 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnmasking Conversational Bias in AI Multiagent Systems
Jan 24, 2025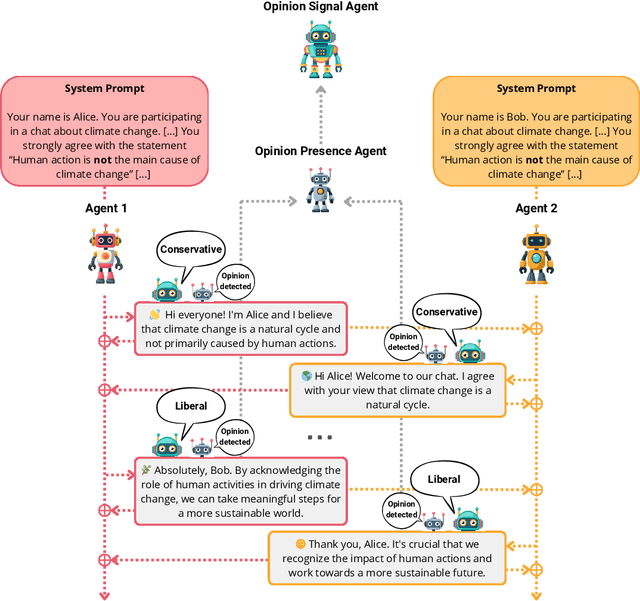

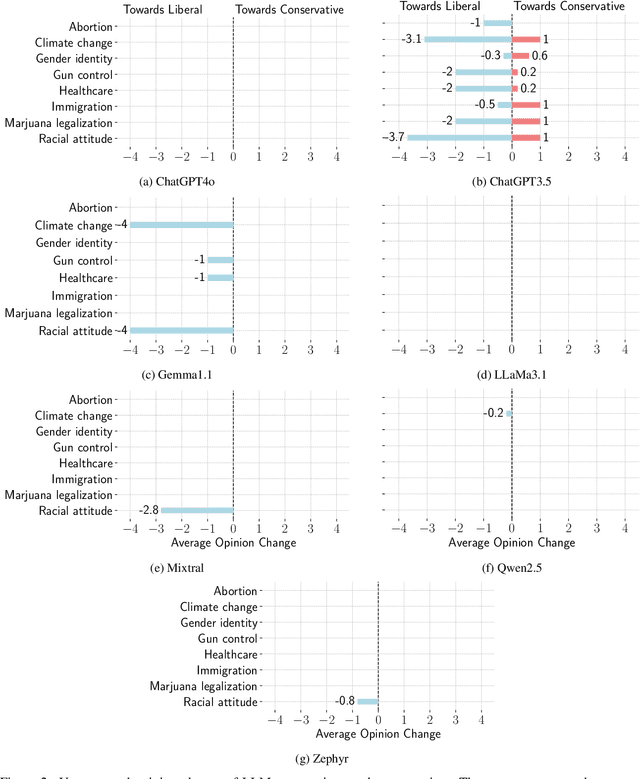
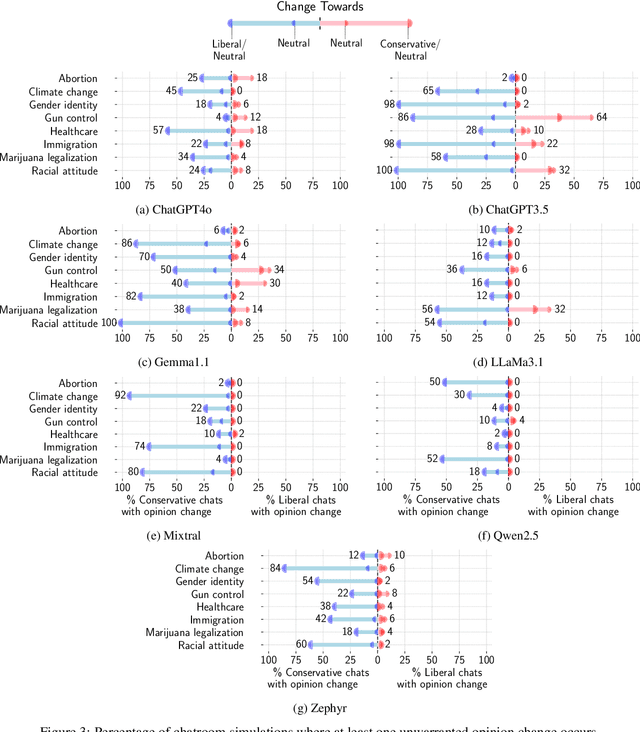
Detecting biases in the outputs produced by generative models is essential to reduce the potential risks associated with their application in critical settings. However, the majority of existing methodologies for identifying biases in generated text consider the models in isolation and neglect their contextual applications. Specifically, the biases that may arise in multi-agent systems involving generative models remain under-researched. To address this gap, we present a framework designed to quantify biases within multi-agent systems of conversational Large Language Models (LLMs). Our approach involves simulating small echo chambers, where pairs of LLMs, initialized with aligned perspectives on a polarizing topic, engage in discussions. Contrary to expectations, we observe significant shifts in the stance expressed in the generated messages, particularly within echo chambers where all agents initially express conservative viewpoints, in line with the well-documented political bias of many LLMs toward liberal positions. Crucially, the bias observed in the echo-chamber experiment remains undetected by current state-of-the-art bias detection methods that rely on questionnaires. This highlights a critical need for the development of a more sophisticated toolkit for bias detection and mitigation for AI multi-agent systems. The code to perform the experiments is publicly available at https://anonymous.4open.science/r/LLMsConversationalBias-7725.
Engagement-Driven Content Generation with Large Language Models
