 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNavigating Taxonomic Expansions of Entity Sets Driven by Knowledge Bases
Dec 17, 2025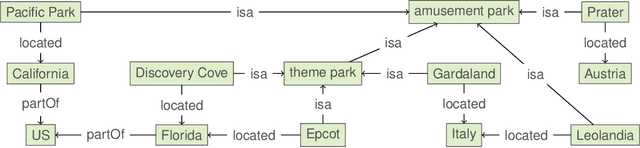

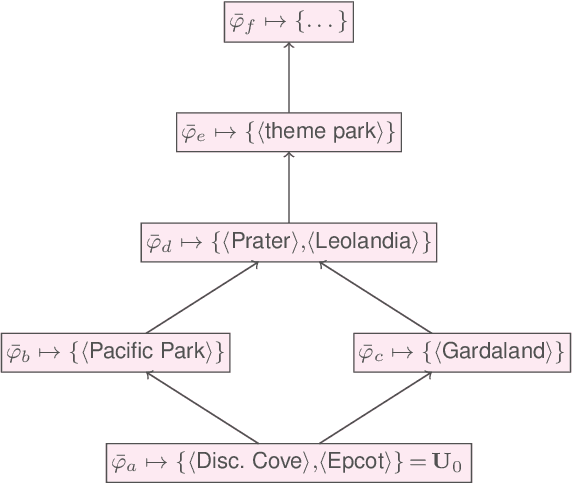

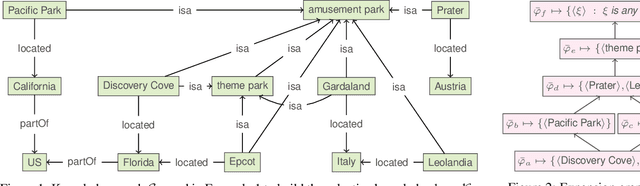
Recognizing similarities among entities is central to both human cognition and computational intelligence. Within this broader landscape, Entity Set Expansion is one prominent task aimed at taking an initial set of (tuples of) entities and identifying additional ones that share relevant semantic properties with the former -- potentially repeating the process to form increasingly broader sets. However, this ``linear'' approach does not unveil the richer ``taxonomic'' structures present in knowledge resources. A recent logic-based framework introduces the notion of an expansion graph: a rooted directed acyclic graph where each node represents a semantic generalization labeled by a logical formula, and edges encode strict semantic inclusion. This structure supports taxonomic expansions of entity sets driven by knowledge bases. Yet, the potentially large size of such graphs may make full materialization impractical in real-world scenarios. To overcome this, we formalize reasoning tasks that check whether two tuples belong to comparable, incomparable, or the same nodes in the graph. Our results show that, under realistic assumptions -- such as bounding the input or limiting entity descriptions -- these tasks can be implemented efficiently. This enables local, incremental navigation of expansion graphs, supporting practical applications without requiring full graph construction.
Characterizing Nexus of Similarity within Knowledge Bases: A Logic-based Framework and its Computational Complexity Aspects
Mar 19, 2023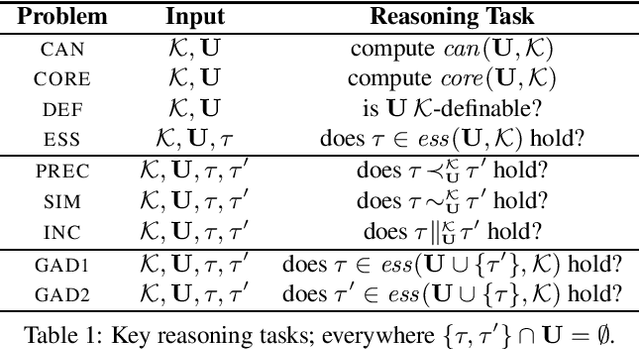
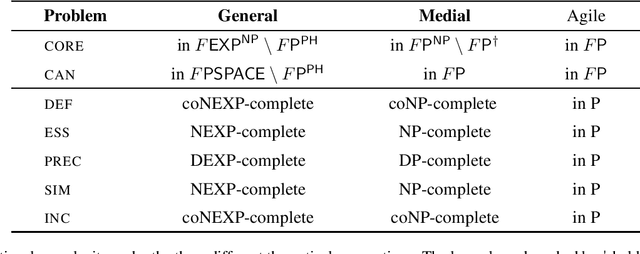

Similarities between entities occur frequently in many real-world scenarios. For over a century, researchers in different fields have proposed a range of approaches to measure the similarity between entities. More recently, inspired by "Google Sets", significant academic and commercial efforts have been devoted to expanding a given set of entities with similar ones. As a result, existing approaches nowadays are able to take into account properties shared by entities, hereinafter called nexus of similarity. Accordingly, machines are largely able to deal with both similarity measures and set expansions. To the best of our knowledge, however, there is no way to characterize nexus of similarity between entities, namely identifying such nexus in a formal and comprehensive way so that they are both machine- and human-readable; moreover, there is a lack of consensus on evaluating existing approaches for weakly similar entities. As a first step towards filling these gaps, we aim to complement existing literature by developing a novel logic-based framework to formally and automatically characterize nexus of similarity between tuples of entities within a knowledge base. Furthermore, we analyze computational complexity aspects of this framework.
