 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLAST: Benchmarking LLMs with ASP-based Structured Testing
Apr 24, 2026Large Language Models (LLMs) have demonstrated remarkable performance across a broad spectrum of tasks, including natural language understanding, dialogue systems, and code generation. Despite evident progress, less attention has been paid to their effectiveness in handling declarative paradigms such as Answer Set Programming (ASP), to date. In this paper we introduce BLAST: The first dedicated benchmarking methodology and associated dataset for evaluating the accuracy of LLMs in generating ASP code. BLAST provides a structured evaluation framework featuring two novel semantic metrics tailored to ASP code generation. The paper presents the results of an empirical evaluation involving ten well-established graph-related problems from the ASP literature and a diverse set of eight state-of-the-art LLMs.
Looking Beyond Accuracy: A Holistic Benchmark of ECG Foundation Models
Jan 29, 2026The electrocardiogram (ECG) is a cost-effective, highly accessible and widely employed diagnostic tool. With the advent of Foundation Models (FMs), the field of AI-assisted ECG interpretation has begun to evolve, as they enable model reuse across different tasks by relying on embeddings. However, to responsibly employ FMs, it is crucial to rigorously assess to which extent the embeddings they produce are generalizable, particularly in error-sensitive domains such as healthcare. Although prior works have already addressed the problem of benchmarking ECG-expert FMs, they focus predominantly on the evaluation of downstream performance. To fill this gap, this study aims to find an in-depth, comprehensive benchmarking framework for FMs, with a specific focus on ECG-expert ones. To this aim, we introduce a benchmark methodology that complements performance-based evaluation with representation-level analysis, leveraging SHAP and UMAP techniques. Furthermore, we rely on the methodology for carrying out an extensive evaluation of several ECG-expert FMs pretrained via state-of-the-art techniques over different cross-continental datasets and data availability settings; this includes ones featuring data scarcity, a fairly common situation in real-world medical scenarios. Experimental results show that our benchmarking protocol provides a rich insight of ECG-expert FMs' embedded patterns, enabling a deeper understanding of their representational structure and generalizability.
ASP-based Multi-shot Reasoning via DLV2 with Incremental Grounding
Dec 24, 2024DLV2 is an AI tool for Knowledge Representation and Reasoning which supports Answer Set Programming (ASP) - a logic-based declarative formalism, successfully used in both academic and industrial applications. Given a logic program modelling a computational problem, an execution of DLV2 produces the so-called answer sets that correspond one-to-one to the solutions to the problem at hand. The computational process of DLV2 relies on the typical Ground & Solve approach where the grounding step transforms the input program into a new, equivalent ground program, and the subsequent solving step applies propositional algorithms to search for the answer sets. Recently, emerging applications in contexts such as stream reasoning and event processing created a demand for multi-shot reasoning: here, the system is expected to be reactive while repeatedly executed over rapidly changing data. In this work, we present a new incremental reasoner obtained from the evolution of DLV2 towards iterated reasoning. Rather than restarting the computation from scratch, the system remains alive across repeated shots, and it incrementally handles the internal grounding process. At each shot, the system reuses previous computations for building and maintaining a large, more general ground program, from which a smaller yet equivalent portion is determined and used for computing answer sets. Notably, the incremental process is performed in a completely transparent fashion for the user. We describe the system, its usage, its applicability and performance in some practically relevant domains. Under consideration in Theory and Practice of Logic Programming (TPLP).