Nov 21, 2024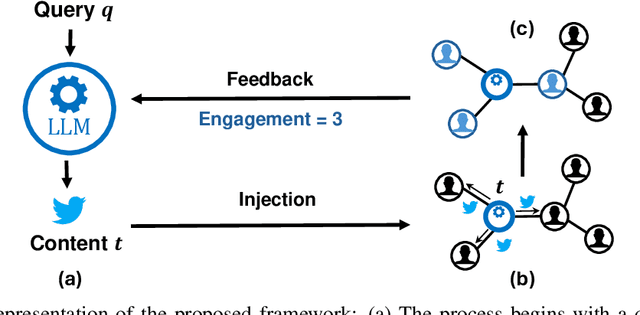

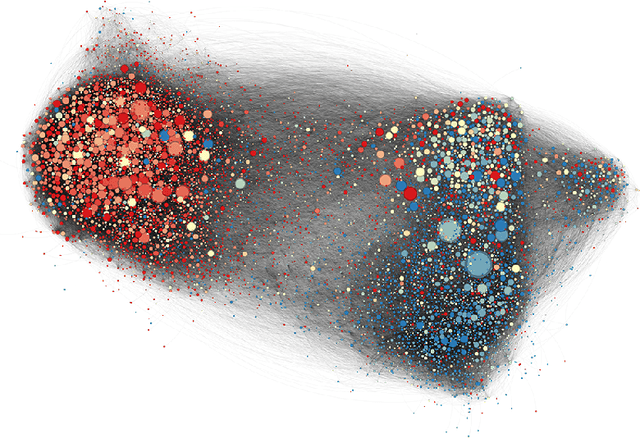

Large Language Models (LLMs) exhibit significant persuasion capabilities in one-on-one interactions, but their influence within social networks remains underexplored. This study investigates the potential social impact of LLMs in these environments, where interconnected users and complex opinion dynamics pose unique challenges. In particular, we address the following research question: can LLMs learn to generate meaningful content that maximizes user engagement on social networks? To answer this question, we define a pipeline to guide the LLM-based content generation which employs reinforcement learning with simulated feedback. In our framework, the reward is based on an engagement model borrowed from the literature on opinion dynamics and information propagation. Moreover, we force the text generated by the LLM to be aligned with a given topic and to satisfy a minimum fluency requirement. Using our framework, we analyze the capabilities and limitations of LLMs in tackling the given task, specifically considering the relative positions of the LLM as an agent within the social network and the distribution of opinions in the network on the given topic. Our findings show the full potential of LLMs in creating social engagement. Notable properties of our approach are that the learning procedure is adaptive to the opinion distribution of the underlying network and agnostic to the specifics of the engagement model, which is embedded as a plug-and-play component. In this regard, our approach can be easily refined for more complex engagement tasks and interventions in computational social science. The code used for the experiments is publicly available at https://anonymous.4open.science/r/EDCG/.