A Formal Comparison between Datalog-based Languages for Stream Reasoning (extended version)
Aug 26, 2022
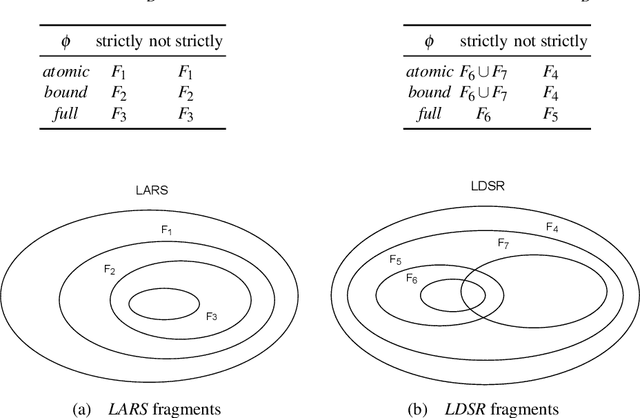
The paper investigates the relative expressiveness of two logic-based languages for reasoning over streams, namely LARS Programs -- the language of the Logic-based framework for Analytic Reasoning over Streams called LARS -- and LDSR -- the language of the recent extension of the I-DLV system for stream reasoning called I-DLV-sr. Although these two languages build over Datalog, they do differ both in syntax and semantics. To reconcile their expressive capabilities for stream reasoning, we define a comparison framework that allows us to show that, without any restrictions, the two languages are incomparable and to identify fragments of each language that can be expressed via the other one.
I-DLV-sr: A Stream Reasoning System based on I-DLV
Aug 05, 2021
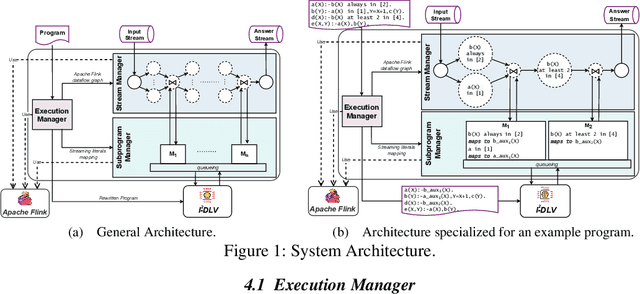
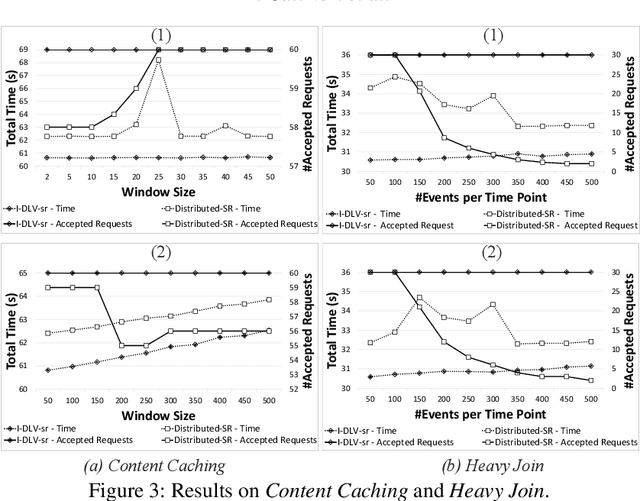
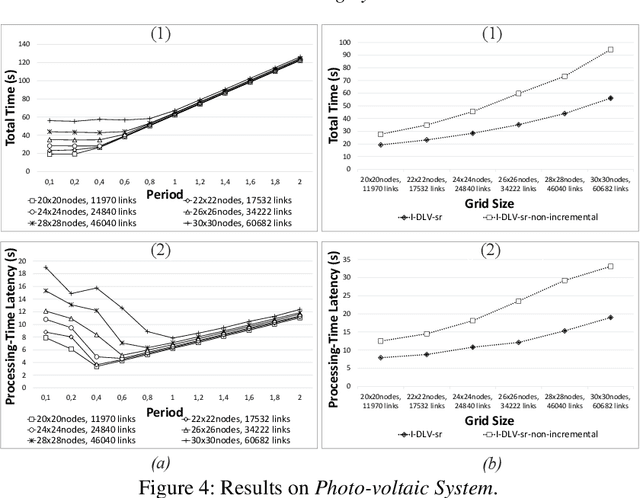
We introduce a novel logic-based system for reasoning over data streams, which relies on a framework enabling a tight, fine-tuned interaction between Apache Flink and the I^2-DLV system. The architecture allows to take advantage from both the powerful distributed stream processing capabilities of Flink and the incremental reasoning capabilities of I^2-DLV based on overgrounding techniques. Besides the system architecture, we illustrate the supported input language and its modeling capabilities, and discuss the results of an experimental activity aimed at assessing the viability of the approach. This paper is under consideration in Theory and Practice of Logic Programming (TPLP).