LLASP: Fine-tuning Large Language Models for Answer Set Programming
Jul 26, 2024Recently, Large Language Models (LLMs) have showcased their potential in various natural language processing tasks, including code generation. However, while significant progress has been made in adapting LLMs to generate code for several imperative programming languages and tasks, there remains a notable gap in their application to declarative formalisms, such as Answer Set Programming (ASP). In this paper, we move a step towards exploring the capabilities of LLMs for ASP code generation. First, we perform a systematic evaluation of several state-of-the-art LLMs. Despite their power in terms of number of parameters, training data and computational resources, empirical results demonstrate inadequate performances in generating correct ASP programs. Therefore, we propose LLASP, a fine-tuned lightweight model specifically trained to encode fundamental ASP program patterns. To this aim, we create an ad-hoc dataset covering a wide variety of fundamental problem specifications that can be encoded in ASP. Our experiments demonstrate that the quality of ASP programs generated by LLASP is remarkable. This holds true not only when compared to the non-fine-tuned counterpart but also when compared to the majority of eager LLM candidates, particularly from a semantic perspective. All the code and data used to perform the experiments are publicly available at https://anonymous.4open.science/r/LLASP-D86C/.
Data Augmentation: a Combined Inductive-Deductive Approach featuring Answer Set Programming
Oct 22, 2023Although the availability of a large amount of data is usually given for granted, there are relevant scenarios where this is not the case; for instance, in the biomedical/healthcare domain, some applications require to build huge datasets of proper images, but the acquisition of such images is often hard for different reasons (e.g., accessibility, costs, pathology-related variability), thus causing limited and usually imbalanced datasets. Hence, the need for synthesizing photo-realistic images via advanced Data Augmentation techniques is crucial. In this paper we propose a hybrid inductive-deductive approach to the problem; in particular, starting from a limited set of real labeled images, the proposed framework makes use of logic programs for declaratively specifying the structure of new images, that is guaranteed to comply with both a set of constraints coming from the domain knowledge and some specific desiderata. The resulting labeled images undergo a dedicated process based on Deep Learning in charge of creating photo-realistic images that comply with the generated label.
A Formal Comparison between Datalog-based Languages for Stream Reasoning (extended version)
Aug 26, 2022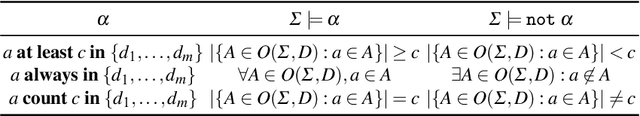
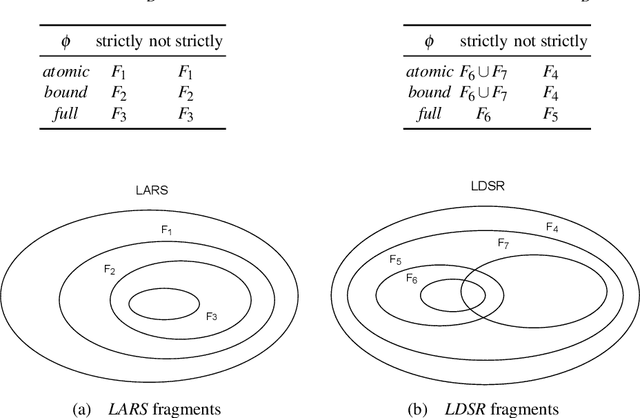
The paper investigates the relative expressiveness of two logic-based languages for reasoning over streams, namely LARS Programs -- the language of the Logic-based framework for Analytic Reasoning over Streams called LARS -- and LDSR -- the language of the recent extension of the I-DLV system for stream reasoning called I-DLV-sr. Although these two languages build over Datalog, they do differ both in syntax and semantics. To reconcile their expressive capabilities for stream reasoning, we define a comparison framework that allows us to show that, without any restrictions, the two languages are incomparable and to identify fragments of each language that can be expressed via the other one.