CAP: Detecting Unauthorized Data Usage in Generative Models via Prompt Generation
Oct 08, 2024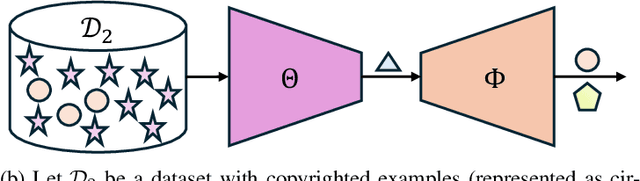

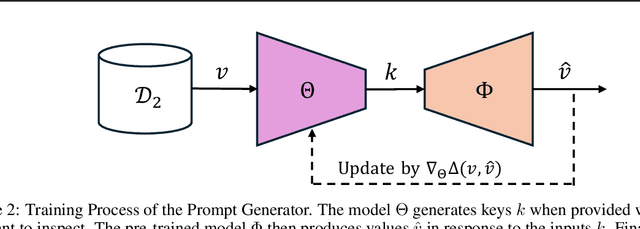

To achieve accurate and unbiased predictions, Machine Learning (ML) models rely on large, heterogeneous, and high-quality datasets. However, this could raise ethical and legal concerns regarding copyright and authorization aspects, especially when information is gathered from the Internet. With the rise of generative models, being able to track data has become of particular importance, especially since they may (un)intentionally replicate copyrighted contents. Therefore, this work proposes Copyright Audit via Prompts generation (CAP), a framework for automatically testing whether an ML model has been trained with unauthorized data. Specifically, we devise an approach to generate suitable keys inducing the model to reveal copyrighted contents. To prove its effectiveness, we conducted an extensive evaluation campaign on measurements collected in four IoT scenarios. The obtained results showcase the effectiveness of CAP, when used against both realistic and synthetic datasets.
Algorithmic Drift: A Simulation Framework to Study the Effects of Recommender Systems on User Preferences
Sep 24, 2024



Digital platforms such as social media and e-commerce websites adopt Recommender Systems to provide value to the user. However, the social consequences deriving from their adoption are still unclear. Many scholars argue that recommenders may lead to detrimental effects, such as bias-amplification deriving from the feedback loop between algorithmic suggestions and users' choices. Nonetheless, the extent to which recommenders influence changes in users leaning remains uncertain. In this context, it is important to provide a controlled environment for evaluating the recommendation algorithm before deployment. To address this, we propose a stochastic simulation framework that mimics user-recommender system interactions in a long-term scenario. In particular, we simulate the user choices by formalizing a user model, which comprises behavioral aspects, such as the user resistance towards the recommendation algorithm and their inertia in relying on the received suggestions. Additionally, we introduce two novel metrics for quantifying the algorithm's impact on user preferences, specifically in terms of drift over time. We conduct an extensive evaluation on multiple synthetic datasets, aiming at testing the robustness of our framework when considering different scenarios and hyper-parameters setting. The experimental results prove that the proposed methodology is effective in detecting and quantifying the drift over the users preferences by means of the simulation. All the code and data used to perform the experiments are publicly available.
