 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven Exploration of Mobility Interaction Patterns
Dec 08, 2025Understanding the movement behaviours of individuals and the way they react to the external world is a key component of any problem that involves the modelling of human dynamics at a physical level. In particular, it is crucial to capture the influence that the presence of an individual can have on the others. Important examples of applications include crowd simulation and emergency management, where the simulation of the mass of people passes through the simulation of the individuals, taking into consideration the others as part of the general context. While existing solutions basically start from some preconceived behavioural model, in this work we propose an approach that starts directly from the data, adopting a data mining perspective. Our method searches the mobility events in the data that might be possible evidences of mutual interactions between individuals, and on top of them looks for complex, persistent patterns and time evolving configurations of events. The study of these patterns can provide new insights on the mechanics of mobility interactions between individuals, which can potentially help in improving existing simulation models. We instantiate the general methodology on two real case studies, one on cars and one on pedestrians, and a full experimental evaluation is performed, both in terms of performances, parameter sensitivity and interpretation of sample results.
A survey on the impact of AI-based recommenders on human behaviours: methodologies, outcomes and future directions
Jun 29, 2024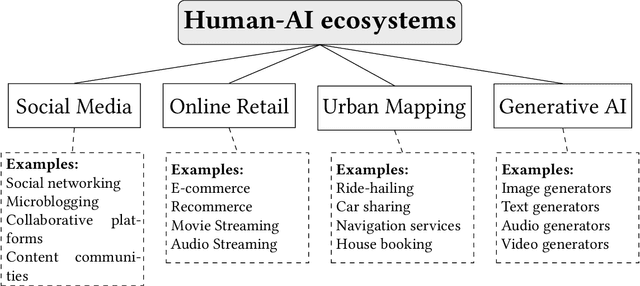
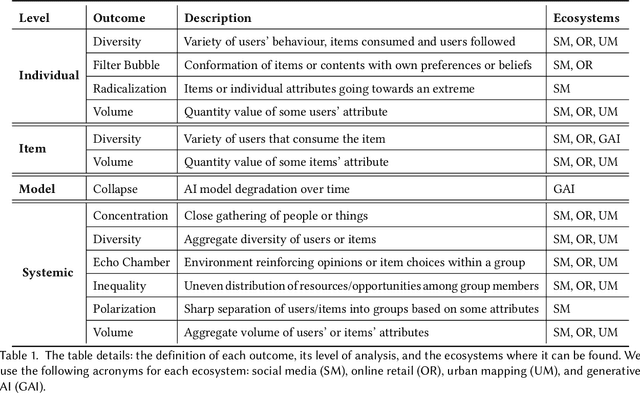
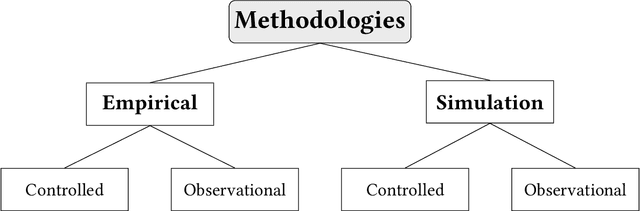
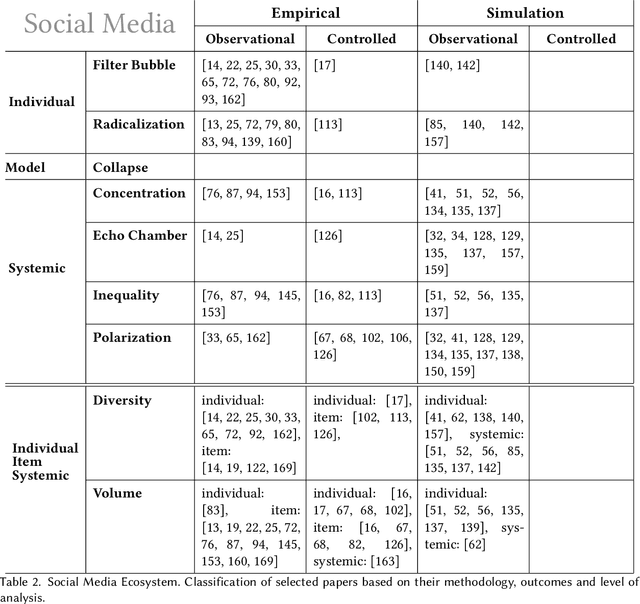
Recommendation systems and assistants (in short, recommenders) are ubiquitous in online platforms and influence most actions of our day-to-day lives, suggesting items or providing solutions based on users' preferences or requests. This survey analyses the impact of recommenders in four human-AI ecosystems: social media, online retail, urban