A logic-based decision support system for the diagnosis of headache disorders according to the ICHD-3 international classification
Aug 06, 2020

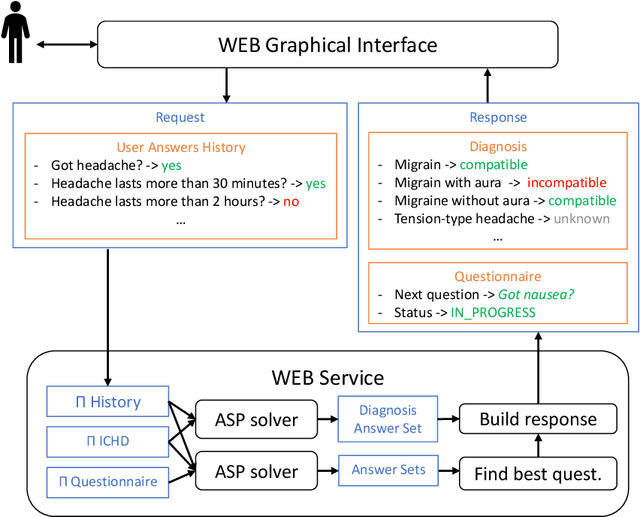
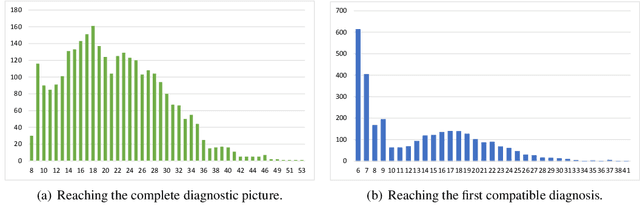
Decision support systems play an important role in medical fields as they can augment clinicians to deal more efficiently and effectively with complex decision-making processes. In the diagnosis of headache disorders, however, existing approaches and tools are still not optimal. On the one hand, to support the diagnosis of this complex and vast spectrum of disorders, the International Headache Society released in 1988 the International Classification of Headache Disorders (ICHD), now in its 3rd edition: a 200 pages document classifying more than 300 different kinds of headaches, where each is identified via a collection of specific nontrivial diagnostic criteria. On the other hand, the high number of headache disorders and their complex criteria make the medical history process inaccurate and not exhaustive both for clinicians and existing automatic tools. To fill this gap, we present HEAD-ASP, a novel decision support system for the diagnosis of headache disorders. Through a REST Web Service, HEAD-ASP implements a dynamic questionnaire that complies with ICHD-3 by exploiting two logical modules to reach a complete diagnosis while trying to minimize the total number of questions being posed to patients. Finally, HEAD-ASP is freely available on-line and it is receiving very positive feedback from the group of neurologists that is testing it.