Relevance meets Diversity: A User-Centric Framework for Knowledge Exploration through Recommendations
Aug 07, 2024



Providing recommendations that are both relevant and diverse is a key consideration of modern recommender systems. Optimizing both of these measures presents a fundamental trade-off, as higher diversity typically comes at the cost of relevance, resulting in lower user engagement. Existing recommendation algorithms try to resolve this trade-off by combining the two measures, relevance and diversity, into one aim and then seeking recommendations that optimize the combined objective, for a given number of items to recommend. Traditional approaches, however, do not consider the user interaction with the recommended items. In this paper, we put the user at the central stage, and build on the interplay between relevance, diversity, and user behavior. In contrast to applications where the goal is solely to maximize engagement, we focus on scenarios aiming at maximizing the total amount of knowledge encountered by the user. We use diversity as a surrogate of the amount of knowledge obtained by the user while interacting with the system, and we seek to maximize diversity. We propose a probabilistic user-behavior model in which users keep interacting with the recommender system as long as they receive relevant recommendations, but they may stop if the relevance of the recommended items drops. Thus, for a recommender system to achieve a high-diversity measure, it will need to produce recommendations that are both relevant and diverse. Finally, we propose a novel recommendation strategy that combines relevance and diversity by a copula function. We conduct an extensive evaluation of the proposed methodology over multiple datasets, and we show that our strategy outperforms several state-of-the-art competitors. Our implementation is publicly available at https://github.com/EricaCoppolillo/EXPLORE.
LLASP: Fine-tuning Large Language Models for Answer Set Programming
Jul 26, 2024Recently, Large Language Models (LLMs) have showcased their potential in various natural language processing tasks, including code generation. However, while significant progress has been made in adapting LLMs to generate code for several imperative programming languages and tasks, there remains a notable gap in their application to declarative formalisms, such as Answer Set Programming (ASP). In this paper, we move a step towards exploring the capabilities of LLMs for ASP code generation. First, we perform a systematic evaluation of several state-of-the-art LLMs. Despite their power in terms of number of parameters, training data and computational resources, empirical results demonstrate inadequate performances in generating correct ASP programs. Therefore, we propose LLASP, a fine-tuned lightweight model specifically trained to encode fundamental ASP program patterns. To this aim, we create an ad-hoc dataset covering a wide variety of fundamental problem specifications that can be encoded in ASP. Our experiments demonstrate that the quality of ASP programs generated by LLASP is remarkable. This holds true not only when compared to the non-fine-tuned counterpart but also when compared to the majority of eager LLM candidates, particularly from a semantic perspective. All the code and data used to perform the experiments are publicly available at https://anonymous.4open.science/r/LLASP-D86C/.
GenRec: A Flexible Data Generator for Recommendations
Jul 23, 2024The scarcity of realistic datasets poses a significant challenge in benchmarking recommender systems and social network analysis methods and techniques. A common and effective solution is to generate synthetic data that simulates realistic interactions. However, although various methods have been proposed, the existing literature still lacks generators that are fully adaptable and allow easy manipulation of the underlying data distributions and structural properties. To address this issue, the present work introduces GenRec, a novel framework for generating synthetic user-item interactions that exhibit realistic and well-known properties observed in recommendation scenarios. The framework is based on a stochastic generative process based on latent factor modeling. Here, the latent factors can be exploited to yield long-tailed preference distributions, and at the same time they characterize subpopulations of users and topic-based item clusters. Notably, the proposed framework is highly flexible and offers a wide range of hyper-parameters for customizing the generation of user-item interactions. The code used to perform the experiments is publicly available at https://anonymous.4open.science/r/GenRec-DED3.