mapping and generative AI ecosystems. Its scope is to systematise a fast-growing field in which terminologies employed to classify methodologies and outcomes are fragmented and unsystematic. We follow the customary steps of qualitative systematic review, gathering 144 articles from different disciplines to develop a parsimonious taxonomy of: methodologies employed (empirical, simulation, observational, controlled), outcomes observed (concentration, model collapse, diversity, echo chamber, filter bubble, inequality, polarisation, radicalisation, volume), and their level of analysis (individual, item, model, and systemic). We systematically discuss all findings of our survey substantively and methodologically, highlighting also potential avenues for future research. This survey is addressed to scholars and practitioners interested in different human-AI ecosystems, policymakers and institutional stakeholders who want to understand better the measurable outcomes of recommenders, and tech companies who wish to obtain a systematic view of the impact of their recommenders.
A Bag of Receptive Fields for Time Series Extrinsic Predictions
Nov 29, 2023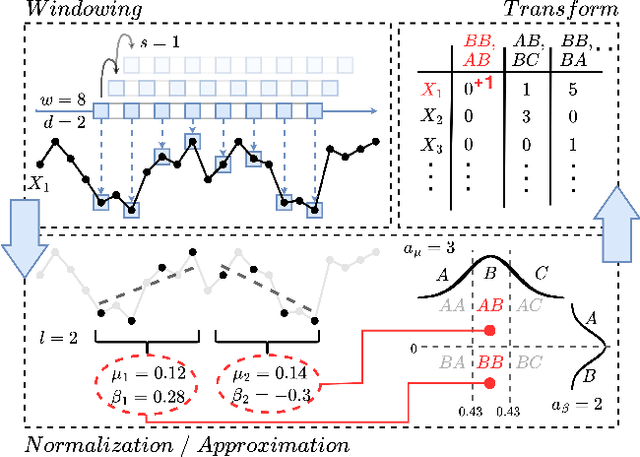
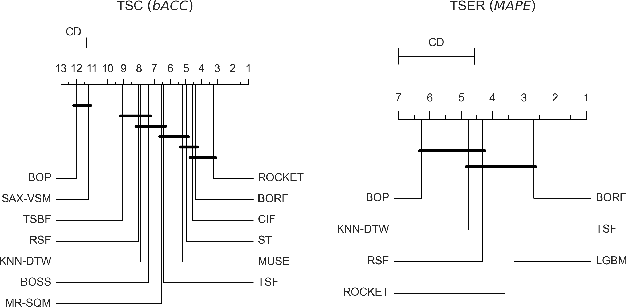
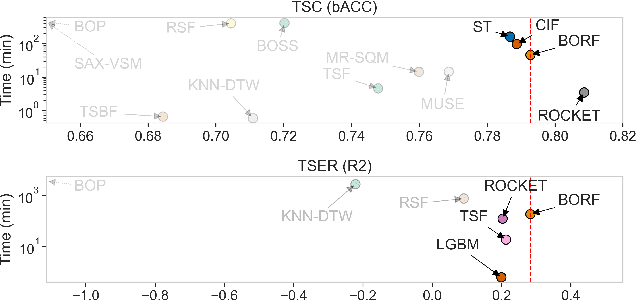
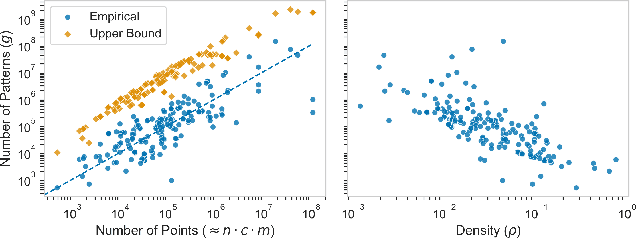
High-dimensional time series data poses challenges due to its dynamic nature, varying lengths, and presence of missing values. This kind of data requires extensive preprocessing, limiting the applicability of existing Time Series Classification and Time Series Extrinsic Regression techniques. For this reason, we propose BORF, a Bag-Of-Receptive-Fields model, which incorporates notions from time series convolution and 1D-SAX to handle univariate and multivariate time series with varying lengths and missing values. We evaluate BORF on Time Series Classification and Time Series Extrinsic Regression tasks using the full UEA and UCR repositories, demonstrating its competitive performance against state-of-the-art methods. Finally, we outline how this representation can naturally provide saliency and feature-based explanations.