DaRLing: A Datalog rewriter for OWL 2 RL ontological reasoning under SPARQL queries
Aug 05, 2020The W3C Web Ontology Language (OWL) is a powerful knowledge representation formalism at the basis of many semantic-centric applications. Since its unrestricted usage makes reasoning undecidable already in case of very simple tasks, expressive yet decidable fragments have been identified. Among them, we focus on OWL 2 RL, which offers a rich variety of semantic constructors, apart from supporting all RDFS datatypes. Although popular Web resources - such as DBpedia - fall in OWL 2 RL, only a few systems have been designed and implemented for this fragment. None of them, however, fully satisfy all the following desiderata: (i) being freely available and regularly maintained; (ii) supporting query answering and SPARQL queries; (iii) properly applying the sameAs property without adopting the unique name assumption; (iv) dealing with concrete datatypes. To fill the gap, we present DaRLing, a freely available Datalog rewriter for OWL 2 RL ontological reasoning under SPARQL queries. In particular, we describe its architecture, the rewriting strategies it implements, and the result of an experimental evaluation that demonstrates its practical applicability. This paper is under consideration in Theory and Practice of Logic Programming (TPLP).
Large-scale Ontological Reasoning via Datalog
Mar 21, 2020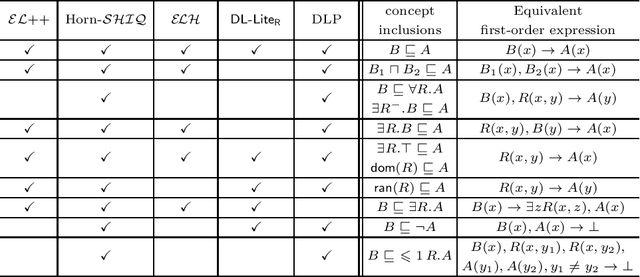

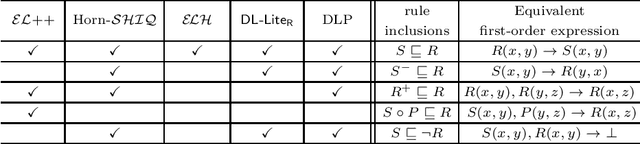
Reasoning over OWL 2 is a very expensive task in general, and therefore the W3C identified tractable profiles exhibiting good computational properties. Ontological reasoning for many fragments of OWL 2 can be reduced to the evaluation of Datalog queries. This paper surveys some of these compilations, and in particular the one addressing queries over Horn-$\mathcal{SHIQ}$ knowledge bases and its implementation in DLV2 enanched by a new version of the Magic Sets algorithm.
Precomputing Datalog evaluation plans in large-scale scenarios