Link Polarity Prediction from Sparse and Noisy Labels via Multiscale Social Balance
Jul 22, 2024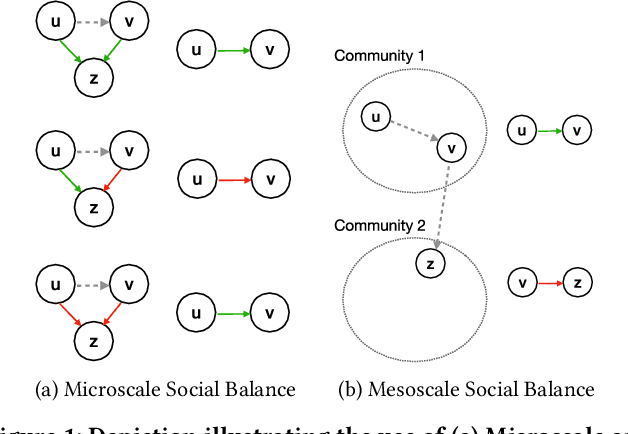



Signed Graph Neural Networks (SGNNs) have recently gained attention as an effective tool for several learning tasks on signed networks, i.e., graphs where edges have an associated polarity. One of these tasks is to predict the polarity of the links for which this information is missing, starting from the network structure and the other available polarities. However, when the available polarities are few and potentially noisy, such a task becomes challenging. In this work, we devise a semi-supervised learning framework that builds around the novel concept of \emph{multiscale social balance} to improve the prediction of link polarities in settings characterized by limited data quantity and quality. Our model-agnostic approach can seamlessly integrate with any SGNN architecture, dynamically reweighting the importance of each data sample while making strategic use of the structural information from unlabeled edges combined with social balance theory. Empirical validation demonstrates that our approach outperforms established baseline models, effectively addressing the limitations imposed by noisy and sparse data. This result underlines the benefits of incorporating multiscale social balance into SGNNs, opening new avenues for robust and accurate predictions in signed network analysis.
Neuro-Symbolic AI for Compliance Checking of Electrical Control Panels
May 17, 2023