I-DLV-sr: A Stream Reasoning System based on I-DLV
Aug 05, 2021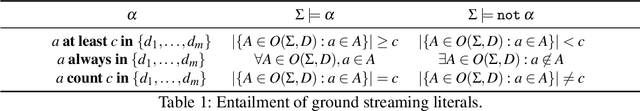
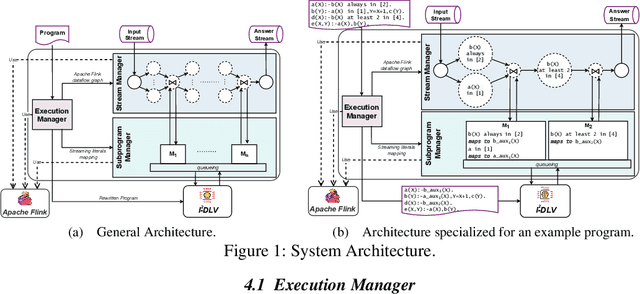
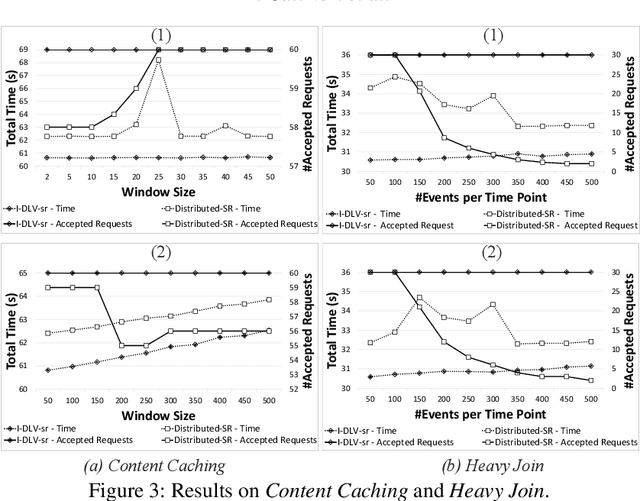
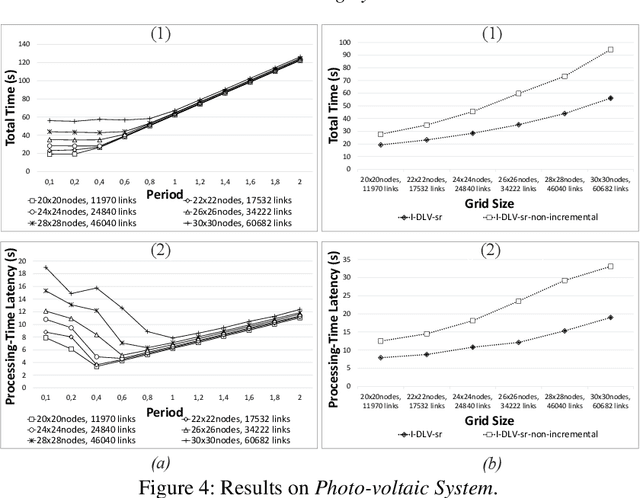
We introduce a novel logic-based system for reasoning over data streams, which relies on a framework enabling a tight, fine-tuned interaction between Apache Flink and the I^2-DLV system. The architecture allows to take advantage from both the powerful distributed stream processing capabilities of Flink and the incremental reasoning capabilities of I^2-DLV based on overgrounding techniques. Besides the system architecture, we illustrate the supported input language and its modeling capabilities, and discuss the results of an experimental activity aimed at assessing the viability of the approach. This paper is under consideration in Theory and Practice of Logic Programming (TPLP).
