 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Online Moderation Via LLM-Powered Counterfactual Simulations
Nov 10, 2025Online Social Networks (OSNs) widely adopt content moderation to mitigate the spread of abusive and toxic discourse. Nonetheless, the real effectiveness of moderation interventions remains unclear due to the high cost of data collection and limited experimental control. The latest developments in Natural Language Processing pave the way for a new evaluation approach. Large Language Models (LLMs) can be successfully leveraged to enhance Agent-Based Modeling and simulate human-like social behavior with unprecedented degree of believability. Yet, existing tools do not support simulation-based evaluation of moderation strategies. We fill this gap by designing a LLM-powered simulator of OSN conversations enabling a parallel, counterfactual simulation where toxic behavior is influenced by moderation interventions, keeping all else equal. We conduct extensive experiments, unveiling the psychological realism of OSN agents, the emergence of social contagion phenomena and the superior effectiveness of personalized moderation strategies.
Towards the Formalization of a Trustworthy AI for Mining Interpretable Models explOiting Sophisticated Algorithms
Oct 23, 2025Interpretable-by-design models are crucial for fostering trust, accountability, and safe adoption of automated decision-making models in real-world applications. In this paper we formalize the ground for the MIMOSA (Mining Interpretable Models explOiting Sophisticated Algorithms) framework, a comprehensive methodology for generating predictive models that balance interpretability with performance while embedding key ethical properties. We formally define here the supervised learning setting across diverse decision-making tasks and data types, including tabular data, time series, images, text, transactions, and trajectories. We characterize three major families of interpretable models: feature importance, rule, and instance based models. For each family, we analyze their interpretability dimensions, reasoning mechanisms, and complexity. Beyond interpretability, we formalize three critical ethical properties, namely causality, fairness, and privacy, providing formal definitions, evaluation metrics, and verification procedures for each. We then examine the inherent trade-offs between these properties and discuss how privacy requirements, fairness constraints, and causal reasoning can be embedded within interpretable pipelines. By evaluating ethical measures during model generation, this framework establishes the theoretical foundations for developing AI systems that are not only accurate and interpretable but also fair, privacy-preserving, and causally aware, i.e., trustworthy.
Fair Clustering with Clusterlets
May 03, 2025Given their widespread usage in the real world, the fairness of clustering methods has become of major interest. Theoretical results on fair clustering show that fairness enjoys transitivity: given a set of small and fair clusters, a trivial centroid-based clustering algorithm yields a fair clustering. Unfortunately, discovering a suitable starting clustering can be computationally expensive, rather complex or arbitrary. In this paper, we propose a set of simple \emph{clusterlet}-based fuzzy clustering algorithms that match single-class clusters, optimizing fair clustering. Matching leverages clusterlet distance, optimizing for classic clustering objectives, while also regularizing for fairness. Empirical results show that simple matching strategies are able to achieve high fairness, and that appropriate parameter tuning allows to achieve high cohesion and low overlap.
Explanations Go Linear: Interpretable and Individual Latent Encoding for Post-hoc Explainability
Apr 29, 2025



Post-hoc explainability is essential for understanding black-box machine learning models. Surrogate-based techniques are widely used for local and global model-agnostic explanations but have significant limitations. Local surrogates capture non-linearities but are computationally expensive and sensitive to parameters, while global surrogates are more efficient but struggle with complex local behaviors. In this paper, we present ILLUME, a flexible and interpretable framework grounded in representation learning, that can be integrated with various surrogate models to provide explanations for any black-box classifier. Specifically, our approach combines a globally trained surrogate with instance-specific linear transformations learned with a meta-encoder to generate both local and global explanations. Through extensive empirical evaluations, we demonstrate the effectiveness of ILLUME in producing feature attributions and decision rules that are not only accurate but also robust and faithful to the black-box, thus providing a unified explanation framework that effectively addresses the limitations of traditional surrogate methods.