Jul 29, 2019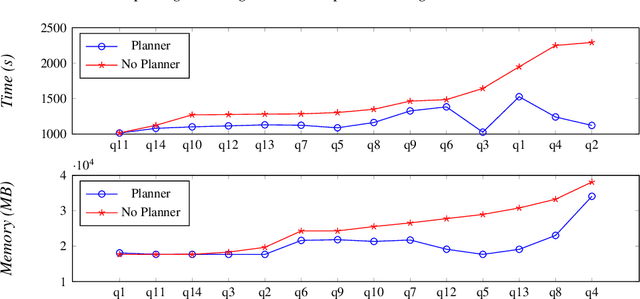
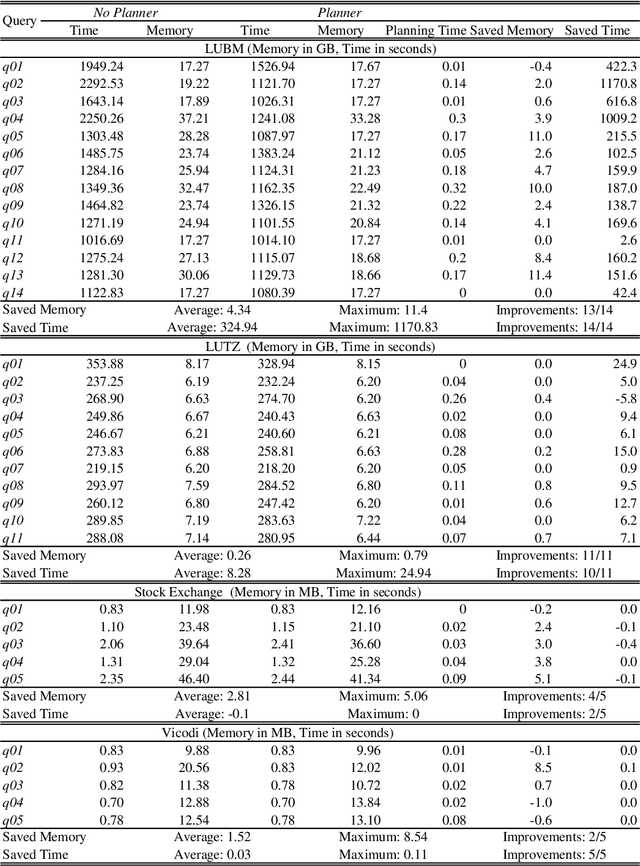
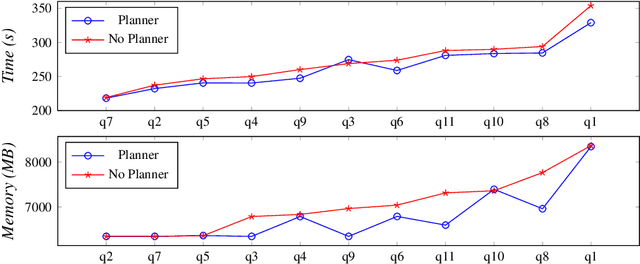
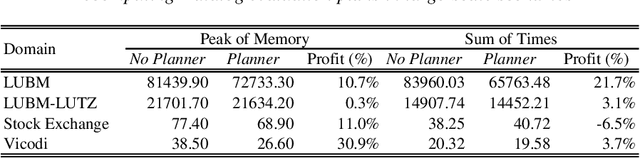
With the more and more growing demand for semantic Web services over large databases, an efficient evaluation of Datalog queries is arousing a renewed interest among researchers and industry experts. In this scenario, to reduce memory consumption and possibly optimize execution times, the paper proposes novel techniques to determine an optimal indexing schema for the underlying database together with suitable body-orderings for the Datalog rules. The new approach is compared with the standard execution plans implemented in DLV over widely used ontological benchmarks. The results confirm that the memory usage can be significantly reduced without paying any cost in efficiency. This paper is under consideration in Theory and Practice of Logic Programming (TPLP).
Ontology-driven Information Extraction
Dec 18, 2015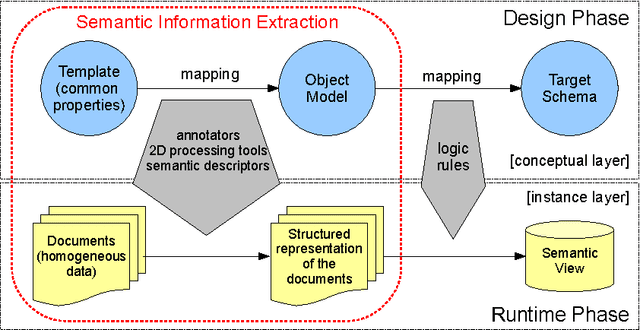
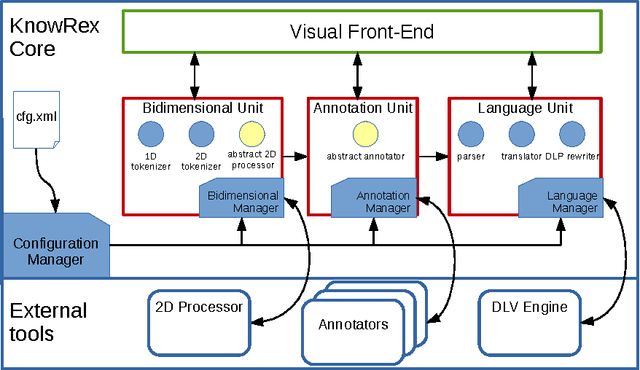

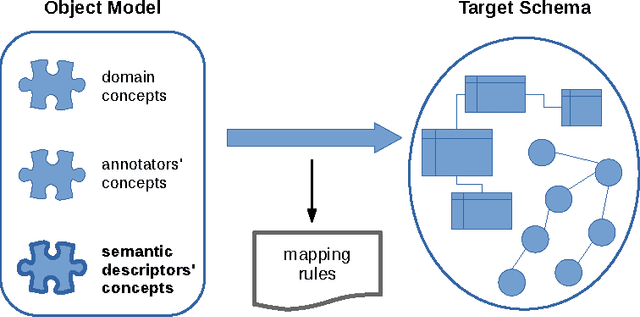
Homogeneous unstructured data (HUD) are collections of unstructured documents that share common properties, such as similar layout, common file format, or common domain of values. Building on such properties, it would be desirable to automatically process HUD to access the main information through a semantic layer -- typically an ontology -- called semantic view. Hence, we propose an ontology-based approach for extracting semantically rich information from HUD, by integrating and extending recent technologies and results from the fields of classical information extraction, table recognition, ontologies, text annotation, and logic programming. Moreover, we design and implement a system, named KnowRex, that has been successfully applied to curriculum vitae in the Europass style to offer a semantic view of them, and be able, for example, to select those which exhibit required skills.