A Machine Learning guided Rewriting Approach for ASP Logic Programs
Sep 22, 2020
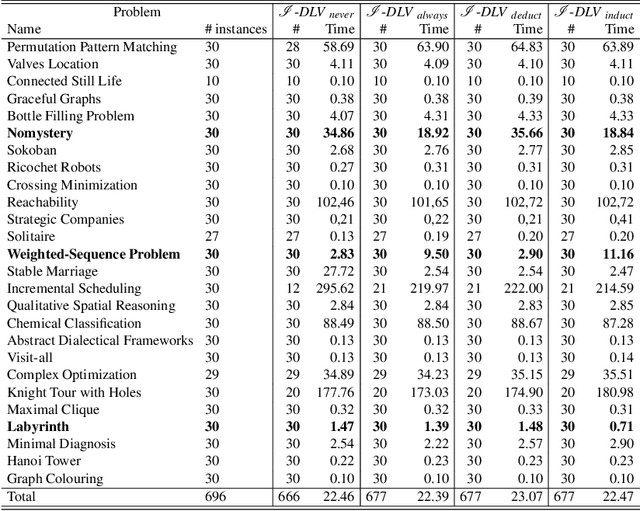
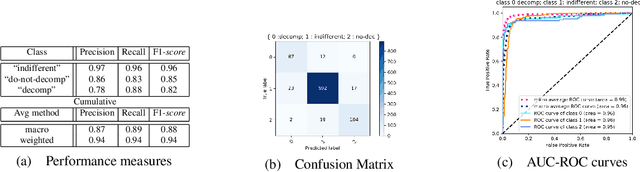
Answer Set Programming (ASP) is a declarative logic formalism that allows to encode computational problems via logic programs. Despite the declarative nature of the formalism, some advanced expertise is required, in general, for designing an ASP encoding that can be efficiently evaluated by an actual ASP system. A common way for trying to reduce the burden of manually tweaking an ASP program consists in automatically rewriting the input encoding according to suitable techniques, for producing alternative, yet semantically equivalent, ASP programs. However, rewriting does not always grant benefits in terms of performance; hence, proper means are needed for predicting their effects with this respect. In this paper we describe an approach based on Machine Learning (ML) to automatically decide whether to rewrite. In particular, given an ASP program and a set of input facts, our approach chooses whether and how to rewrite input rules based on a set of features measuring their structural properties and domain information. To this end, a Multilayer Perceptrons model has then been trained to guide the ASP grounder I-DLV on rewriting input rules. We report and discuss the results of an experimental evaluation over a prototypical implementation.
* In Proceedings ICLP 2020, arXiv:2009.09158
Precomputing Datalog evaluation plans in large-scale scenarios
Jul 29, 2019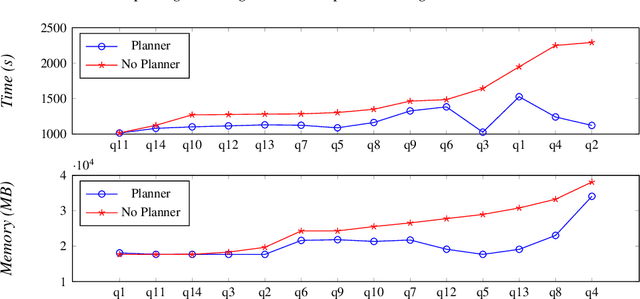
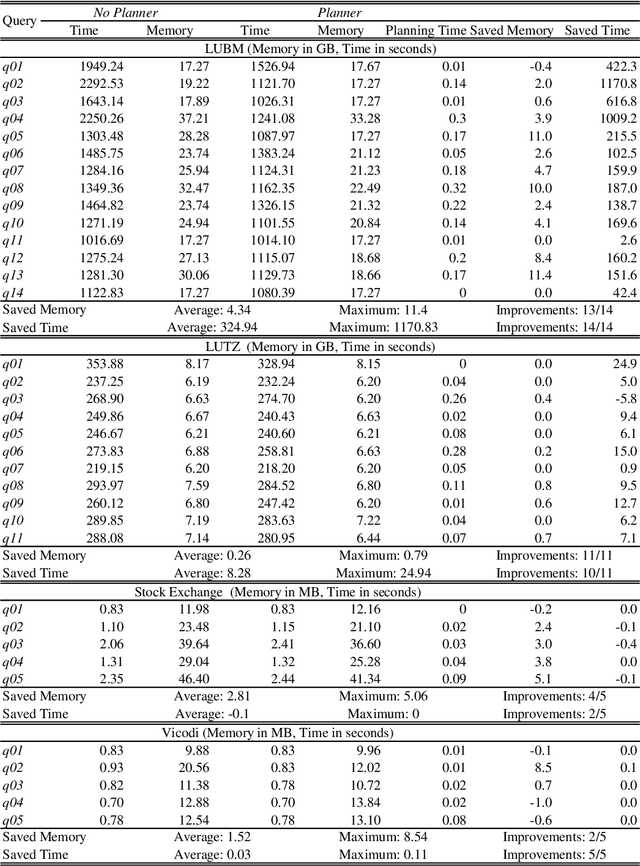
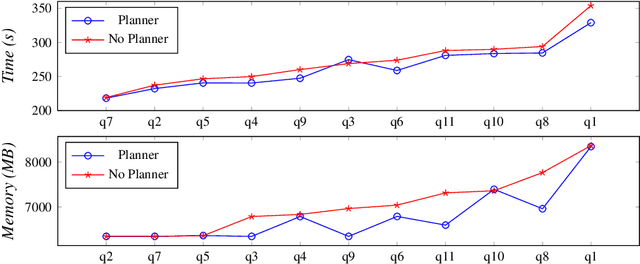
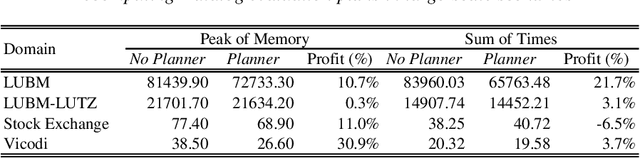