MASCOTS: Model-Agnostic Symbolic COunterfactual explanations for Time Series
Mar 28, 2025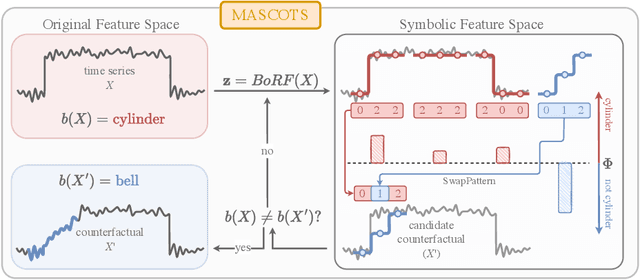
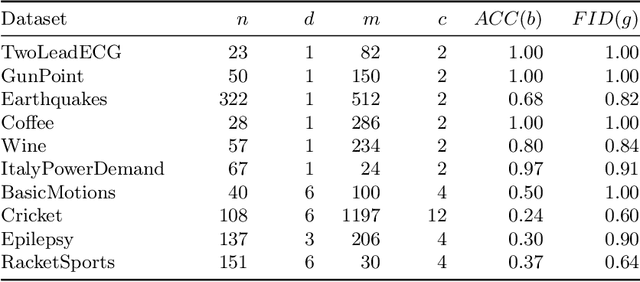

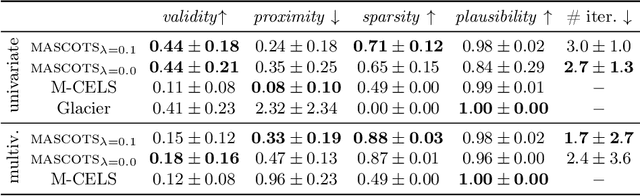
Counterfactual explanations provide an intuitive way to understand model decisions by identifying minimal changes required to alter an outcome. However, applying counterfactual methods to time series models remains challenging due to temporal dependencies, high dimensionality, and the lack of an intuitive human-interpretable representation. We introduce MASCOTS, a method that leverages the Bag-of-Receptive-Fields representation alongside symbolic transformations inspired by Symbolic Aggregate Approximation. By operating in a symbolic feature space, it enhances interpretability while preserving fidelity to the original data and model. Unlike existing approaches that either depend on model structure or autoencoder-based sampling, MASCOTS directly generates meaningful and diverse counterfactual observations in a model-agnostic manner, operating on both univariate and multivariate data. We evaluate MASCOTS on univariate and multivariate benchmark datasets, demonstrating comparable validity, proximity, and plausibility to state-of-the-art methods, while significantly improving interpretability and sparsity. Its symbolic nature allows for explanations that can be expressed visually, in natural language, or through semantic representations, making counterfactual reasoning more accessible and actionable.
A Frank System for Co-Evolutionary Hybrid Decision-Making
Mar 08, 2025We introduce Frank, a human-in-the-loop system for co-evolutionary hybrid decision-making aiding the user to label records from an un-labeled dataset. Frank employs incremental learning to ``evolve'' in parallel with the user's decisions, by training an interpretable machine learning model on the records labeled by the user. Furthermore, Frank advances state-of-the-art approaches by offering inconsistency controls, explanations, fairness checks, and bad-faith safeguards simultaneously. We evaluate our proposal by simulating the users' behavior with various levels of expertise and reliance on Frank's suggestions. The experiments show that Frank's intervention leads to improvements in the accuracy and the fairness of the decisions.
* 13 pages
Bridging the Gap in Hybrid Decision-Making Systems
Sep 28, 2024
We introduce BRIDGET, a novel human-in-the-loop system for hybrid decision-making, aiding the user to label records from an un-labeled dataset, attempting to ``bridge the gap'' between the two most popular Hybrid Decision-Making paradigms: those featuring the human in a leading position, and the other with a machine making most of the decisions. BRIDGET understands when either a machine or a human user should be in charge, dynamically switching between two statuses. In the different statuses, BRIDGET still fosters the human-AI interaction, either having a machine learning model assuming skeptical stances towards the user and offering them suggestions, or towards itself and calling the user back. We believe our proposal lays the groundwork for future synergistic systems involving a human and a machine decision-makers.
A Bag of Receptive Fields for Time Series Extrinsic Predictions
Nov 29, 2023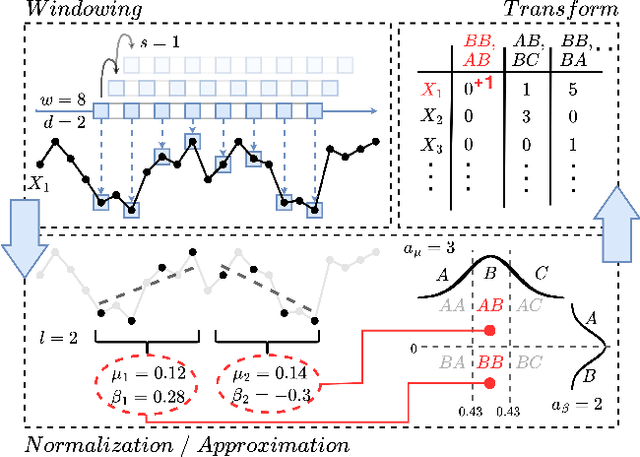
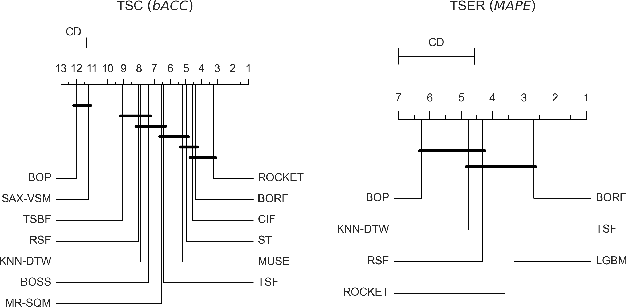
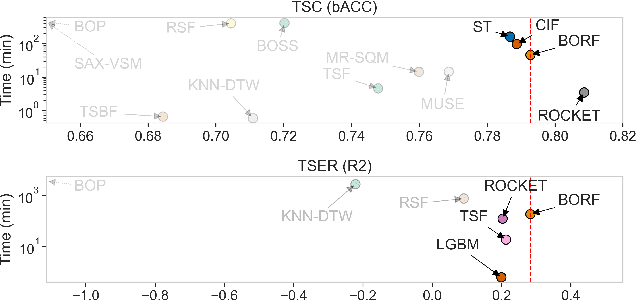
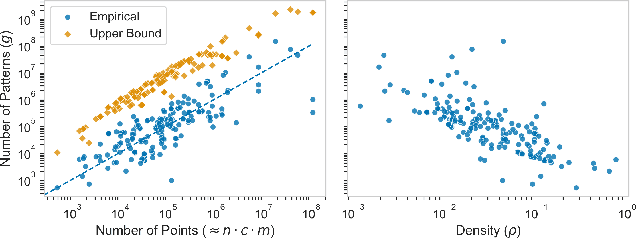