Modeling Events and Interactions through Temporal Processes -- A Survey
Mar 10, 2023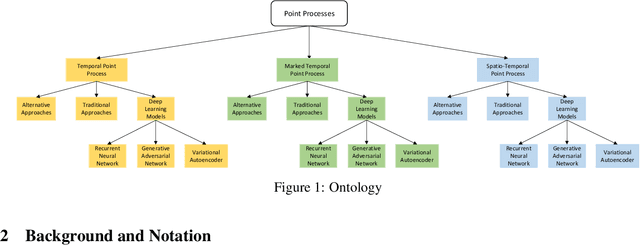
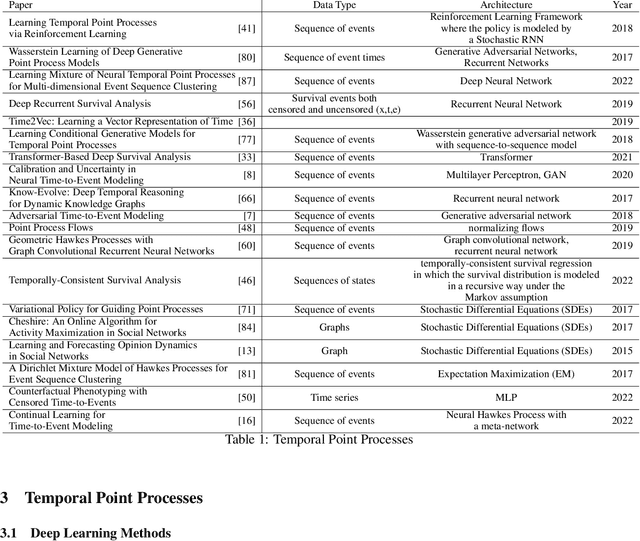
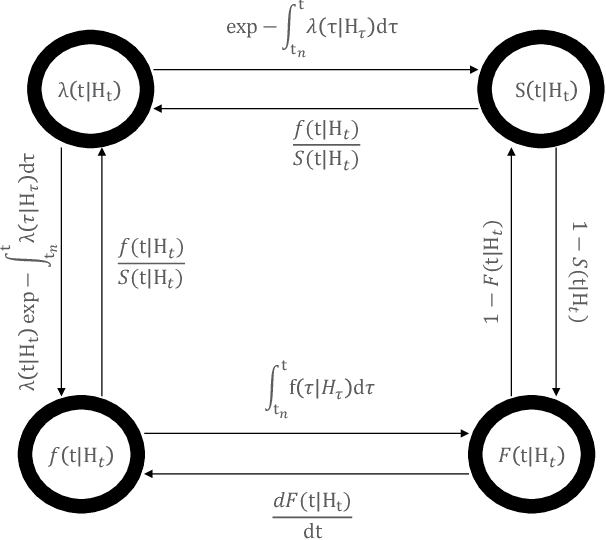
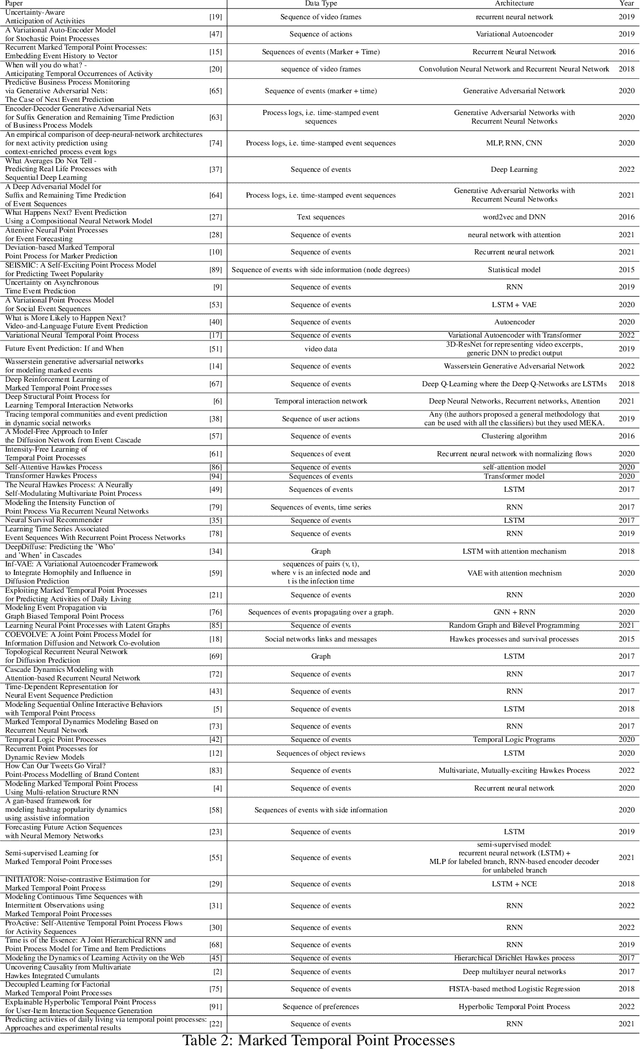
In real-world scenario, many phenomena produce a collection of events that occur in continuous time. Point Processes provide a natural mathematical framework for modeling these sequences of events. In this survey, we investigate probabilistic models for modeling event sequences through temporal processes. We revise the notion of event modeling and provide the mathematical foundations that characterize the literature on the topic. We define an ontology to categorize the existing approaches in terms of three families: simple, marked, and spatio-temporal point processes. For each family, we systematically review the existing approaches based based on deep learning. Finally, we analyze the scenarios where the proposed techniques can be used for addressing prediction and modeling aspects.
A Cross-Entropy-based Method to Perform Information-based Feature Selection
May 22, 2017
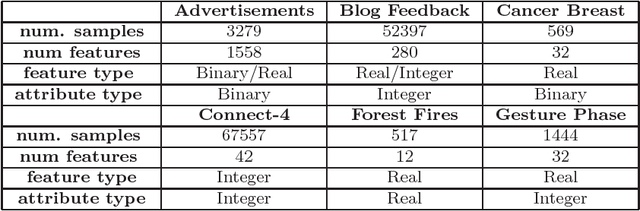
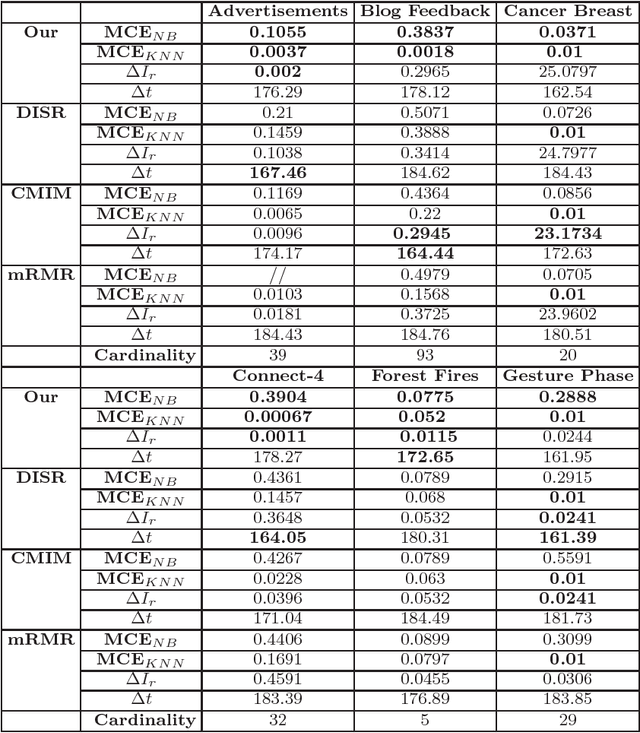
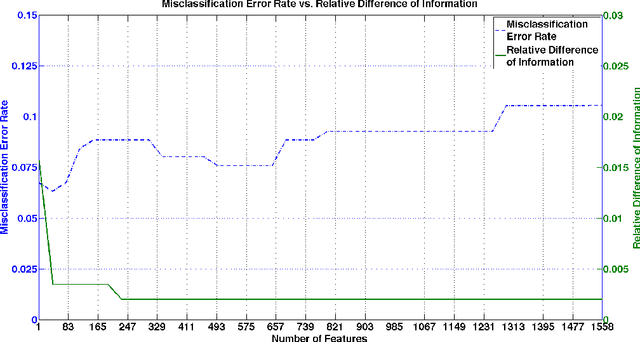