With the more and more growing demand for semantic Web services over large databases, an efficient evaluation of Datalog queries is arousing a renewed interest among researchers and industry experts. In this scenario, to reduce memory consumption and possibly optimize execution times, the paper proposes novel techniques to determine an optimal indexing schema for the underlying database together with suitable body-orderings for the Datalog rules. The new approach is compared with the standard execution plans implemented in DLV over widely used ontological benchmarks. The results confirm that the memory usage can be significantly reduced without paying any cost in efficiency. This paper is under consideration in Theory and Practice of Logic Programming (TPLP).
Incremental Answer Set Programming with Overgrounding
Jul 22, 2019
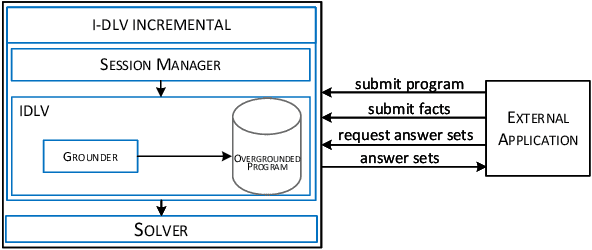
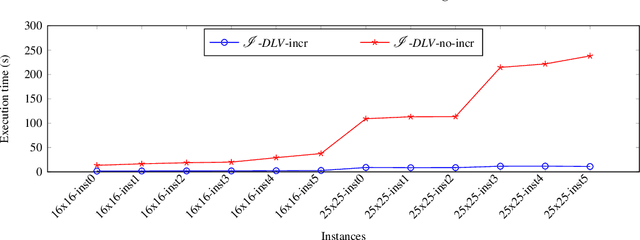
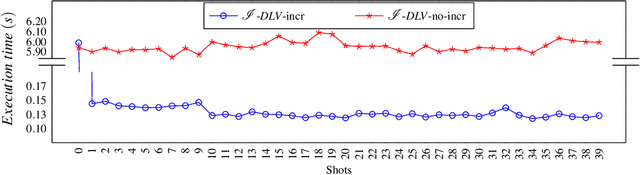
Repeated executions of reasoning tasks for varying inputs are necessary in many applicative settings, such as stream reasoning. In this context, we propose an incremental grounding approach for the answer set semantics. We focus on the possibility of generating incrementally larger ground logic programs equivalent to a given non-ground one; so called overgrounded programs can be reused in combination with deliberately many different sets of inputs. Updating overgrounded programs requires a small effort, thus making the instantiation of logic programs considerably faster when grounding is repeated on a series of inputs similar to each other. Notably, the proposed approach works "under the hood", relieving designers of logic programs from controlling technical aspects of grounding engines and answer set systems. In this work we present the theoretical basis of the proposed incremental grounding technique, we illustrate the consequent repeated evaluation strategy and report about our experiments. This paper is under consideration in Theory and Practice of Logic Programming (TPLP).