High-dimensional time series data poses challenges due to its dynamic nature, varying lengths, and presence of missing values. This kind of data requires extensive preprocessing, limiting the applicability of existing Time Series Classification and Time Series Extrinsic Regression techniques. For this reason, we propose BORF, a Bag-Of-Receptive-Fields model, which incorporates notions from time series convolution and 1D-SAX to handle univariate and multivariate time series with varying lengths and missing values. We evaluate BORF on Time Series Classification and Time Series Extrinsic Regression tasks using the full UEA and UCR repositories, demonstrating its competitive performance against state-of-the-art methods. Finally, we outline how this representation can naturally provide saliency and feature-based explanations.
Social Bias Probing: Fairness Benchmarking for Language Models
Nov 15, 2023Large language models have been shown to encode a variety of social biases, which carries the risk of downstream harms. While the impact of these biases has been recognized, prior methods for bias evaluation have been limited to binary association tests on small datasets, offering a constrained view of the nature of societal biases within language models. In this paper, we propose an original framework for probing language models for societal biases. We collect a probing dataset to analyze language models' general associations, as well as along the axes of societal categories, identities, and stereotypes. To this end, we leverage a novel perplexity-based fairness score. We curate a large-scale benchmarking dataset addressing drawbacks and limitations of existing fairness collections, expanding to a variety of different identities and stereotypes. When comparing our methodology with prior work, we demonstrate that biases within language models are more nuanced than previously acknowledged. In agreement with recent findings, we find that larger model variants exhibit a higher degree of bias. Moreover, we expose how identities expressing different religions lead to the most pronounced disparate treatments across all models.
Explainable Artificial Intelligence (XAI) 2.0: A Manifesto of Open Challenges and Interdisciplinary Research Directions
Oct 30, 2023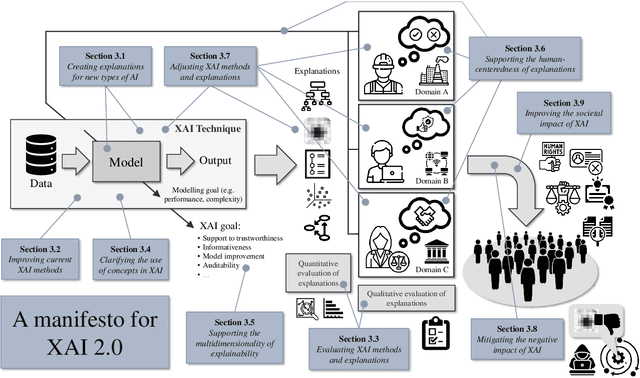
As systems based on opaque Artificial Intelligence (AI) continue to flourish in diverse real-world applications, understanding these black box models has become paramount. In response, Explainable AI (XAI) has emerged as a field of research with practical and ethical benefits across various domains. This paper not only highlights the advancements in XAI and its application in real-world scenarios but also addresses the ongoing challenges within XAI, emphasizing the need for broader perspectives and collaborative efforts. We bring together experts from diverse fields to identify open problems, striving to synchronize research agendas and accelerate XAI in practical applications. By fostering collaborative discussion and interdisciplinary cooperation, we aim to propel XAI forward, contributing to its continued success. Our goal is to put forward a comprehensive proposal for advancing XAI. To achieve this goal, we present a manifesto of 27 open problems categorized into nine categories. These challenges encapsulate the complexities and nuances of XAI and offer a road map for future research. For each problem, we provide promising research directions in the hope of harnessing the collective intelligence of interested stakeholders.