre Descriptors
Jul 18, 2023Controllable timbre synthesis has been a subject of research for several decades, and deep neural networks have been the most successful in this area. Deep generative models such as Variational Autoencoders (VAEs) have the ability to generate a high-level representation of audio while providing a structured latent space. Despite their advantages, the interpretability of these latent spaces in terms of human perception is often limited. To address this limitation and enhance the control over timbre generation, we propose a regularized VAE-based latent space that incorporates timbre descriptors. Moreover, we suggest a more concise representation of sound by utilizing its harmonic content, in order to minimize the dimensionality of the latent space.
A novel structured argumentation framework for improved explainability of classification tasks
Jun 27, 2023This paper presents a novel framework for structured argumentation, named extend argumentative decision graph ($xADG$). It is an extension of argumentative decision graphs built upon Dung's abstract argumentation graphs. The $xADG$ framework allows for arguments to use boolean logic operators and multiple premises (supports) within their internal structure, resulting in more concise argumentation graphs that may be easier for users to understand. The study presents a methodology for construction of $xADGs$ and evaluates their size and predictive capacity for classification tasks of varying magnitudes. Resulting $xADGs$ achieved strong (balanced) accuracy, which was accomplished through an input decision tree, while also reducing the average number of supports needed to reach a conclusion. The results further indicated that it is possible to construct plausibly understandable $xADGs$ that outperform other techniques for building $ADGs$ in terms of predictive capacity and overall size. In summary, the study suggests that $xADG$ represents a promising framework to developing more concise argumentative models that can be used for classification tasks and knowledge discovery, acquisition, and refinement.
An investigation of the reconstruction capacity of stacked convolutional autoencoders for log-mel-spectrograms
Jan 18, 2023



In audio processing applications, the generation of expressive sounds based on high-level representations demonstrates a high demand. These representations can be used to manipulate the timbre and influence the synthesis of creative instrumental notes. Modern algorithms, such as neural networks, have inspired the development of expressive synthesizers based on musical instrument timbre compression. Unsupervised deep learning methods can achieve audio compression by training the network to learn a mapping from waveforms or spectrograms to low-dimensional representations. This study investigates the use of stacked convolutional autoencoders for the compression of time-frequency audio representations for a variety of instruments for a single pitch. Further exploration of hyper-parameters and regularization techniques is demonstrated to enhance the performance of the initial design. In an unsupervised manner, the network is able to reconstruct a monophonic and harmonic sound based on latent representations. In addition, we introduce an evaluation metric to measure the similarity between the original and reconstructed samples. Evaluating a deep generative model for the synthesis of sound is a challenging task. Our approach is based on the accuracy of the generated frequencies as it presents a significant metric for the perception of harmonic sounds. This work is expected to accelerate future experiments on audio compression using neural autoencoders.
Modeling cognitive load as a self-supervised brain rate with electroencephalography and deep learning
Sep 21, 2022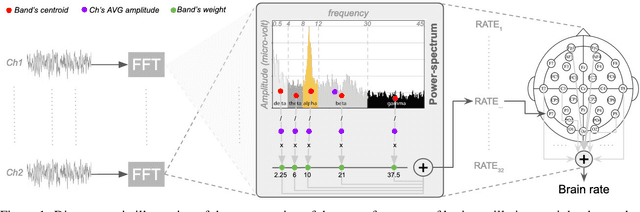
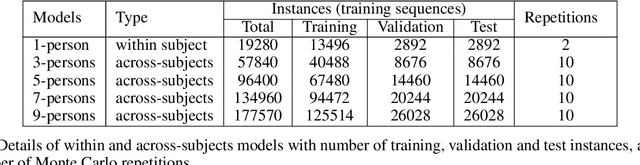
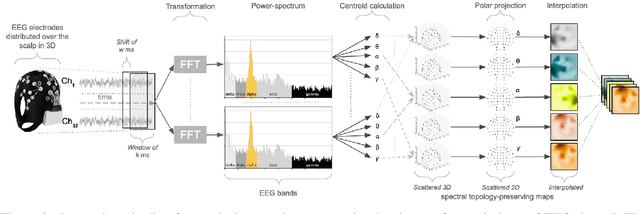

The principal reason for measuring mental workload is to quantify the cognitive cost of performing tasks to predict human performance. Unfortunately, a method for assessing mental workload that has general applicability does not exist yet. This research presents a novel self-supervised method for mental workload modelling from EEG data employing Deep Learning and a continuous brain rate, an index of cognitive activation, without requiring human declarative knowledge. This method is a convolutional recurrent neural network trainable with spatially preserving spectral topographic head-maps from EEG data to fit the brain rate variable. Findings demonstrate the capacity of the convolutional layers to learn meaningful high-level representations from EEG data since within-subject models had a test Mean Absolute Percentage Error average of 11%. The addition of a Long-Short Term Memory layer for handling sequences of high-level representations was not significant, although it did improve their accuracy. Findings point to the existence of quasi-stable blocks of learnt high-level representations of cognitive activation because they can be induced through convolution and seem not to be dependent on each other over time, intuitively matching the non-stationary nature of brain responses. Across-subject models, induced with data from an increasing number of participants, thus containing more variability, obtained a similar accuracy to the within-subject models. This highlights the potential generalisability of the induced high-level representations across people, suggesting the existence of subject-independent cognitive activation patterns. This research contributes to the body of knowledge by providing scholars with a novel computational method for mental workload modelling that aims to be generally applicable, does not rely on ad-hoc human-crafted models supporting replicability and falsifiability.
Comparing and extending the use of defeasible argumentation with quantitative data in real-world contexts
Jun 28, 2022



Dealing with uncertain, contradicting, and ambiguous information is still a central issue in Artificial Intelligence (AI). As a result, many formalisms have been proposed or adapted so as to consider non-monotonicity, with only a limited number of works and researchers performing any sort of comparison among them. A non-monotonic formalism is one that allows the retraction of previous conclusions or claims, from premises, in light of new evidence, offering some desirable flexibility when dealing with uncertainty. This research article focuses on evaluating the inferential capacity of defeasible argumentation, a formalism particularly envisioned for modelling non-monotonic reasoning. In addition to this, fuzzy reasoning and expert systems, extended for handling non-monotonicity of reasoning, are selected and employed as baselines, due to their vast and accepted use within the AI community. Computational trust was selected as the domain of application of such models. Trust is an ill-defined construct, hence, reasoning applied to the inference of trust can be seen as non-monotonic. Inference models were designed to assign trust scalars to editors of the Wikipedia project. In particular, argument-based models demonstrated more robustness than those built upon the baselines despite the knowledge bases or datasets employed. This study contributes to the body of knowledge through the exploitation of defeasible argumentation and its comparison to similar approaches. The practical use of such approaches coupled with a modular design that facilitates similar experiments was exemplified and their respective implementations made publicly available on GitHub [120, 121]. This work adds to previous works, empirically enhancing the generalisability of defeasible argumentation as a compelling approach to reason with quantitative data and uncertain knowledge.