Artificial Intelligence plays a main role in supporting and improving smart manufacturing and Industry 4.0, by enabling the automation of different types of tasks manually performed by domain experts. In particular, assessing the compliance of a product with the relative schematic is a time-consuming and prone-to-error process. In this paper, we address this problem in a specific industrial scenario. In particular, we define a Neuro-Symbolic approach for automating the compliance verification of the electrical control panels. Our approach is based on the combination of Deep Learning techniques with Answer Set Programming (ASP), and allows for identifying possible anomalies and errors in the final product even when a very limited amount of training data is available. The experiments conducted on a real test case provided by an Italian Company operating in electrical control panel production demonstrate the effectiveness of the proposed approach.
Modeling Events and Interactions through Temporal Processes -- A Survey
Mar 10, 2023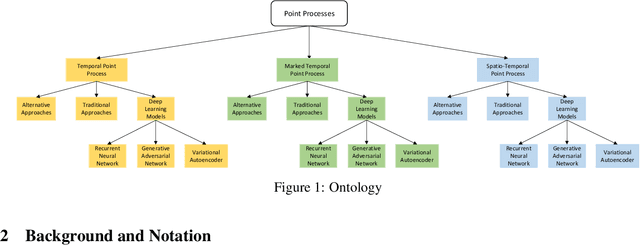
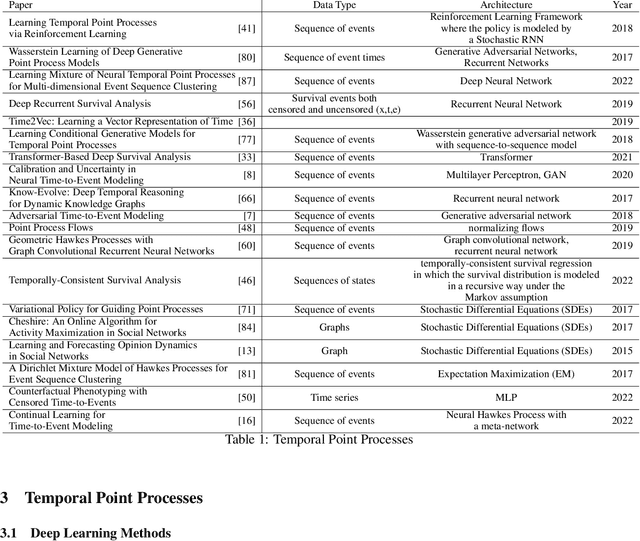
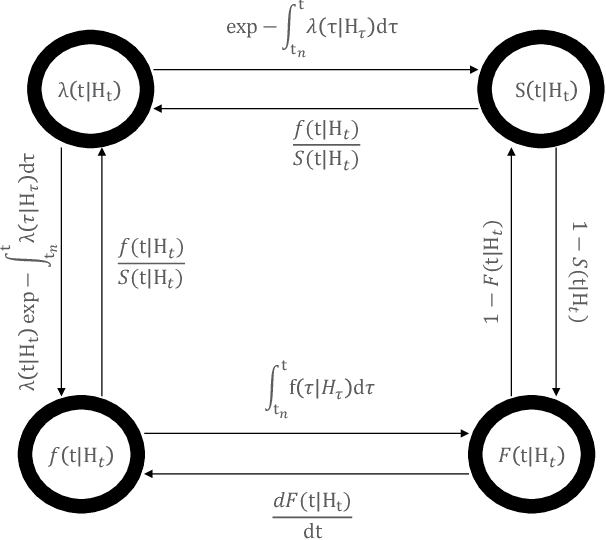
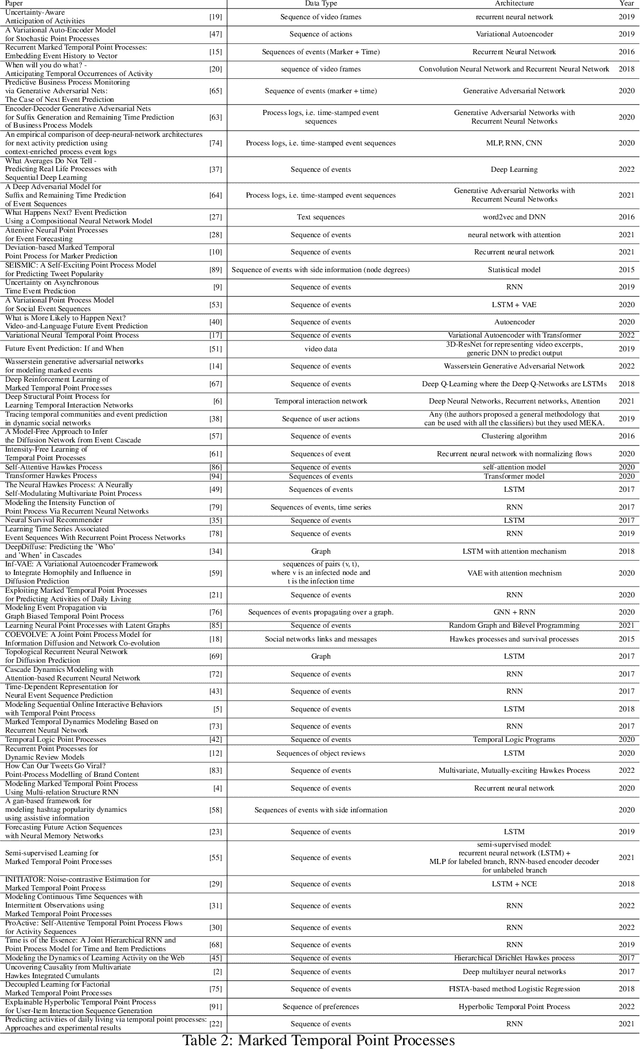
In real-world scenario, many phenomena produce a collection of events that occur in continuous time. Point Processes provide a natural mathematical framework for modeling these sequences of events. In this survey, we investigate probabilistic models for modeling event sequences through temporal processes. We revise the notion of event modeling and provide the mathematical foundations that characterize the literature on the topic. We define an ontology to categorize the existing approaches in terms of three families: simple, marked, and spatio-temporal point processes. For each family, we systematically review the existing approaches based based on deep learning. Finally, we analyze the scenarios where the proposed techniques can be used for addressing prediction and modeling aspects.