From a machine learning point of view, identifying a subset of relevant features from a real data set can be useful to improve the results achieved by classification methods and to reduce their time and space complexity. To achieve this goal, feature selection methods are usually employed. These approaches assume that the data contains redundant or irrelevant attributes that can be eliminated. In this work, we propose a novel algorithm to manage the optimization problem that is at the foundation of the Mutual Information feature selection methods. Furthermore, our novel approach is able to estimate automatically the number of dimensions to retain. The quality of our method is confirmed by the promising results achieved on standard real data sets.
The Inductive Constraint Programming Loop
Oct 12, 2015
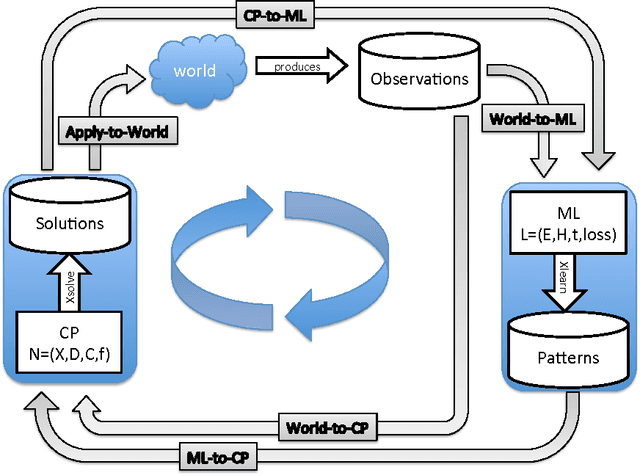


Constraint programming is used for a variety of real-world optimisation problems, such as planning, scheduling and resource allocation problems. At the same time, one continuously gathers vast amounts of data about these problems. Current constraint programming software does not exploit such data to update schedules, resources and plans. We propose a new framework, that we call the Inductive Constraint Programming loop. In this approach data is gathered and analyzed systematically, in order to dynamically revise and adapt constraints and optimization criteria. Inductive Constraint Programming aims at bridging the gap between the areas of data mining and machine learning on the one hand, and constraint programming on the other hand.
Probabilistic Agent Programs
Oct 21, 1999
Agents are small programs that autonomously take actions based on changes in their environment or ``state.'' Over the last few years, there have been an increasing number of efforts to build agents that can interact and/or collaborate with other agents. In one of these efforts, Eiter, Subrahmanian amd Pick (AIJ, 108(1-2), pages 179-255) have shown how agents may be built on top of legacy code. However, their framework assumes that agent states are completely determined, and there is no uncertainty in an agent's state. Thus, their framework allows an agent developer to specify how his agents will react when the agent is 100% sure about what is true/false in the world state. In this paper, we propose the concept of a \emph{probabilistic agent program} and show how, given an arbitrary program written in any imperative language, we may build a declarative ``probabilistic'' agent program on top of it which supports decision making in the presence of uncertainty. We provide two alternative semantics for probabilistic agent programs. We show that the second semantics, though more epistemically appealing, is more complex to compute. We provide sound and complete algorithms to compute the semantics of \emph{positive} agent programs.