Taming Primary Key Violations to Query Large Inconsistent Data
Jul 22, 2015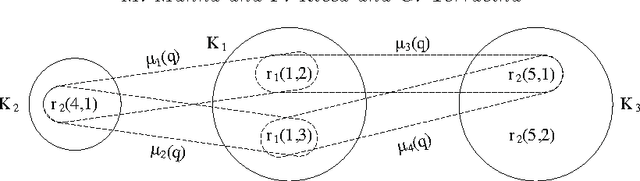
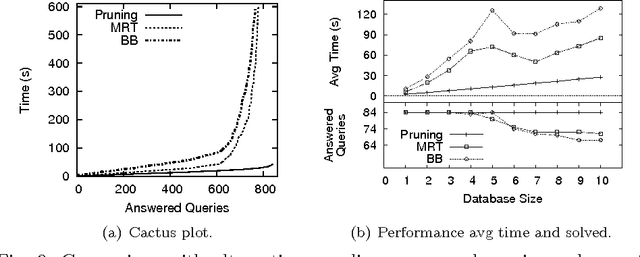
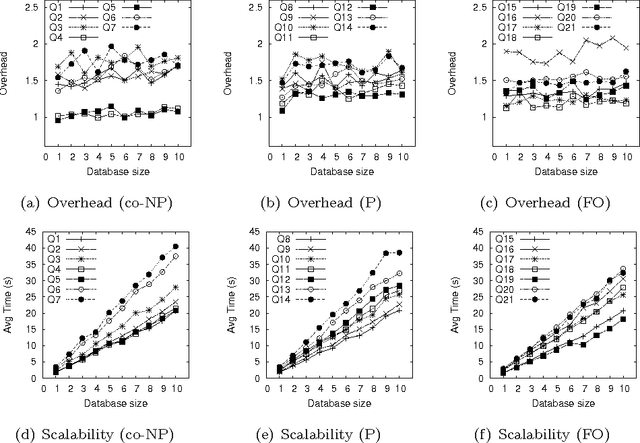
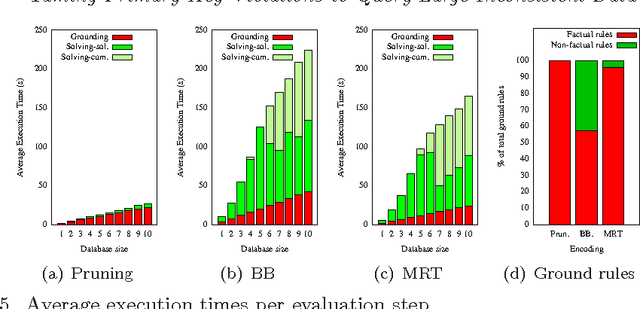
Consistent query answering over a database that violates primary key constraints is a classical hard problem in database research that has been traditionally dealt with logic programming. However, the applicability of existing logic-based solutions is restricted to data sets of moderate size. This paper presents a novel decomposition and pruning strategy that reduces, in polynomial time, the problem of computing the consistent answer to a conjunctive query over a database subject to primary key constraints to a collection of smaller problems of the same sort that can be solved independently. The new strategy is naturally modeled and implemented using Answer Set Programming (ASP). An experiment run on benchmarks from the database world prove the effectiveness and efficiency of our ASP-based approach also on large data sets. To appear in Theory and Practice of Logic Programming (TPLP), Proceedings of ICLP 2015.